SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentation
2404.10156
0
0
Abstract
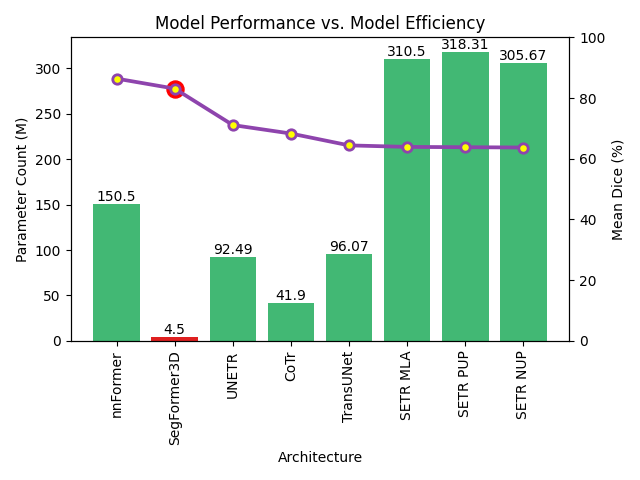
The adoption of Vision Transformers (ViTs) based architectures represents a significant advancement in 3D Medical Image (MI) segmentation, surpassing traditional Convolutional Neural Network (CNN) models by enhancing global contextual understanding. While this paradigm shift has significantly enhanced 3D segmentation performance, state-of-the-art architectures require extremely large and complex architectures with large scale computing resources for training and deployment. Furthermore, in the context of limited datasets, often encountered in medical imaging, larger models can present hurdles in both model generalization and convergence. In response to these challenges and to demonstrate that lightweight models are a valuable area of research in 3D medical imaging, we present SegFormer3D, a hierarchical Transformer that calculates attention across multiscale volumetric features. Additionally, SegFormer3D avoids complex decoders and uses an all-MLP decoder to aggregate local and global attention features to produce highly accurate segmentation masks. The proposed memory efficient Transformer preserves the performance characteristics of a significantly larger model in a compact design. SegFormer3D democratizes deep learning for 3D medical image segmentation by offering a model with 33x less parameters and a 13x reduction in GFLOPS compared to the current state-of-the-art (SOTA). We benchmark SegFormer3D against the current SOTA models on three widely used datasets Synapse, BRaTs, and ACDC, achieving competitive results. Code: https://github.com/OSUPCVLab/SegFormer3D.git
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Introduces an efficient 3D Transformer-based model for medical image segmentation called SegFormer3D
- Leverages the hierarchical feature representation and efficient self-attention mechanism of Transformers
- Aims to achieve high performance while being computationally efficient
Plain English Explanation
SegFormer3D is a new deep learning model designed for the task of 3D medical image segmentation. It is based on the Transformer architecture, which has shown great success in various computer vision tasks. The key innovation of SegFormer3D is that it can efficiently process 3D medical images, like CT or MRI scans, and accurately segment different anatomical structures within them.
Traditional 3D segmentation models can be computationally intensive, making them challenging to deploy in real-world clinical settings. SegFormer3D addresses this by using a Transformer-based design that is more efficient, without sacrificing segmentation accuracy. The model is able to learn a hierarchical representation of the 3D image data, capturing both local and global features important for segmentation.
By leveraging the strengths of Transformers, SegFormer3D aims to provide a powerful yet efficient solution for 3D medical image analysis, with potential applications in disease diagnosis, treatment planning, and other healthcare domains. This could help improve the speed and accuracy of medical image interpretation, ultimately benefiting patient care.
Technical Explanation
SegFormer3D builds upon the success of the SegFormer architecture, which introduced an efficient Transformer-based model for 2D image segmentation. The key idea behind SegFormer3D is to extend this approach to 3D medical imaging data, while preserving the computational efficiency.
The model consists of a Transformer encoder that processes the 3D input image and generates a hierarchical feature representation. This is followed by a segmentation head that leverages these features to produce the final segmentation map. The Transformer encoder uses a novel "mixed-query" attention mechanism that allows it to efficiently capture both local and global dependencies in the 3D data.
To further improve efficiency, SegFormer3D employs a progressive downsampling strategy, where the input image is gradually reduced in resolution as it passes through the network. This reduces the computational burden, particularly in the deeper layers of the model.
The authors evaluate SegFormer3D on several 3D medical image segmentation benchmarks, including tasks for brain, heart, and prostate segmentation. The results demonstrate that SegFormer3D achieves state-of-the-art performance while being significantly more efficient than previous 3D segmentation models, such as MaxViT-UNet and Revenge-BiseNet.
Critical Analysis
The authors of SegFormer3D have made a compelling case for the effectiveness of their Transformer-based approach to 3D medical image segmentation. By leveraging the strengths of Transformers, they have been able to develop a model that achieves state-of-the-art performance while being more computationally efficient than previous methods.
