Towards Semantic Equivalence of Tokenization in Multimodal LLM
2406.05127
0
0
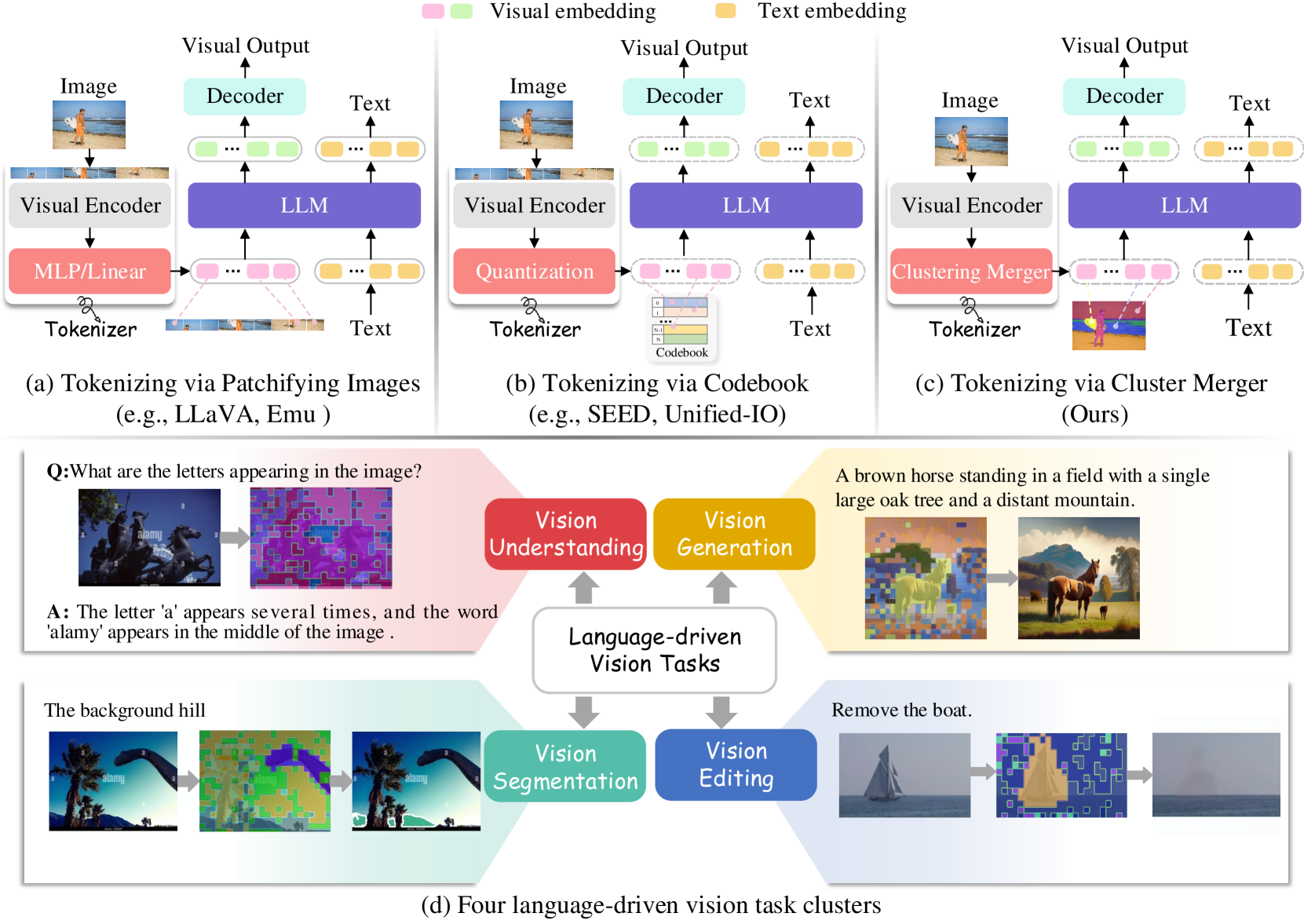
Abstract
Multimodal Large Language Models (MLLMs) have demonstrated exceptional capabilities in processing vision-language tasks. One of the crux of MLLMs lies in vision tokenization, which involves efficiently transforming input visual signals into feature representations that are most beneficial for LLMs. However, existing vision tokenizers, essential for semantic alignment between vision and language, remain problematic. Existing methods aggressively fragment visual input, corrupting the visual semantic integrity. To address this, this paper proposes a novel dynamic Semantic-Equivalent Vision Tokenizer (SeTok), which groups visual features into semantic units via a dynamic clustering algorithm, flexibly determining the number of tokens based on image complexity. The resulting vision tokens effectively preserve semantic integrity and capture both low-frequency and high-frequency visual features. The proposed MLLM (Setokim) equipped with SeTok significantly demonstrates superior performance across various tasks, as evidenced by our experimental results. The project page is at https://chocowu.github.io/SeTok-web/.
