A self-supervised text-vision framework for automated brain abnormality detection
2405.02782
0
0
🔎
Abstract
Artificial neural networks trained on large, expert-labelled datasets are considered state-of-the-art for a range of medical image recognition tasks. However, categorically labelled datasets are time-consuming to generate and constrain classification to a pre-defined, fixed set of classes. For neuroradiological applications in particular, this represents a barrier to clinical adoption. To address these challenges, we present a self-supervised text-vision framework that learns to detect clinically relevant abnormalities in brain MRI scans by directly leveraging the rich information contained in accompanying free-text neuroradiology reports. Our training approach consisted of two-steps. First, a dedicated neuroradiological language model - NeuroBERT - was trained to generate fixed-dimensional vector representations of neuroradiology reports (N = 50,523) via domain-specific self-supervised learning tasks. Next, convolutional neural networks (one per MRI sequence) learnt to map individual brain scans to their corresponding text vector representations by optimising a mean square error loss. Once trained, our text-vision framework can be used to detect abnormalities in unreported brain MRI examinations by scoring scans against suitable query sentences (e.g., 'there is an acute stroke', 'there is hydrocephalus' etc.), enabling a range of classification-based applications including automated triage. Potentially, our framework could also serve as a clinical decision support tool, not only by suggesting findings to radiologists and detecting errors in provisional reports, but also by retrieving and displaying examples of pathologies from historical examinations that could be relevant to the current case based on textual descriptors.
Create account to get full access
Overview
- Researchers present a self-supervised text-vision framework that learns to detect abnormalities in brain MRI scans by leveraging neuroradiology reports
- This approach addresses challenges with existing medical image recognition models that rely on time-consuming, categorically-labeled datasets
- The framework first trains a specialized language model (NeuroBERT) to encode neuroradiology reports, then trains computer vision models to map brain scans to these text representations
Plain English Explanation
The paper describes a new approach to analyzing medical images, specifically brain MRI scans, that aims to overcome some of the limitations of current state-of-the-art artificial neural network models.
Existing models are trained on large datasets of medical images that have been manually labeled by experts, categorizing them into predefined classes of abnormalities. While effective, this process of generating labeled datasets is time-consuming and restricts the models to only detecting the specific types of abnormalities they were trained on.
To address these challenges, the researchers developed a self-supervised text-vision framework that learns to detect clinically relevant brain abnormalities by directly leveraging the information contained in free-text neuroradiology reports.
The key steps are:
- Training a specialized language model called NeuroBERT to encode the meaning of neuroradiology reports into numerical vectors.
- Training computer vision models to map individual brain MRI scans to these text-based representations.
Once trained, this framework can be used to analyze new, unlabeled brain scans by comparing them to descriptive text about different types of abnormalities. This enables a range of applications, such as automated triage and clinical decision support, without the need for time-consuming manual labeling of medical images.
Technical Explanation
The core of the researchers' approach is a two-step training process. First, they train a specialized language model called NeuroBERT to generate fixed-dimensional vector representations of neuroradiology reports (a dataset of 50,523 reports) through domain-specific self-supervised learning tasks.
This NeuroBERT model learns to encode the rich textual information contained in the neuroradiology reports, capturing the semantic meanings and clinical concepts relevant to brain abnormalities.
In the second step, the researchers train a set of convolutional neural networks (one per MRI sequence) to map individual brain scans to their corresponding text-based vector representations. This is achieved by optimizing a mean squared error loss function to ensure the computer vision models accurately predict the text representations.
Once trained, this text-vision framework can be used to analyze new, unreported brain MRI scans. By scoring the scans against suitable query sentences (e.g., "there is an acute stroke", "there is hydrocephalus"), the system can detect the presence of clinically relevant abnormalities without relying on manually curated, categorically-labeled datasets.
The researchers envision this framework serving as a clinical decision support tool, not only by suggesting findings to radiologists and detecting errors in provisional reports, but also by retrieving and displaying examples of relevant pathologies from historical examinations based on textual descriptors.
Critical Analysis
The researchers acknowledge several limitations and avenues for future work. For instance, the performance of the text-vision framework may be constrained by the quality and comprehensiveness of the available neuroradiology reports, which could introduce biases or omissions. Additionally, the researchers note that further investigation is needed to understand the types of abnormalities the model can effectively detect and how its performance compares to human experts.
Another potential concern is the interpretability of the model's decision-making process. While the use of text-based representations allows for more flexibility and expressiveness compared to predefined classification categories, it may also make it more challenging to understand the underlying reasoning behind the model's predictions.
Future research could explore ways to enhance the transparency and explainability of the text-vision framework, potentially by incorporating additional techniques such as attention mechanisms or saliency maps.
Conclusion
The presented self-supervised text-vision framework represents a promising approach to addressing the limitations of existing medical image recognition models in the context of neuroradiology. By leveraging the rich information contained in free-text neuroradiology reports, the framework can learn to detect clinically relevant abnormalities in brain MRI scans without the need for time-consuming, manually-labeled datasets.
