Self-Consistent Reasoning-based Aspect-Sentiment Quad Prediction with Extract-Then-Assign Strategy

0

Sign in to get full access
Overview
- This paper presents a novel framework called SCRAP (Self-Consistent Reasoning-based Aspect-Sentiment Quad Prediction) for predicting aspect-sentiment quadruples from text.
- The key idea is to use a self-consistent reasoning process to jointly extract aspects and their associated sentiments, leveraging the inherent relationships between them.
- The framework employs an "extract-then-assign" strategy, first extracting aspect and sentiment candidates, then aligning them through a reasoning module to produce the final aspect-sentiment quadruples.
Plain English Explanation
The paper describes a new approach to analyzing opinions and sentiments expressed in text, such as product reviews or social media posts. The goal is to identify the specific aspects (features or attributes) that are being discussed, and the sentiment (positive, negative, or neutral) associated with each aspect.
The SCRAP framework uses a two-step process to accomplish this. First, it extracts a set of potential aspects and sentiments from the text. Then, it uses a "reasoning" module to align the aspects and sentiments, producing the final aspect-sentiment pairs.
This reasoning process is "self-consistent", meaning it considers the relationships between the different aspects and sentiments to ensure the final predictions are coherent and make sense. For example, if the text mentions "great battery life" and "poor camera quality", the framework would recognize that "battery life" and "camera quality" are different aspects, and assign the appropriate positive and negative sentiments to each.
By leveraging these inherent relationships, the SCRAP framework can make more accurate and meaningful predictions than approaches that consider aspects and sentiments in isolation. This could be useful for applications like customer service, product development, or market research, where understanding people's opinions on specific features is important.
Technical Explanation
The SCRAP framework consists of three main components:
-
Aspect and Sentiment Extraction: This module uses a series of natural language processing techniques to identify a set of potential aspects and sentiments expressed in the input text.
-
Aspect-Sentiment Alignment: The key innovation of this paper is the "Self-Consistent Reasoning" module, which takes the extracted aspects and sentiments and aligns them into coherent aspect-sentiment quadruples. This is done through an iterative process that considers the relationships between the different elements.
-
Output Generation: The final step is to produce the predicted aspect-sentiment quadruples as the output of the system.
The authors evaluate the SCRAP framework on several benchmark datasets for aspect-based sentiment analysis, and show that it outperforms state-of-the-art methods on a range of metrics. The self-consistent reasoning approach appears to be a key factor in the improved performance.
Critical Analysis
The SCRAP framework presents a novel and promising approach to aspect-sentiment analysis, with several strengths:
- The self-consistent reasoning process is a unique and theoretically-grounded way to leverage the inherent relationships between aspects and sentiments.
- The extract-then-assign strategy allows the model to handle a wide range of possible aspect-sentiment combinations, rather than being limited to a pre-defined set.
- The evaluation results demonstrate significant performance improvements over existing techniques, suggesting the approach has merit.
However, there are also some potential limitations and areas for further research:
- The paper does not provide a detailed analysis of the types of errors or failures that the SCRAP framework might encounter. Understanding the edge cases and failure modes would be helpful for assessing the robustness of the approach.
- The reasoning process is described at a high level, and more details on the specific algorithms and implementation choices would be useful for researchers seeking to build upon this work.
- The experiments are limited to a few standard benchmark datasets, so further testing on diverse real-world datasets would help validate the generalizability of the approach.
Overall, the SCRAP framework represents an interesting and promising contribution to the field of aspect-based sentiment analysis. With further research and refinement, it could lead to more accurate and nuanced understanding of opinions expressed in text.
Conclusion
The SCRAP framework introduced in this paper offers a novel approach to the problem of aspect-sentiment analysis. By using a self-consistent reasoning process to align extracted aspects and sentiments, the framework can produce more coherent and meaningful predictions than previous methods.
The key innovation is the reasoning module, which considers the inherent relationships between different aspects and sentiments to ensure the final output is logically consistent. This allows the framework to handle a wide range of possible aspect-sentiment combinations, rather than being limited to a pre-defined set.
The empirical evaluation shows that SCRAP outperforms state-of-the-art techniques on several benchmark datasets, suggesting the approach has merit. While there are some potential limitations and areas for further research, the SCRAP framework represents an important step forward in the field of opinion mining and sentiment analysis.