One potential limitation of the study is that the evaluation was conducted on a relatively small number of datasets, and it would be valuable to see how SegFormer3D performs on a wider range of 3D medical imaging tasks and datasets. Additionally, the authors did not provide detailed comparisons of the inference time and memory usage of SegFormer3D compared to other models, which would be helpful in fully assessing its efficiency.
Furthermore, while the authors mention potential applications in disease diagnosis and treatment planning, they did not explore the clinical implications of their work in depth. It would be valuable to see further research on the real-world impact of SegFormer3D and how it could be integrated into clinical workflows.
Overall, the SegFormer3D model presents an exciting advancement in the field of 3D medical image segmentation, and the authors have demonstrated the potential of Transformer-based architectures in this domain. As the research in this area continues to evolve, it will be interesting to see how SegFormer3D and similar models are further developed and deployed in healthcare settings.
Conclusion
SegFormer3D is a novel 3D Transformer-based model for medical image segmentation that aims to achieve high performance while being computationally efficient. By leveraging the hierarchical feature representation and efficient self-attention mechanism of Transformers, the model is able to accurately segment different anatomical structures in 3D medical images, such as CT or MRI scans.
The key innovation of SegFormer3D is its ability to process 3D data efficiently, making it a promising candidate for real-world clinical applications. The authors have demonstrated state-of-the-art results on several 3D medical image segmentation benchmarks, highlighting the potential of this approach to contribute to advancements in disease diagnosis, treatment planning, and other healthcare domains.
As the field of medical image analysis continues to evolve, models like SegFormer3D that combine the power of deep learning with the efficiency of Transformer architectures could play an important role in enhancing the speed and accuracy of medical image interpretation, ultimately benefiting patient care and outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
UNETR++: Delving into Efficient and Accurate 3D Medical Image Segmentation
Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan
0
0
Owing to the success of transformer models, recent works study their applicability in 3D medical segmentation tasks. Within the transformer models, the self-attention mechanism is one of the main building blocks that strives to capture long-range dependencies. However, the self-attention operation has quadratic complexity which proves to be a computational bottleneck, especially in volumetric medical imaging, where the inputs are 3D with numerous slices. In this paper, we propose a 3D medical image segmentation approach, named UNETR++, that offers both high-quality segmentation masks as well as efficiency in terms of parameters, compute cost, and inference speed. The core of our design is the introduction of a novel efficient paired attention (EPA) block that efficiently learns spatial and channel-wise discriminative features using a pair of inter-dependent branches based on spatial and channel attention. Our spatial attention formulation is efficient having linear complexity with respect to the input sequence length. To enable communication between spatial and channel-focused branches, we share the weights of query and key mapping functions that provide a complimentary benefit (paired attention), while also reducing the overall network parameters. Our extensive evaluations on five benchmarks, Synapse, BTCV, ACDC, BRaTs, and Decathlon-Lung, reveal the effectiveness of our contributions in terms of both efficiency and accuracy. On Synapse, our UNETR++ sets a new state-of-the-art with a Dice Score of 87.2%, while being significantly efficient with a reduction of over 71% in terms of both parameters and FLOPs, compared to the best method in the literature. Code: https://github.com/Amshaker/unetr_plus_plus.
5/7/2024

ViewFormer: Exploring Spatiotemporal Modeling for Multi-View 3D Occupancy Perception via View-Guided Transformers
Jinke Li, Xiao He, Chonghua Zhou, Xiaoqiang Cheng, Yang Wen, Dan Zhang
0
0
3D occupancy, an advanced perception technology for driving scenarios, represents the entire scene without distinguishing between foreground and background by quantifying the physical space into a grid map. The widely adopted projection-first deformable attention, efficient in transforming image features into 3D representations, encounters challenges in aggregating multi-view features due to sensor deployment constraints. To address this issue, we propose our learning-first view attention mechanism for effective multi-view feature aggregation. Moreover, we showcase the scalability of our view attention across diverse multi-view 3D tasks, such as map construction and 3D object detection. Leveraging the proposed view attention as well as an additional multi-frame streaming temporal attention, we introduce ViewFormer, a vision-centric transformer-based framework for spatiotemporal feature aggregation. To further explore occupancy-level flow representation, we present FlowOcc3D, a benchmark built on top of existing high-quality datasets. Qualitative and quantitative analyses on this benchmark reveal the potential to represent fine-grained dynamic scenes. Extensive experiments show that our approach significantly outperforms prior state-of-the-art methods. The codes and benchmark will be released soon.
