Seeing Through the Mask: Rethinking Adversarial Examples for CAPTCHAs

0

Sign in to get full access
Overview
- This paper explores the vulnerability of CAPTCHAs (Completely Automated Public Turing test to tell Computers and Humans Apart) to adversarial attacks.
- The researchers propose a new attack method called "Seeing Through the Mask" that can bypass state-of-the-art CAPTCHA systems.
- They demonstrate the effectiveness of their approach on various CAPTCHA datasets, highlighting the need for more robust CAPTCHA design.
Plain English Explanation
The paper discusses a technique called "Seeing Through the Mask" that can <a href="https://aimodels.fyi/papers/arxiv/seeing-through-mask-rethinking-adversarial-examples-captchas">bypass CAPTCHA challenges</a>. CAPTCHAs are tests that try to distinguish between humans and machines, often by presenting distorted or obscured text that humans can read but machines struggle with.
The researchers found that by using a special type of "adversarial attack," they could trick CAPTCHA systems into thinking a machine-generated image was a human-generated one. This attack works by making small, imperceptible changes to the CAPTCHA image that confuse the CAPTCHA's recognition system, allowing the machine to pass the test.
The key insight is that the CAPTCHA systems are not as robust as they may seem. Even state-of-the-art CAPTCHAs can be fooled by these adversarial attacks. This highlights the need for designers of CAPTCHAs to rethink their approach and develop more <a href="https://aimodels.fyi/papers/arxiv/rethinking-threat-accessibility-adversarial-attacks-against-face">secure and resilient systems</a>.
Technical Explanation
The paper presents a novel attack method called "Seeing Through the Mask" that can bypass state-of-the-art CAPTCHA systems. The researchers leverage the concept of <a href="https://aimodels.fyi/papers/arxiv/imperceptible-face-forgery-attack-via-adversarial-semantic">adversarial examples</a> to generate imperceptible perturbations that can fool CAPTCHA recognition models.
The attack process involves the following steps:
- Obtaining a CAPTCHA image
- Generating an adversarial example by applying small, carefully crafted perturbations to the CAPTCHA image
- Passing the adversarial example through the CAPTCHA recognition model, which incorrectly identifies it as a valid CAPTCHA
The researchers evaluate their "Seeing Through the Mask" approach on various CAPTCHA datasets and demonstrate its effectiveness in bypassing state-of-the-art CAPTCHA systems. They also provide insights into the underlying vulnerabilities of CAPTCHA design and the need for more <a href="https://aimodels.fyi/papers/arxiv/adversarial-examples-generation-proposal-context-facial-recognition">robust defense mechanisms</a>.
Critical Analysis
The paper highlights a significant vulnerability in CAPTCHA systems, which are widely used to distinguish between humans and machines. The "Seeing Through the Mask" attack demonstrates the limitations of current CAPTCHA designs and their susceptibility to adversarial attacks.
While the proposed attack method is effective, the paper acknowledges that it requires some prior knowledge about the target CAPTCHA system, such as the recognition model architecture. Additionally, the attack may not work as effectively on CAPTCHAs that employ more advanced techniques, such as <a href="https://aimodels.fyi/papers/arxiv/aemim-adversarial-examples-meet-masked-image-modeling">masked image modeling</a>.
Further research is needed to develop more robust CAPTCHA systems that can withstand a wide range of adversarial attacks. Potential defense strategies could include incorporating machine learning techniques that are more resilient to adversarial examples, or exploring alternative CAPTCHA designs that do not rely solely on text recognition.
Conclusion
The "Seeing Through the Mask" attack exposes a critical vulnerability in CAPTCHA systems, challenging the assumption that they provide an effective barrier between humans and machines. The findings of this paper highlight the need for a rethinking of CAPTCHA design and the development of more secure and resilient systems to protect against evolving threats.
As AI and machine learning technologies continue to advance, the security and reliability of CAPTCHA systems will become increasingly important. The insights gained from this research can inform the design of next-generation CAPTCHA challenges, ensuring that they remain an effective tool for distinguishing between human and machine interactions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Seeing Through the Mask: Rethinking Adversarial Examples for CAPTCHAs
Yahya Jabary, Andreas Plesner, Turlan Kuzhagaliyev, Roger Wattenhofer
Modern CAPTCHAs rely heavily on vision tasks that are supposedly hard for computers but easy for humans. However, advances in image recognition models pose a significant threat to such CAPTCHAs. These models can easily be fooled by generating some well-hidden random noise and adding it to the image, or hiding objects in the image. However, these methods are model-specific and thus can not aid CAPTCHAs in fooling all models. We show in this work that by allowing for more significant changes to the images while preserving the semantic information and keeping it solvable by humans, we can fool many state-of-the-art models. Specifically, we demonstrate that by adding masks of various intensities the Accuracy @ 1 (Acc@1) drops by more than 50%-points for all models, and supposedly robust models such as vision transformers see an Acc@1 drop of 80%-points. These masks can therefore effectively fool modern image classifiers, thus showing that machines have not caught up with humans -- yet.
Read more9/10/2024
2
New!Breaking reCAPTCHAv2
Andreas Plesner, Tobias Vontobel, Roger Wattenhofer
Our work examines the efficacy of employing advanced machine learning methods to solve captchas from Google's reCAPTCHAv2 system. We evaluate the effectiveness of automated systems in solving captchas by utilizing advanced YOLO models for image segmentation and classification. Our main result is that we can solve 100% of the captchas, while previous work only solved 68-71%. Furthermore, our findings suggest that there is no significant difference in the number of challenges humans and bots must solve to pass the captchas in reCAPTCHAv2. This implies that current AI technologies can exploit advanced image-based captchas. We also look under the hood of reCAPTCHAv2, and find evidence that reCAPTCHAv2 is heavily based on cookie and browser history data when evaluating whether a user is human or not. The code is provided alongside this paper.
Read more9/16/2024

