SeiT++: Masked Token Modeling Improves Storage-efficient Training
2312.10105
0
0

Abstract
Recent advancements in Deep Neural Network (DNN) models have significantly improved performance across computer vision tasks. However, achieving highly generalizable and high-performing vision models requires expansive datasets, resulting in significant storage requirements. This storage challenge is a critical bottleneck for scaling up models. A recent breakthrough by SeiT proposed the use of Vector-Quantized (VQ) feature vectors (i.e., tokens) as network inputs for vision classification. This approach achieved 90% of the performance of a model trained on full-pixel images with only 1% of the storage. While SeiT needs labeled data, its potential in scenarios beyond fully supervised learning remains largely untapped. In this paper, we extend SeiT by integrating Masked Token Modeling (MTM) for self-supervised pre-training. Recognizing that self-supervised approaches often demand more data due to the lack of labels, we introduce TokenAdapt and ColorAdapt. These methods facilitate comprehensive token-friendly data augmentation, effectively addressing the increased data requirements of self-supervised learning. We evaluate our approach across various scenarios, including storage-efficient ImageNet-1k classification, fine-grained classification, ADE-20k semantic segmentation, and robustness benchmarks. Experimental results demonstrate consistent performance improvement in diverse experiments, validating the effectiveness of our method. Code is available at https://github.com/naver-ai/tokenadapt.
Create account to get full access
Overview
- The paper proposes a method called "Forging Tokens" to improve the storage efficiency of training large language models.
- The key idea is to use a limited set of augmentations to create artificial tokens that are incorporated into the training data, allowing the model to learn more expressive representations with fewer parameters.
- This approach is designed to address the challenge of training large, parameter-efficient models that can be deployed on resource-constrained devices.
Plain English Explanation
Imagine you're trying to build a really smart computer program that can understand and generate human language. These kinds of "language models" are usually very complex and require a lot of storage space to store all the information they've learned. The authors of this paper have come up with a clever way to make these language models more efficient, so they can be used on devices with limited storage, like your smartphone.
The key idea is to create some "fake" words or "tokens" and add them to the data the model is trained on. These fake tokens are generated using a limited set of changes or "augmentations" to the real words in the training data. By learning to recognize and use these fake tokens, the model can develop more expressive and compact representations, allowing it to achieve high performance with fewer parameters (the building blocks that store the model's knowledge).
This approach is like teaching a child a few new words that are related to the ones they already know. The child can then use those new words to express more complex ideas, without having to learn a huge vocabulary from scratch. Similarly, the language model can learn to use these "forged tokens" to capture more nuanced meanings and patterns in the language, without needing to store as much information.
The authors believe this method could be especially useful for deploying powerful language models on devices with limited storage, like your phone or a smart speaker. By making the models more efficient, they can run on these devices without taking up too much space.
Technical Explanation
The key contribution of this paper is a method called "Forging Tokens" that aims to improve the storage efficiency of large language models. The core idea is to create a set of artificial tokens that are incorporated into the training data, allowing the model to learn more expressive representations with fewer parameters.
The authors propose a limited set of augmentations, such as character-level transformations, to generate these forged tokens from the original training data. By learning to recognize and utilize these forged tokens, the model can develop more compact representations, as it can express complex concepts using a smaller number of parameters.
The authors evaluate their approach on several language modeling benchmarks, including WikiText-103 and enwik8. They show that models trained with forged tokens can achieve comparable or better performance compared to standard language models, while using significantly fewer parameters. For example, on the enwik8 dataset, their approach reduces the model size by 40% without sacrificing perplexity.
The authors argue that this method is particularly relevant for deploying powerful language models on resource-constrained devices, as it allows for more efficient storage of the model's parameters. They also discuss potential extensions, such as exploring more sophisticated token augmentation strategies and applying the forging technique to other types of neural architectures.
Critical Analysis
The Forging Tokens method presented in this paper is a promising approach for improving the storage efficiency of large language models. By leveraging a limited set of token augmentations, the authors demonstrate that models can learn more expressive representations using fewer parameters, without significantly compromising performance.
One limitation of the current work is the relatively simple set of token augmentations explored, which may not fully capture the rich diversity of natural language. Investigating more sophisticated augmentation strategies, potentially drawing inspiration from data augmentation techniques used in other domains, could further enhance the effectiveness of the forging approach.
Additionally, the authors note that the performance gains from forging tokens may be more pronounced for certain types of language modeling tasks or architectures. Exploring the broader applicability of the method, including to other natural language processing domains and emerging model architectures, could uncover additional use cases and tradeoffs.
