Self-supervised Dataset Distillation: A Good Compression Is All You Need

0
🔗
Sign in to get full access
Overview
- Dataset distillation compresses information from a large dataset into a smaller dataset while preserving the original data's essence.
- Previous studies focused on aligning intermediate model statistics like weight trajectory, features, and batch normalization between the original and distilled data.
- This work explores a new perspective: model informativeness during the compression stage on original dataset pretraining.
Plain English Explanation
The goal of dataset distillation is to take a large, complex dataset and create a smaller, more compact version that still captures the important information from the original. This can be useful for training machine learning models more efficiently, as the smaller dataset requires less computational power and storage.
Previous approaches to dataset distillation have mainly tried to ensure that certain statistical properties of the original dataset, like the trajectory of the model's weights or the features it learns, are preserved in the distilled dataset. However, the authors of this paper noticed that as model sizes increase, it becomes harder for supervised pre-trained models to recover the full scope of information during the data synthesis (or distillation) process. This is because the mean and variance of the model's internal channels tend to flatten out, making the model less informative.
The key insight here is that larger variances in the batch normalization statistics of self-supervised models allow for stronger learning signals to update the recovered data during synthesis. Building on this, the researchers introduce a new framework called SC-DD, which uses self-supervision to facilitate more diverse and effective information compression and recovery compared to traditional supervised approaches.
Technical Explanation
The researchers observe that as model sizes increase, supervised dataset distillation methods like SRe²L, MTT, TESLA, DC, and CAFE struggle to fully recover the information learned by the original large pre-trained models. This is because the channel-wise mean and variance inside the models tend to flatten out, making the models less informative.
In contrast, the authors notice that self-supervised models have larger variances in their batch normalization statistics, which enables stronger learning signals to update the recovered data during the synthesis process. Building on this, they introduce SC-DD, a self-supervised compression framework for dataset distillation. SC-DD leverages the enhanced informative capabilities of large self-supervised pre-trained models to achieve more effective data compression and recovery compared to traditional supervised approaches.
The researchers conduct extensive experiments on CIFAR-100, Tiny-ImageNet, and ImageNet-1K datasets, demonstrating that SC-DD outperforms previous state-of-the-art supervised dataset distillation methods when using larger models, across various recovery and post-training budgets.
Critical Analysis
The paper provides a novel perspective on dataset distillation by focusing on model informativeness during the compression stage. The authors make a compelling case for the benefits of leveraging self-supervised pre-training to enhance the distillation process, especially as model sizes increase.
However, the paper does not discuss potential limitations or caveats of the SC-DD approach. For example, it would be valuable to understand how the method performs on more diverse or challenging datasets, or how it scales to even larger model sizes. Additionally, the authors could explore the trade-offs between the computational and memory requirements of self-supervised pre-training versus the gains in distillation performance.
Further research could also investigate the specific mechanisms by which self-supervised models maintain greater informative capacity during the distillation process. Understanding these underlying dynamics could lead to additional improvements in dataset distillation techniques.
Conclusion
This paper introduces a new self-supervised framework for dataset distillation, called SC-DD, that leverages the enhanced informative capabilities of large self-supervised pre-trained models to achieve more effective data compression and recovery compared to traditional supervised approaches. The researchers demonstrate the superiority of SC-DD over previous state-of-the-art methods, particularly when using larger models. This work highlights the importance of considering model informativeness during the dataset distillation process and opens up new avenues for further research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔗
0
Self-supervised Dataset Distillation: A Good Compression Is All You Need
Muxin Zhou, Zeyuan Yin, Shitong Shao, Zhiqiang Shen
Dataset distillation aims to compress information from a large-scale original dataset to a new compact dataset while striving to preserve the utmost degree of the original data informational essence. Previous studies have predominantly concentrated on aligning the intermediate statistics between the original and distilled data, such as weight trajectory, features, gradient, BatchNorm, etc. In this work, we consider addressing this task through the new lens of model informativeness in the compression stage on the original dataset pretraining. We observe that with the prior state-of-the-art SRe$^2$L, as model sizes increase, it becomes increasingly challenging for supervised pretrained models to recover learned information during data synthesis, as the channel-wise mean and variance inside the model are flatting and less informative. We further notice that larger variances in BN statistics from self-supervised models enable larger loss signals to update the recovered data by gradients, enjoying more informativeness during synthesis. Building on this observation, we introduce SC-DD, a simple yet effective Self-supervised Compression framework for Dataset Distillation that facilitates diverse information compression and recovery compared to traditional supervised learning schemes, further reaps the potential of large pretrained models with enhanced capabilities. Extensive experiments are conducted on CIFAR-100, Tiny-ImageNet and ImageNet-1K datasets to demonstrate the superiority of our proposed approach. The proposed SC-DD outperforms all previous state-of-the-art supervised dataset distillation methods when employing larger models, such as SRe$^2$L, MTT, TESLA, DC, CAFE, etc., by large margins under the same recovery and post-training budgets. Code is available at https://github.com/VILA-Lab/SRe2L/tree/main/SCDD/.
Read more4/12/2024
0
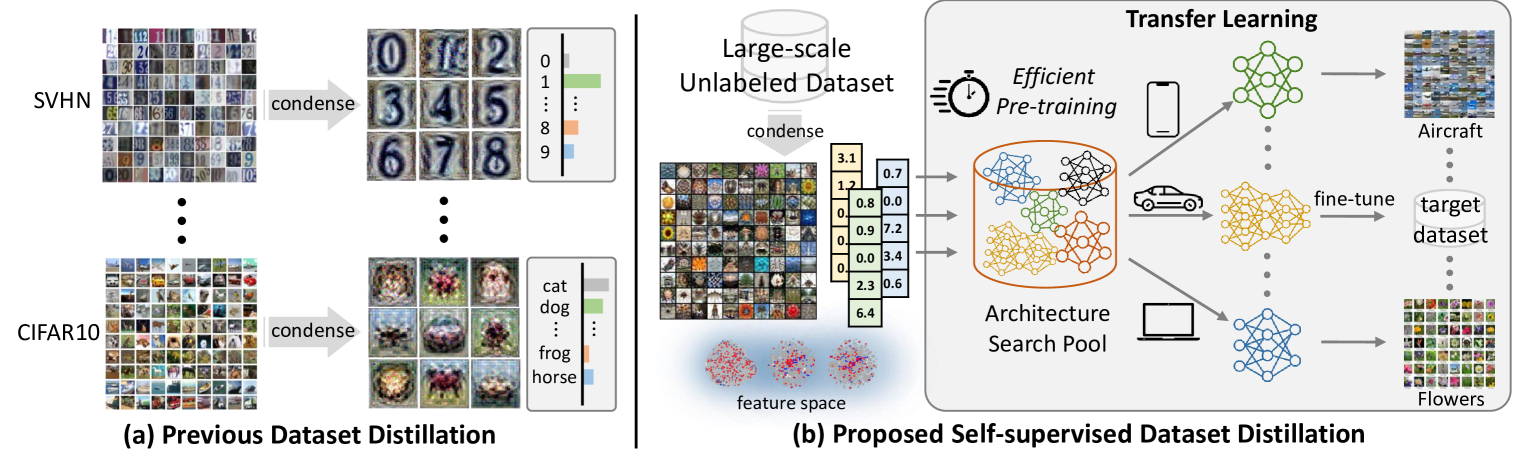
Self-Supervised Dataset Distillation for Transfer Learning
Dong Bok Lee, Seanie Lee, Joonho Ko, Kenji Kawaguchi, Juho Lee, Sung Ju Hwang
Dataset distillation methods have achieved remarkable success in distilling a large dataset into a small set of representative samples. However, they are not designed to produce a distilled dataset that can be effectively used for facilitating self-supervised pre-training. To this end, we propose a novel problem of distilling an unlabeled dataset into a set of small synthetic samples for efficient self-supervised learning (SSL). We first prove that a gradient of synthetic samples with respect to a SSL objective in naive bilevel optimization is textit{biased} due to the randomness originating from data augmentations or masking. To address this issue, we propose to minimize the mean squared error (MSE) between a model's representations of the synthetic examples and their corresponding learnable target feature representations for the inner objective, which does not introduce any randomness. Our primary motivation is that the model obtained by the proposed inner optimization can mimic the textit{self-supervised target model}. To achieve this, we also introduce the MSE between representations of the inner model and the self-supervised target model on the original full dataset for outer optimization. Lastly, assuming that a feature extractor is fixed, we only optimize a linear head on top of the feature extractor, which allows us to reduce the computational cost and obtain a closed-form solution of the head with kernel ridge regression. We empirically validate the effectiveness of our method on various applications involving transfer learning.
Read more4/15/2024

