Segment-Based Interactive Machine Translation for Pre-trained Models

0
🧠
Sign in to get full access
Overview
- This paper introduces a new approach to interactive machine translation (MT) called Segment-Based Interactive Machine Translation (SB-IMT) for pre-trained language models.
- SB-IMT allows users to interactively edit and refine machine translations by providing feedback on individual segments of the output.
- The authors demonstrate that SB-IMT can significantly improve translation quality compared to traditional MT systems, especially for low-resource language pairs.
Plain English Explanation
The paper proposes a new way to interact with machine translation (MT) systems that can help improve the quality of translations, especially for language pairs where high-quality MT is hard to achieve. Traditional MT systems produce a full translation of a text all at once, but with SB-IMT, users can provide feedback on individual segments of the translation. The system then uses that feedback to refine the translation, making it better over time. This interactive approach leverages the strengths of pre-trained language models to adapt the translation to the user's preferences and needs. The authors show that SB-IMT can lead to substantial improvements in translation quality compared to standard MT, particularly for language pairs that are difficult to translate well automatically.
Technical Explanation
The paper introduces Segment-Based Interactive Machine Translation (SB-IMT), a novel interactive MT framework that allows users to provide feedback on individual segments of a translated text. This feedback is then used to fine-tune the underlying pre-trained language model, enabling the system to iteratively improve the translation.
The authors propose a specific SB-IMT architecture that consists of a pre-trained multilingual language model, a segment-level translation module, and a feedback integration module. The segment-level translation module breaks the input text into smaller segments and generates initial translations for each. Users can then provide feedback on these segments, which is used by the feedback integration module to update the language model's parameters and generate an improved translation.
The authors evaluate their SB-IMT approach on several language pairs and show that it significantly outperforms both standard simultaneous MT and zero-shot context-aware simultaneous MT baselines, especially for low-resource language pairs. They also demonstrate how SB-IMT can be combined with cascaded speech translation systems to further enhance translation quality.
Critical Analysis
The paper presents a compelling approach to interactive machine translation that leverages the strengths of pre-trained language models. By allowing users to provide feedback on individual translation segments, the system can iteratively refine the output to better meet the user's needs and preferences.
One potential limitation of the SB-IMT approach is the cognitive load it places on users, who must review and provide feedback on each segment of the translation. The authors acknowledge this challenge and suggest exploring ways to streamline the feedback process, such as automated segment selection or summary-based feedback.
Additionally, the paper does not delve deeply into the impact of the underlying pre-trained language model on SB-IMT performance. It would be interesting to see how different language model architectures and training strategies affect the system's capabilities.
Overall, the SB-IMT framework represents a promising step forward in interactive machine translation, with the potential to significantly improve translation quality, especially for low-resource language pairs. Further research into optimizing the user experience and exploring the role of language model design could help unlock the full potential of this approach.
Conclusion
The Segment-Based Interactive Machine Translation (SB-IMT) framework proposed in this paper offers a novel approach to interactive machine translation that leverages the capabilities of pre-trained language models. By allowing users to provide feedback on individual translation segments, the system can iteratively refine the output to better meet their needs.
The authors demonstrate that SB-IMT can lead to substantial improvements in translation quality, particularly for language pairs that are challenging for standard machine translation systems. This approach has the potential to significantly enhance the accessibility and usefulness of machine translation, especially in scenarios where high-quality translation is critical.
As the field of natural language processing continues to advance, innovative interaction models like SB-IMT will be crucial for unlocking the full potential of machine translation and other language technologies. Further research into optimizing the user experience and exploring the role of language model design could help drive the next generation of interactive, adaptive, and user-centric language AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Segment-Based Interactive Machine Translation for Pre-trained Models
Angel Navarro, Francisco Casacuberta
Pre-trained large language models (LLM) are starting to be widely used in many applications. In this work, we explore the use of these models in interactive machine translation (IMT) environments. In particular, we have chosen mBART (multilingual Bidirectional and Auto-Regressive Transformer) and mT5 (multilingual Text-to-Text Transfer Transformer) as the LLMs to perform our experiments. The system generates perfect translations interactively using the feedback provided by the user at each iteration. The Neural Machine Translation (NMT) model generates a preliminary hypothesis with the feedback, and the user validates new correct segments and performs a word correction--repeating the process until the sentence is correctly translated. We compared the performance of mBART, mT5, and a state-of-the-art (SoTA) machine translation model on a benchmark dataset regarding user effort, Word Stroke Ratio (WSR), Key Stroke Ratio (KSR), and Mouse Action Ratio (MAR). The experimental results indicate that mBART performed comparably with SoTA models, suggesting that it is a viable option for this field of IMT. The implications of this finding extend to the development of new machine translation models for interactive environments, as it indicates that some novel pre-trained models exhibit SoTA performance in this domain, highlighting the potential benefits of adapting these models to specific needs.