As more and more of our interactions and decision-making move into the digital realm, the ability to accurately understand and interpret opinions expressed in text will become increasingly valuable. The SCRAP framework's combination of technical sophistication and real-world applicability make it a compelling contribution to this important and rapidly evolving area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Consistent Reasoning-based Aspect-Sentiment Quad Prediction with Extract-Then-Assign Strategy
Jieyong Kim, Ryang Heo, Yongsik Seo, SeongKu Kang, Jinyoung Yeo, Dongha Lee
In the task of aspect sentiment quad prediction (ASQP), generative methods for predicting sentiment quads have shown promising results. However, they still suffer from imprecise predictions and limited interpretability, caused by data scarcity and inadequate modeling of the quadruplet composition process. In this paper, we propose Self-Consistent Reasoning-based Aspect-sentiment quadruple Prediction (SCRAP), optimizing its model to generate reasonings and the corresponding sentiment quadruplets in sequence. SCRAP adopts the Extract-Then-Assign reasoning strategy, which closely mimics human cognition. In the end, SCRAP significantly improves the model's ability to handle complex reasoning tasks and correctly predict quadruplets through consistency voting, resulting in enhanced interpretability and accuracy in ASQP.
Read more6/11/2024
0
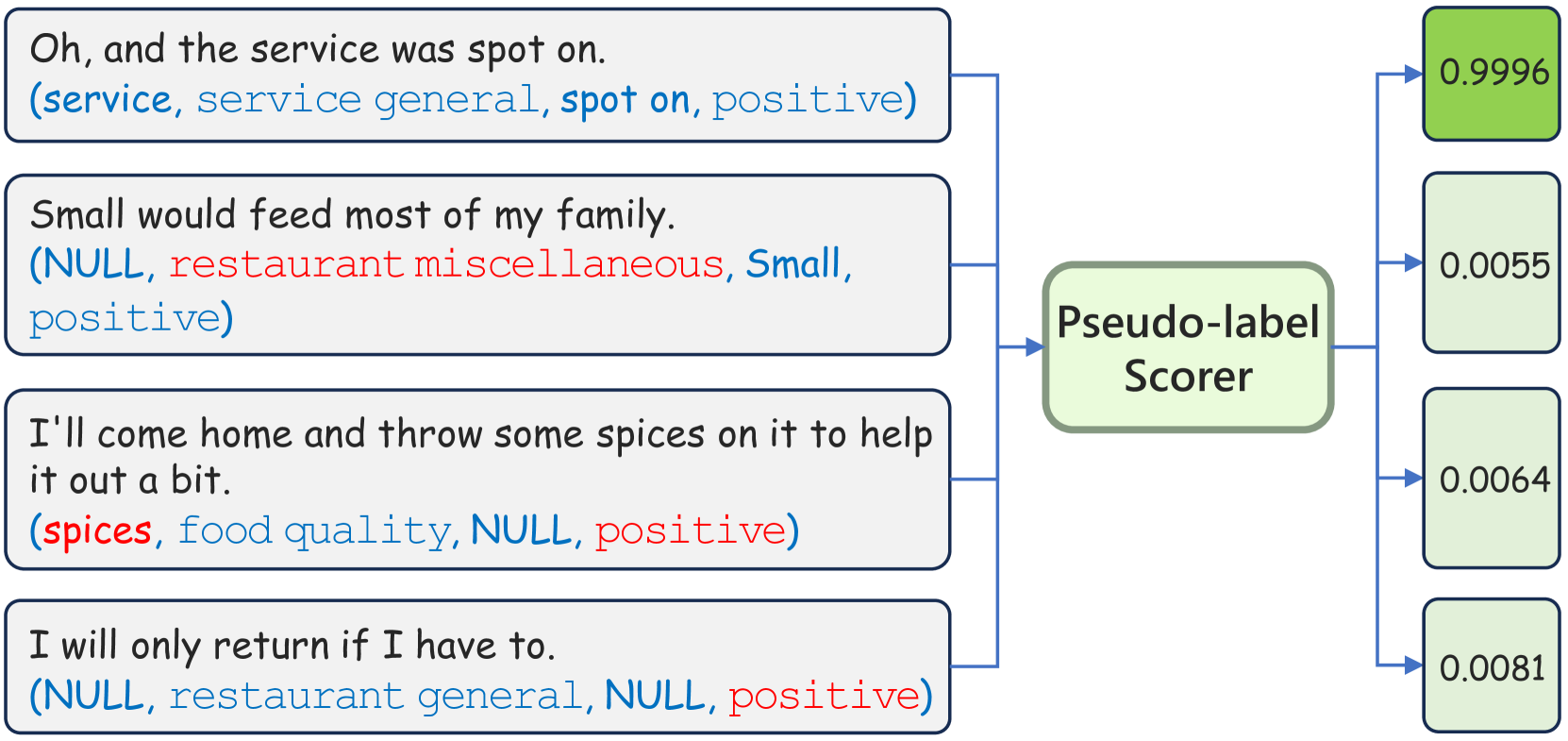
Self-Training with Pseudo-Label Scorer for Aspect Sentiment Quad Prediction
Yice Zhang, Jie Zeng, Weiming Hu, Ziyi Wang, Shiwei Chen, Ruifeng Xu
Aspect Sentiment Quad Prediction (ASQP) aims to predict all quads (aspect term, aspect category, opinion term, sentiment polarity) for a given review, which is the most representative and challenging task in aspect-based sentiment analysis. A key challenge in the ASQP task is the scarcity of labeled data, which limits the performance of existing methods. To tackle this issue, we propose a self-training framework with a pseudo-label scorer, wherein a scorer assesses the match between reviews and their pseudo-labels, aiming to filter out mismatches and thereby enhance the effectiveness of self-training. We highlight two critical aspects to ensure the scorer's effectiveness and reliability: the quality of the training dataset and its model architecture. To this end, we create a human-annotated comparison dataset and train a generative model on it using ranking-based objectives. Extensive experiments on public ASQP datasets reveal that using our scorer can greatly and consistently improve the effectiveness of self-training. Moreover, we explore the possibility of replacing humans with large language models for comparison dataset annotation, and experiments demonstrate its feasibility. We release our code and data at https://github.com/HITSZ-HLT/ST-w-Scorer-ABSA .
Read more6/27/2024

0
BvSP: Broad-view Soft Prompting for Few-Shot Aspect Sentiment Quad Prediction
Yinhao Bai, Yalan Xie, Xiaoyi Liu, Yuhua Zhao, Zhixin Han, Mengting Hu, Hang Gao, Renhong Cheng