Create account to get full access
Overview
- Examines the importance of semantic equivalence in tokenization for multimodal large language models (LLMs)
- Proposes a novel approach to achieve semantic equivalence across modalities
- Demonstrates the benefits of semantically equivalent tokenization for improved model performance and interpretability
Plain English Explanation
The paper explores the concept of semantic equivalence in the tokenization process used by multimodal large language models (LLMs). These models are designed to understand and generate text, images, and other media simultaneously.
The key idea is that the way the model breaks down and represents information (i.e., tokenization) should be semantically consistent across different input modalities. This means that the tokens used to represent similar concepts, whether in text or images, should have similar meanings.
Achieving semantic equivalence in tokenization can lead to several benefits:
-
Improved Model Performance: When the tokenization is semantically aligned, the model can better recognize and leverage connections between different types of input, leading to enhanced overall performance.
-
Enhanced Interpretability: Semantically equivalent tokens make it easier for humans to understand how the model is processing and reasoning about the information, improving transparency.
-
Efficient Model Architecture: Semantic equivalence can enable more efficient model design and optimization, as the different modalities can be better integrated and shared.
The paper proposes a novel approach to achieve this semantic equivalence, which involves modifications to the tokenization process and model architecture. The researchers demonstrate the effectiveness of their method through experiments and comparisons to other techniques.
Technical Explanation
The paper presents a multimodal tokenization framework that aims to achieve semantic equivalence across different input modalities, such as text and images.
The key components of the proposed approach are:
-
Modality-Specific Tokenizers: The model uses separate tokenizers for text and visual inputs, each optimized for its respective modality.
-
Semantic Alignment: The tokenizers are trained to produce tokens that are semantically equivalent across modalities, even for complex concepts.
-
Unified Token Representation: The model learns a shared token representation that encodes the semantic meaning consistently, regardless of the input modality.
The researchers evaluate their approach on several multimodal tasks, including image-text retrieval and multimodal classification. They demonstrate that the semantically equivalent tokenization leads to improved performance compared to baseline methods that do not explicitly address this alignment.
Furthermore, the paper discusses how the semantic equivalence enhances the interpretability of the model's internal representations, as the tokens can be more readily understood and mapped across modalities.
Critical Analysis
The paper presents a compelling approach to addressing the challenge of semantic equivalence in multimodal LLMs. The proposed framework is well-designed and the experimental results are promising, showing the benefits of the method.
However, the paper does not extensively discuss the limitations or potential challenges that may arise in real-world deployment scenarios. For example, the authors do not address how the approach would scale to larger and more diverse datasets, or how it might perform on more complex multimodal tasks.
Additionally, the paper could have delved deeper into the computational efficiency of the proposed architecture, as this is an important consideration for the practical deployment of such models.
Further research could also explore how the semantic equivalence concept might be extended to other modalities, such as audio or video, to create truly cross-modal understanding in LLMs.
Conclusion
This paper makes a significant contribution to the field of multimodal language modeling by introducing a novel approach to achieving semantic equivalence in the tokenization process. By ensuring that the tokens used to represent information across modalities have consistent semantic meanings, the model can better leverage the connections between different types of input, leading to improved performance, interpretability, and efficiency.
The findings of this research have important implications for the development of advanced multimodal AI systems that can seamlessly integrate and understand information from diverse sources. As the field of multimodal LLMs continues to evolve, the principles of semantic equivalence outlined in this paper will likely play a crucial role in driving further advancements and real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
Semantic Equitable Clustering: A Simple, Fast and Effective Strategy for Vision Transformer
Qihang Fan, Huaibo Huang, Mingrui Chen, Ran He
0
0
The Vision Transformer (ViT) has gained prominence for its superior relational modeling prowess. However, its global attention mechanism's quadratic complexity poses substantial computational burdens. A common remedy spatially groups tokens for self-attention, reducing computational requirements. Nonetheless, this strategy neglects semantic information in tokens, possibly scattering semantically-linked tokens across distinct groups, thus compromising the efficacy of self-attention intended for modeling inter-token dependencies. Motivated by these insights, we introduce a fast and balanced clustering method, named textbf{S}emantic textbf{E}quitable textbf{C}lustering (SEC). SEC clusters tokens based on their global semantic relevance in an efficient, straightforward manner. In contrast to traditional clustering methods requiring multiple iterations, our method achieves token clustering in a single pass. Additionally, SEC regulates the number of tokens per cluster, ensuring a balanced distribution for effective parallel processing on current computational platforms without necessitating further optimization. Capitalizing on SEC, we propose a versatile vision backbone, SecViT. Comprehensive experiments in image classification, object detection, instance segmentation, and semantic segmentation validate to the effectiveness of SecViT. Remarkably, SecViT attains an impressive textbf{84.2%} image classification accuracy with only textbf{27M} parameters and textbf{4.4G} FLOPs, without the need for for additional supervision or data. Code will be available at url{https://github.com/qhfan/SecViT}.