Read more7/10/2024
💬
0
Empirical study of pretrained multilingual language models for zero-shot cross-lingual knowledge transfer in generation
Nadezhda Chirkova, Sheng Liang, Vassilina Nikoulina
Zero-shot cross-lingual knowledge transfer enables the multilingual pretrained language model (mPLM), finetuned on a task in one language, make predictions for this task in other languages. While being broadly studied for natural language understanding tasks, the described setting is understudied for generation. Previous works notice a frequent problem of generation in a wrong language and propose approaches to address it, usually using mT5 as a backbone model. In this work, we test alternative mPLMs, such as mBART and NLLB-200, considering full finetuning and parameter-efficient finetuning with adapters. We find that mBART with adapters performs similarly to mT5 of the same size, and NLLB-200 can be competitive in some cases. We also underline the importance of tuning learning rate used for finetuning, which helps to alleviate the problem of generation in the wrong language.
Read more4/23/2024
0
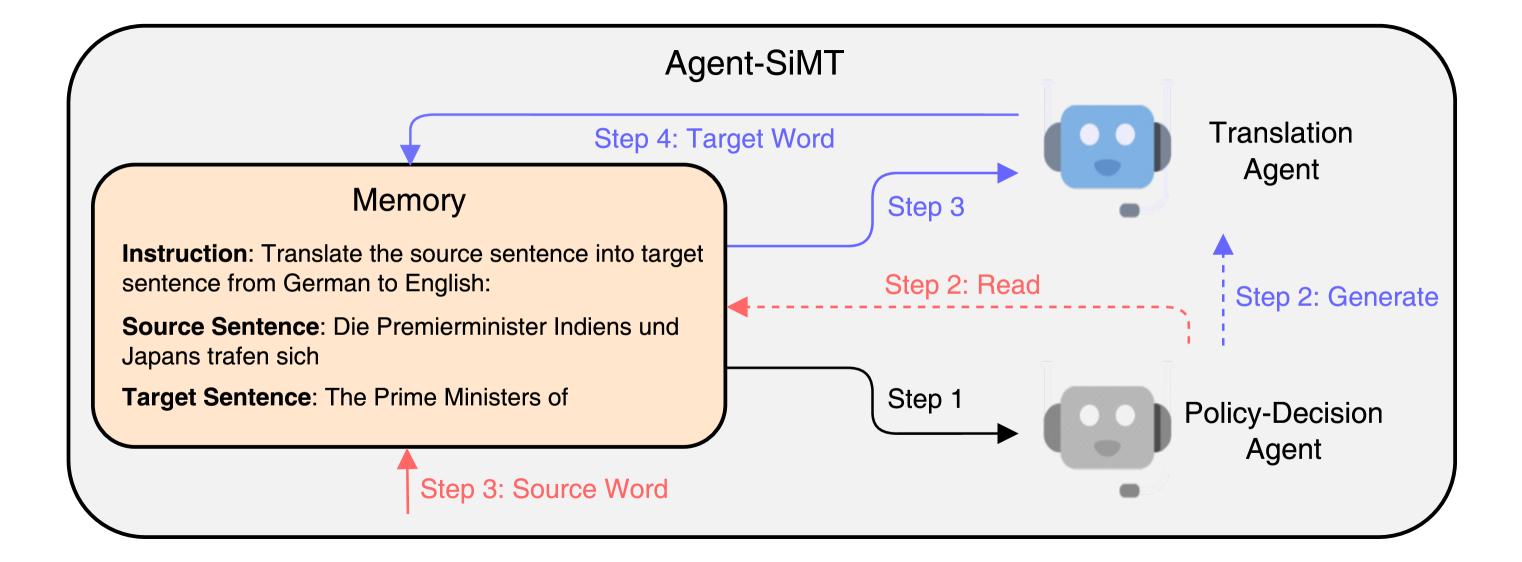
Agent-SiMT: Agent-assisted Simultaneous Machine Translation with Large Language Models
Shoutao Guo, Shaolei Zhang, Zhengrui Ma, Min Zhang, Yang Feng
Simultaneous Machine Translation (SiMT) generates target translations while reading the source sentence. It relies on a policy to determine the optimal timing for reading sentences and generating translations. Existing SiMT methods generally adopt the traditional Transformer architecture, which concurrently determines the policy and generates translations. While they excel at determining policies, their translation performance is suboptimal. Conversely, Large Language Models (LLMs), trained on extensive corpora, possess superior generation capabilities, but it is difficult for them to acquire translation policy through the training methods of SiMT. Therefore, we introduce Agent-SiMT, a framework combining the strengths of LLMs and traditional SiMT methods. Agent-SiMT contains the policy-decision agent and the translation agent. The policy-decision agent is managed by a SiMT model, which determines the translation policy using partial source sentence and translation. The translation agent, leveraging an LLM, generates translation based on the partial source sentence. The two agents collaborate to accomplish SiMT. Experiments demonstrate that Agent-SiMT attains state-of-the-art performance.