Finally, while the paper focuses on the storage efficiency benefits of forging tokens, it would be valuable to also examine the potential implications for the model's interpretability and robustness. Understanding how the forged tokens are integrated into the model's internal representations and how they affect the model's behavior in diverse real-world scenarios could provide additional insights and guide future research in this direction.
Conclusion
The Forging Tokens method proposed in this paper offers a promising approach for improving the storage efficiency of large language models, which is a crucial consideration for deploying these models on resource-constrained devices. By leveraging a limited set of token augmentations, the authors demonstrate that models can learn more expressive representations using fewer parameters, without significantly sacrificing performance.
This work represents an important step towards developing more compact and deployable language models, with potential applications in a wide range of scenarios, from personal digital assistants to industrial automation. As the field of natural language processing continues to advance, techniques like Forging Tokens may play a pivotal role in enabling the widespread adoption of powerful language models across a diverse range of computing platforms and real-world use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Morphing Tokens Draw Strong Masked Image Models
Taekyung Kim, Byeongho Heo, Dongyoon Han
0
0
Masked image modeling (MIM) is a promising option for training Vision Transformers among various self-supervised learning (SSL) methods. The essence of MIM lies in token-wise masked token predictions, with targets tokenized from images or generated by pre-trained models such as vision-language models. While tokenizers or pre-trained models are plausible MIM targets, they often offer spatially inconsistent targets even for neighboring tokens, complicating models to learn unified discriminative representations. Our pilot study confirms that addressing spatial inconsistencies has the potential to enhance representation quality. Motivated by the findings, we introduce a novel self-supervision signal called Dynamic Token Morphing (DTM), which dynamically aggregates contextually related tokens to yield contextualized targets. DTM is compatible with various SSL frameworks; we showcase an improved MIM by employing DTM, barely introducing extra training costs. Our experiments on ImageNet-1K and ADE20K demonstrate the superiority of our methods compared with state-of-the-art, complex MIM methods. Furthermore, the comparative evaluation of the iNaturalists and fine-grained visual classification datasets further validates the transferability of our method on various downstream tasks. Code is available at https://github.com/naver-ai/dtm
5/3/2024

Emerging Property of Masked Token for Effective Pre-training
Hyesong Choi, Hunsang Lee, Seyoung Joung, Hyejin Park, Jiyeong Kim, Dongbo Min
0
0
Driven by the success of Masked Language Modeling (MLM), the realm of self-supervised learning for computer vision has been invigorated by the central role of Masked Image Modeling (MIM) in driving recent breakthroughs. Notwithstanding the achievements of MIM across various downstream tasks, its overall efficiency is occasionally hampered by the lengthy duration of the pre-training phase. This paper presents a perspective that the optimization of masked tokens as a means of addressing the prevailing issue. Initially, we delve into an exploration of the inherent properties that a masked token ought to possess. Within the properties, we principally dedicated to articulating and emphasizing the `data singularity' attribute inherent in masked tokens. Through a comprehensive analysis of the heterogeneity between masked tokens and visible tokens within pre-trained models, we propose a novel approach termed masked token optimization (MTO), specifically designed to improve model efficiency through weight recalibration and the enhancement of the key property of masked tokens. The proposed method serves as an adaptable solution that seamlessly integrates into any MIM approach that leverages masked tokens. As a result, MTO achieves a considerable improvement in pre-training efficiency, resulting in an approximately 50% reduction in pre-training epochs required to attain converged performance of the recent approaches.