5/8/2024
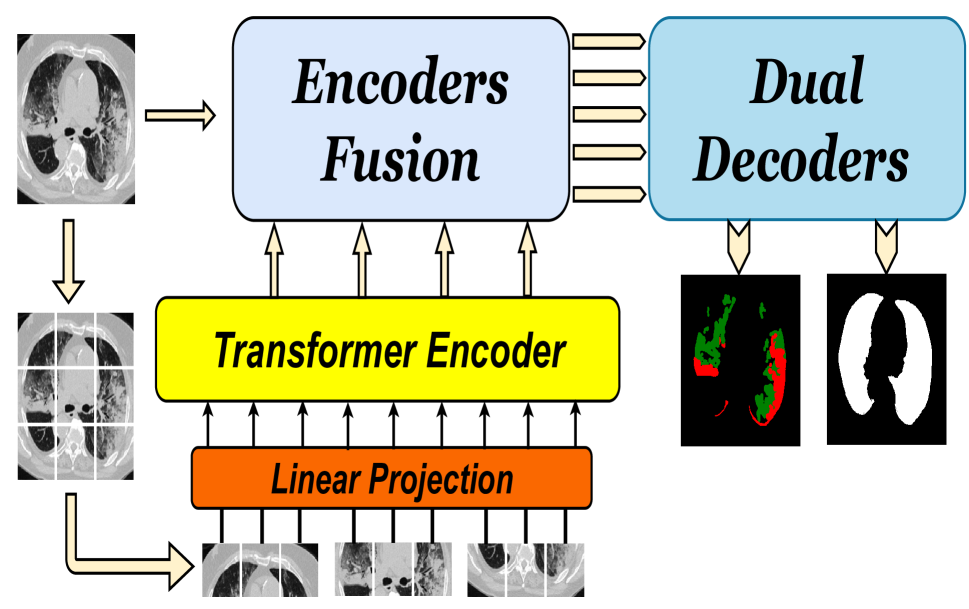
D-TrAttUnet: Toward Hybrid CNN-Transformer Architecture for Generic and Subtle Segmentation in Medical Images
Fares Bougourzi, Fadi Dornaika, Cosimo Distante, Abdelmalik Taleb-Ahmed
0
0
Over the past two decades, machine analysis of medical imaging has advanced rapidly, opening up significant potential for several important medical applications. As complicated diseases increase and the number of cases rises, the role of machine-based imaging analysis has become indispensable. It serves as both a tool and an assistant to medical experts, providing valuable insights and guidance. A particularly challenging task in this area is lesion segmentation, a task that is challenging even for experienced radiologists. The complexity of this task highlights the urgent need for robust machine learning approaches to support medical staff. In response, we present our novel solution: the D-TrAttUnet architecture. This framework is based on the observation that different diseases often target specific organs. Our architecture includes an encoder-decoder structure with a composite Transformer-CNN encoder and dual decoders. The encoder includes two paths: the Transformer path and the Encoders Fusion Module path. The Dual-Decoder configuration uses two identical decoders, each with attention gates. This allows the model to simultaneously segment lesions and organs and integrate their segmentation losses. To validate our approach, we performed evaluations on the Covid-19 and Bone Metastasis segmentation tasks. We also investigated the adaptability of the model by testing it without the second decoder in the segmentation of glands and nuclei. The results confirmed the superiority of our approach, especially in Covid-19 infections and the segmentation of bone metastases. In addition, the hybrid encoder showed exceptional performance in the segmentation of glands and nuclei, solidifying its role in modern medical image analysis.
5/8/2024
⚙️
Rethinking Attention Gated with Hybrid Dual Pyramid Transformer-CNN for Generalized Segmentation in Medical Imaging
Fares Bougourzi, Fadi Dornaika, Abdelmalik Taleb-Ahmed, Vinh Truong Hoang
0
0
Inspired by the success of Transformers in Computer vision, Transformers have been widely investigated for medical imaging segmentation. However, most of Transformer architecture are using the recent transformer architectures as encoder or as parallel encoder with the CNN encoder. In this paper, we introduce a novel hybrid CNN-Transformer segmentation architecture (PAG-TransYnet) designed for efficiently building a strong CNN-Transformer encoder. Our approach exploits attention gates within a Dual Pyramid hybrid encoder. The contributions of this methodology can be summarized into three key aspects: (i) the utilization of Pyramid input for highlighting the prominent features at different scales, (ii) the incorporation of a PVT transformer to capture long-range dependencies across various resolutions, and (iii) the implementation of a Dual-Attention Gate mechanism for effectively fusing prominent features from both CNN and Transformer branches. Through comprehensive evaluation across different segmentation tasks including: abdominal multi-organs segmentation, infection segmentation (Covid-19 and Bone Metastasis), microscopic tissues segmentation (Gland and Nucleus). The proposed approach demonstrates state-of-the-art performance and exhibits remarkable generalization capabilities. This research represents a significant advancement towards addressing the pressing need for efficient and adaptable segmentation solutions in medical imaging applications.
4/30/2024