Read more6/13/2024
0
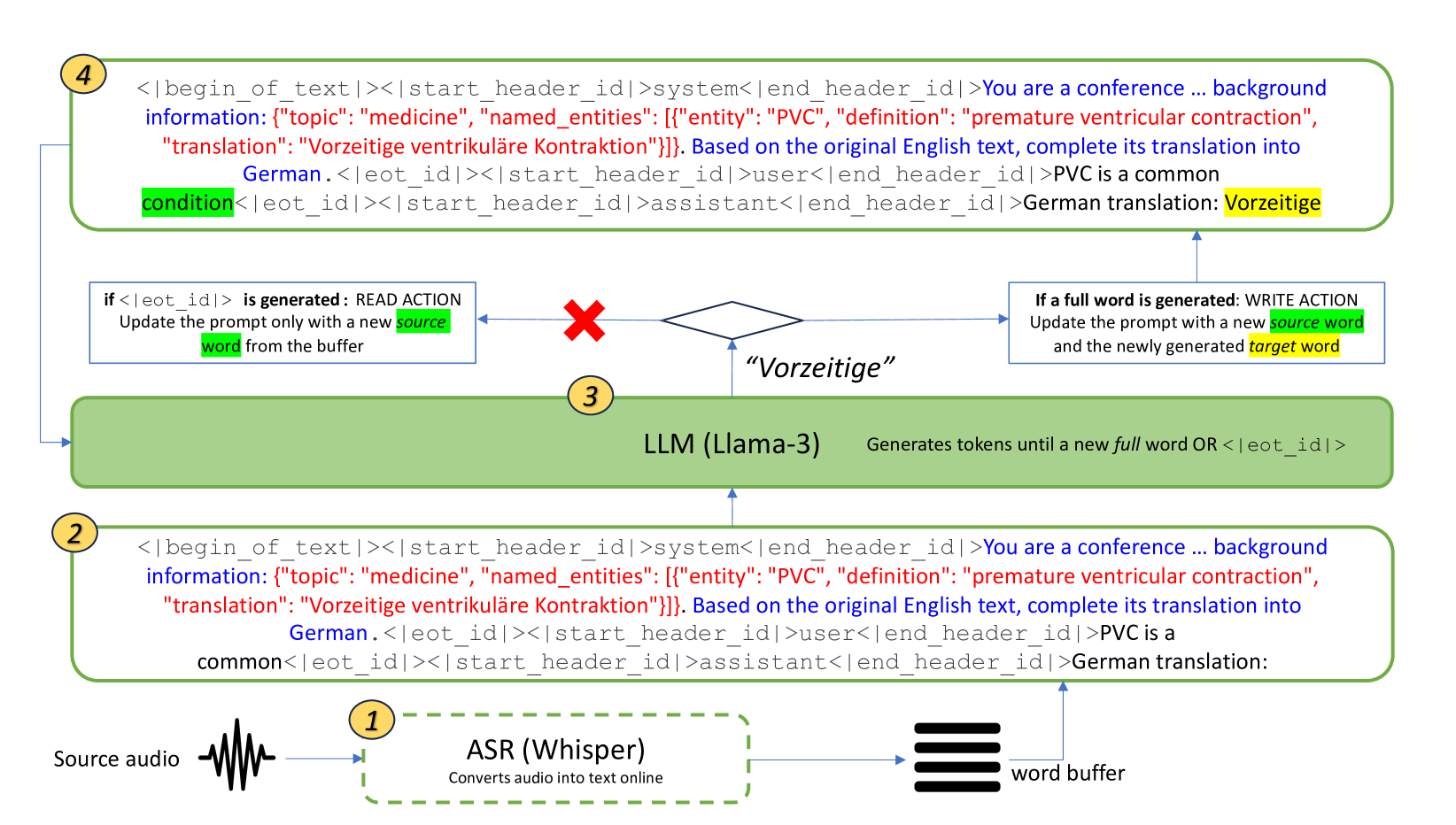
LLMs Are Zero-Shot Context-Aware Simultaneous Translators
Roman Koshkin, Katsuhito Sudoh, Satoshi Nakamura
The advent of transformers has fueled progress in machine translation. More recently large language models (LLMs) have come to the spotlight thanks to their generality and strong performance in a wide range of language tasks, including translation. Here we show that open-source LLMs perform on par with or better than some state-of-the-art baselines in simultaneous machine translation (SiMT) tasks, zero-shot. We also demonstrate that injection of minimal background information, which is easy with an LLM, brings further performance gains, especially on challenging technical subject-matter. This highlights LLMs' potential for building next generation of massively multilingual, context-aware and terminologically accurate SiMT systems that require no resource-intensive training or fine-tuning.
Read more6/24/2024