0
Rethinking the Threat and Accessibility of Adversarial Attacks against Face Recognition Systems
Yuxin Cao, Yumeng Zhu, Derui Wang, Sheng Wen, Minhui Xue, Jin Lu, Hao Ge
Face recognition pipelines have been widely deployed in various mission-critical systems in trust, equitable and responsible AI applications. However, the emergence of adversarial attacks has threatened the security of the entire recognition pipeline. Despite the sheer number of attack methods proposed for crafting adversarial examples in both digital and physical forms, it is never an easy task to assess the real threat level of different attacks and obtain useful insight into the key risks confronted by face recognition systems. Traditional attacks view imperceptibility as the most important measurement to keep perturbations stealthy, while we suspect that industry professionals may possess a different opinion. In this paper, we delve into measuring the threat brought about by adversarial attacks from the perspectives of the industry and the applications of face recognition. In contrast to widely studied sophisticated attacks in the field, we propose an effective yet easy-to-launch physical adversarial attack, named AdvColor, against black-box face recognition pipelines in the physical world. AdvColor fools models in the recognition pipeline via directly supplying printed photos of human faces to the system under adversarial illuminations. Experimental results show that physical AdvColor examples can achieve a fooling rate of more than 96% against the anti-spoofing model and an overall attack success rate of 88% against the face recognition pipeline. We also conduct a survey on the threats of prevailing adversarial attacks, including AdvColor, to understand the gap between the machine-measured and human-assessed threat levels of different forms of adversarial attacks. The survey results surprisingly indicate that, compared to deliberately launched imperceptible attacks, perceptible but accessible attacks pose more lethal threats to real-world commercial systems of face recognition.
Read more7/12/2024
0
Imperceptible Face Forgery Attack via Adversarial Semantic Mask
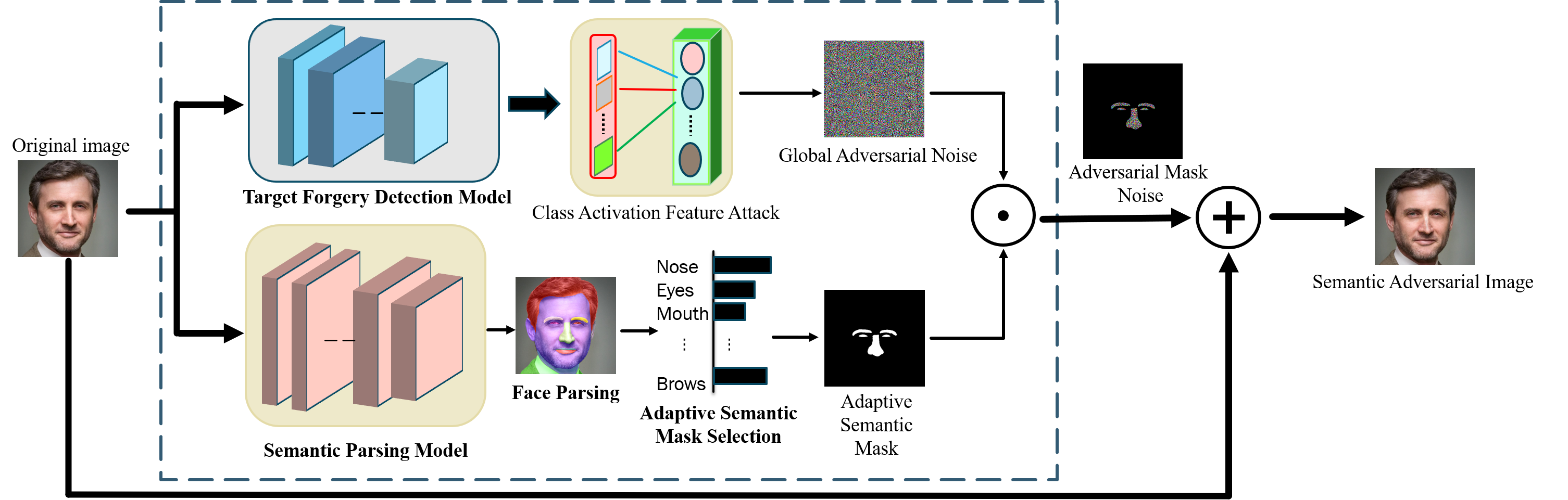
Decheng Liu, Qixuan Su, Chunlei Peng, Nannan Wang, Xinbo Gao
With the great development of generative model techniques, face forgery detection draws more and more attention in the related field. Researchers find that existing face forgery models are still vulnerable to adversarial examples with generated pixel perturbations in the global image. These generated adversarial samples still can't achieve satisfactory performance because of the high detectability. To address these problems, we propose an Adversarial Semantic Mask Attack framework (ASMA) which can generate adversarial examples with good transferability and invisibility. Specifically, we propose a novel adversarial semantic mask generative model, which can constrain generated perturbations in local semantic regions for good stealthiness. The designed adaptive semantic mask selection strategy can effectively leverage the class activation values of different semantic regions, and further ensure better attack transferability and stealthiness. Extensive experiments on the public face forgery dataset prove the proposed method achieves superior performance compared with several representative adversarial attack methods. The code is publicly available at https://github.com/clawerO-O/ASMA.
Read more6/18/2024