4/15/2024
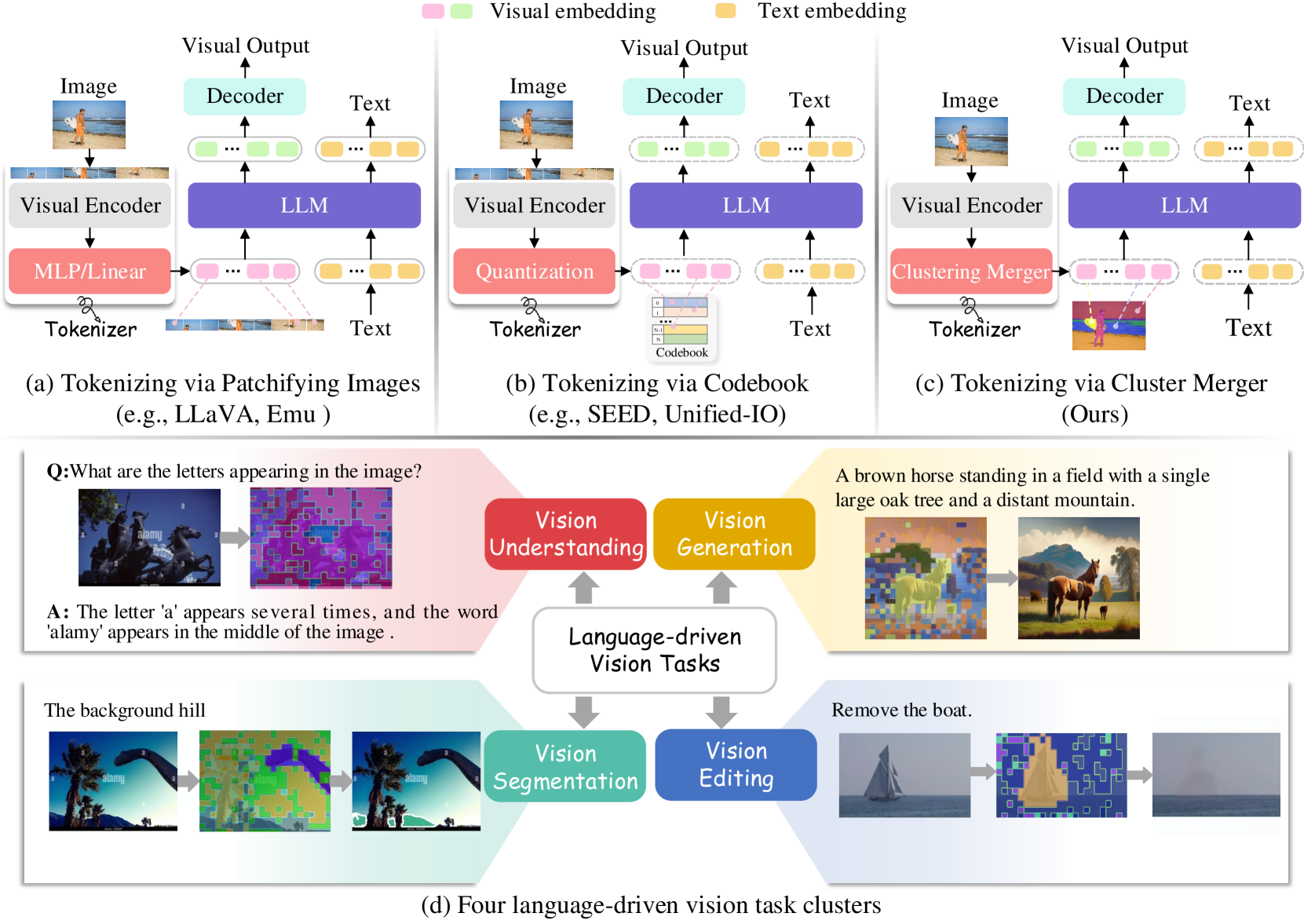
Towards Semantic Equivalence of Tokenization in Multimodal LLM
Shengqiong Wu, Hao Fei, Xiangtai Li, Jiayi Ji, Hanwang Zhang, Tat-Seng Chua, Shuicheng Yan
0
0
Multimodal Large Language Models (MLLMs) have demonstrated exceptional capabilities in processing vision-language tasks. One of the crux of MLLMs lies in vision tokenization, which involves efficiently transforming input visual signals into feature representations that are most beneficial for LLMs. However, existing vision tokenizers, essential for semantic alignment between vision and language, remain problematic. Existing methods aggressively fragment visual input, corrupting the visual semantic integrity. To address this, this paper proposes a novel dynamic Semantic-Equivalent Vision Tokenizer (SeTok), which groups visual features into semantic units via a dynamic clustering algorithm, flexibly determining the number of tokens based on image complexity. The resulting vision tokens effectively preserve semantic integrity and capture both low-frequency and high-frequency visual features. The proposed MLLM (Setokim) equipped with SeTok significantly demonstrates superior performance across various tasks, as evidenced by our experimental results. The project page is at https://chocowu.github.io/SeTok-web/.
6/28/2024

Salience-Based Adaptive Masking: Revisiting Token Dynamics for Enhanced Pre-training
Hyesong Choi, Hyejin Park, Kwang Moo Yi, Sungmin Cha, Dongbo Min
0
0
In this paper, we introduce Saliency-Based Adaptive Masking (SBAM), a novel and cost-effective approach that significantly enhances the pre-training performance of Masked Image Modeling (MIM) approaches by prioritizing token salience. Our method provides robustness against variations in masking ratios, effectively mitigating the performance instability issues common in existing methods. This relaxes the sensitivity of MIM-based pre-training to masking ratios, which in turn allows us to propose an adaptive strategy for `tailored' masking ratios for each data sample, which no existing method can provide. Toward this goal, we propose an Adaptive Masking Ratio (AMR) strategy that dynamically adjusts the proportion of masking for the unique content of each image based on token salience. We show that our method significantly improves over the state-of-the-art in mask-based pre-training on the ImageNet-1K dataset.
4/15/2024