5/24/2024
🚀
Auto-Encoding Morph-Tokens for Multimodal LLM
Kaihang Pan, Siliang Tang, Juncheng Li, Zhaoyu Fan, Wei Chow, Shuicheng Yan, Tat-Seng Chua, Yueting Zhuang, Hanwang Zhang
0
0
For multimodal LLMs, the synergy of visual comprehension (textual output) and generation (visual output) presents an ongoing challenge. This is due to a conflicting objective: for comprehension, an MLLM needs to abstract the visuals; for generation, it needs to preserve the visuals as much as possible. Thus, the objective is a dilemma for visual-tokens. To resolve the conflict, we propose encoding images into morph-tokens to serve a dual purpose: for comprehension, they act as visual prompts instructing MLLM to generate texts; for generation, they take on a different, non-conflicting role as complete visual-tokens for image reconstruction, where the missing visual cues are recovered by the MLLM. Extensive experiments show that morph-tokens can achieve a new SOTA for multimodal comprehension and generation simultaneously. Our project is available at https://github.com/DCDmllm/MorphTokens.
5/6/2024
🤔
Understanding the Effect of using Semantically Meaningful Tokens for Visual Representation Learning
Neha Kalibhat, Priyatham Kattakinda, Arman Zarei, Nikita Seleznev, Samuel Sharpe, Senthil Kumar, Soheil Feizi
0
0
Vision transformers have established a precedent of patchifying images into uniformly-sized chunks before processing. We hypothesize that this design choice may limit models in learning comprehensive and compositional representations from visual data. This paper explores the notion of providing semantically-meaningful visual tokens to transformer encoders within a vision-language pre-training framework. Leveraging off-the-shelf segmentation and scene-graph models, we extract representations of instance segmentation masks (referred to as tangible tokens) and relationships and actions (referred to as intangible tokens). Subsequently, we pre-train a vision-side transformer by incorporating these newly extracted tokens and aligning the resultant embeddings with caption embeddings from a text-side encoder. To capture the structural and semantic relationships among visual tokens, we introduce additive attention weights, which are used to compute self-attention scores. Our experiments on COCO demonstrate notable improvements over ViTs in learned representation quality across text-to-image (+47%) and image-to-text retrieval (+44%) tasks. Furthermore, we showcase the advantages on compositionality benchmarks such as ARO (+18%) and Winoground (+10%).
5/28/2024

SeiT++: Masked Token Modeling Improves Storage-efficient Training
Minhyun Lee, Song Park, Byeongho Heo, Dongyoon Han, Hyunjung Shim
0
0
Recent advancements in Deep Neural Network (DNN) models have significantly improved performance across computer vision tasks. However, achieving highly generalizable and high-performing vision models requires expansive datasets, resulting in significant storage requirements. This storage challenge is a critical bottleneck for scaling up models. A recent breakthrough by SeiT proposed the use of Vector-Quantized (VQ) feature vectors (i.e., tokens) as network inputs for vision classification. This approach achieved 90% of the performance of a model trained on full-pixel images with only 1% of the storage. While SeiT needs labeled data, its potential in scenarios beyond fully supervised learning remains largely untapped. In this paper, we extend SeiT by integrating Masked Token Modeling (MTM) for self-supervised pre-training. Recognizing that self-supervised approaches often demand more data due to the lack of labels, we introduce TokenAdapt and ColorAdapt. These methods facilitate comprehensive token-friendly data augmentation, effectively addressing the increased data requirements of self-supervised learning. We evaluate our approach across various scenarios, including storage-efficient ImageNet-1k classification, fine-grained classification, ADE-20k semantic segmentation, and robustness benchmarks. Experimental results demonstrate consistent performance improvement in diverse experiments, validating the effectiveness of our method. Code is available at https://github.com/naver-ai/tokenadapt.
4/4/2024