0
Not All Samples Should Be Utilized Equally: Towards Understanding and Improving Dataset Distillation
Shaobo Wang, Yantai Yang, Qilong Wang, Kaixin Li, Linfeng Zhang, Junchi Yan
Dataset Distillation (DD) aims to synthesize a small dataset capable of performing comparably to the original dataset. Despite the success of numerous DD methods, theoretical exploration of this area remains unaddressed. In this paper, we take an initial step towards understanding various matching-based DD methods from the perspective of sample difficulty. We begin by empirically examining sample difficulty, measured by gradient norm, and observe that different matching-based methods roughly correspond to specific difficulty tendencies. We then extend the neural scaling laws of data pruning to DD to theoretically explain these matching-based methods. Our findings suggest that prioritizing the synthesis of easier samples from the original dataset can enhance the quality of distilled datasets, especially in low IPC (image-per-class) settings. Based on our empirical observations and theoretical analysis, we introduce the Sample Difficulty Correction (SDC) approach, designed to predominantly generate easier samples to achieve higher dataset quality. Our SDC can be seamlessly integrated into existing methods as a plugin with minimal code adjustments. Experimental results demonstrate that adding SDC generates higher-quality distilled datasets across 7 distillation methods and 6 datasets.
Read more8/23/2024

0
What is Dataset Distillation Learning?
William Yang, Ye Zhu, Zhiwei Deng, Olga Russakovsky
Dataset distillation has emerged as a strategy to overcome the hurdles associated with large datasets by learning a compact set of synthetic data that retains essential information from the original dataset. While distilled data can be used to train high performing models, little is understood about how the information is stored. In this study, we posit and answer three questions about the behavior, representativeness, and point-wise information content of distilled data. We reveal distilled data cannot serve as a substitute for real data during training outside the standard evaluation setting for dataset distillation. Additionally, the distillation process retains high task performance by compressing information related to the early training dynamics of real models. Finally, we provide an framework for interpreting distilled data and reveal that individual distilled data points contain meaningful semantic information. This investigation sheds light on the intricate nature of distilled data, providing a better understanding on how they can be effectively utilized.
Read more7/23/2024