Aspect sentiment quad prediction (ASQP) aims to predict four aspect-based elements, including aspect term, opinion term, aspect category, and sentiment polarity. In practice, unseen aspects, due to distinct data distribution, impose many challenges for a trained neural model. Motivated by this, this work formulates ASQP into the few-shot scenario, which aims for fast adaptation in real applications. Therefore, we first construct a few-shot ASQP dataset (FSQP) that contains richer categories and is more balanced for the few-shot study. Moreover, recent methods extract quads through a generation paradigm, which involves converting the input sentence into a templated target sequence. However, they primarily focus on the utilization of a single template or the consideration of different template orders, thereby overlooking the correlations among various templates. To tackle this issue, we further propose a Broadview Soft Prompting (BvSP) method that aggregates multiple templates with a broader view by taking into account the correlation between the different templates. Specifically, BvSP uses the pre-trained language model to select the most relevant k templates with Jensen-Shannon divergence. BvSP further introduces soft prompts to guide the pre-trained language model using the selected templates. Then, we aggregate the results of multi-templates by voting mechanism. Empirical results demonstrate that BvSP significantly outperforms the stateof-the-art methods under four few-shot settings and other public datasets. Our code and dataset are available at https://github.com/byinhao/BvSP.
Read more6/12/2024
⛏️
0
iACOS: Advancing Implicit Sentiment Extraction with Informative and Adaptive Negative Examples
Xiancai Xu, Jia-Dong Zhang, Lei Xiong, Zhishang Liu
Aspect-based sentiment analysis (ABSA) have been extensively studied, but little light has been shed on the quadruple extraction consisting of four fundamental elements: aspects, categories, opinions and sentiments, especially with implicit aspects and opinions. In this paper, we propose a new method iACOS for extracting Implicit Aspects with Categories and Opinions with Sentiments. First, iACOS appends two implicit tokens at the end of a text to capture the context-aware representation of all tokens including implicit aspects and opinions. Second, iACOS develops a sequence labeling model over the context-aware token representation to co-extract explicit and implicit aspects and opinions. Third, iACOS devises a multi-label classifier with a specialized multi-head attention for discovering aspect-opinion pairs and predicting their categories and sentiments simultaneously. Fourth, iACOS leverages informative and adaptive negative examples to jointly train the multi-label classifier and the other two classifiers on categories and sentiments by multi-task learning. Finally, the experimental results show that iACOS significantly outperforms other quadruple extraction baselines according to the F1 score on two public benchmark datasets.
Read more6/26/2024