If further developed and validated, this technology could have significant implications for clinical practice, enabling more efficient and accurate automated triage, decision support, and knowledge retrieval capabilities. Continued research in this area has the potential to improve the accessibility and quality of medical image analysis, ultimately benefiting both healthcare professionals and patients.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
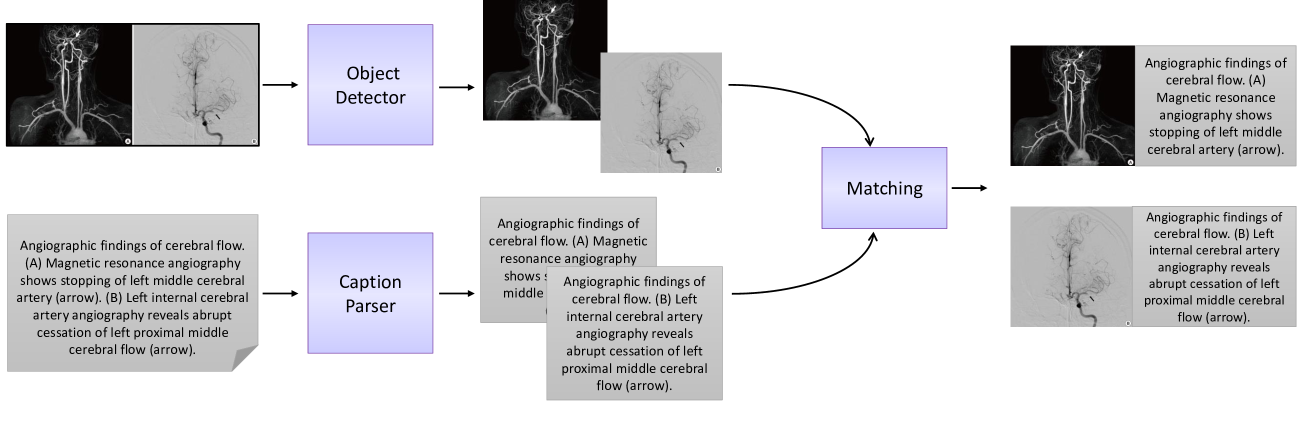
Medical Vision-Language Pre-Training for Brain Abnormalities
Masoud Monajatipoor, Zi-Yi Dou, Aichi Chien, Nanyun Peng, Kai-Wei Chang
0
0
Vision-language models have become increasingly powerful for tasks that require an understanding of both visual and linguistic elements, bridging the gap between these modalities. In the context of multimodal clinical AI, there is a growing need for models that possess domain-specific knowledge, as existing models often lack the expertise required for medical applications. In this paper, we take brain abnormalities as an example to demonstrate how to automatically collect medical image-text aligned data for pretraining from public resources such as PubMed. In particular, we present a pipeline that streamlines the pre-training process by initially collecting a large brain image-text dataset from case reports and published journals and subsequently constructing a high-performance vision-language model tailored to specific medical tasks. We also investigate the unique challenge of mapping subfigures to subcaptions in the medical domain. We evaluated the resulting model with quantitative and qualitative intrinsic evaluations. The resulting dataset and our code can be found here https://github.com/masoud-monajati/MedVL_pretraining_pipeline
4/30/2024
🔎
Boosting Medical Image-based Cancer Detection via Text-guided Supervision from Reports
Guangyu Guo, Jiawen Yao, Yingda Xia, Tony C. W. Mok, Zhilin Zheng, Junwei Han, Le Lu, Dingwen Zhang, Jian Zhou, Ling Zhang
0
0
The absence of adequately sufficient expert-level tumor annotations hinders the effectiveness of supervised learning based opportunistic cancer screening on medical imaging. Clinical reports (that are rich in descriptive textual details) can offer a free lunch'' supervision information and provide tumor location as a type of weak label to cope with screening tasks, thus saving human labeling workloads, if properly leveraged. However, predicting cancer only using such weak labels can be very changeling since tumors are usually presented in small anatomical regions compared to the whole 3D medical scans. Weakly semi-supervised learning (WSSL) utilizes a limited set of voxel-level tumor annotations and incorporates alongside a substantial number of medical images that have only off-the-shelf clinical reports, which may strike a good balance between minimizing expert annotation workload and optimizing screening efficacy. In this paper, we propose a novel text-guided learning method to achieve highly accurate cancer detection results. Through integrating diagnostic and tumor location text prompts into the text encoder of a vision-language model (VLM), optimization of weakly supervised learning can be effectively performed in the latent space of VLM, thereby enhancing the stability of training. Our approach can leverage clinical knowledge by large-scale pre-trained VLM to enhance generalization ability, and produce reliable pseudo tumor masks to improve cancer detection. Our extensive quantitative experimental results on a large-scale cancer dataset, including 1,651 unique patients, validate that our approach can reduce human annotation efforts by at least 70% while maintaining comparable cancer detection accuracy to competing fully supervised methods (AUC value 0.961 versus 0.966).
5/24/2024
🔎
Artificial intelligence for abnormality detection in high volume neuroimaging: a systematic review and meta-analysis
Siddharth Agarwal, David A. Wood, Mariusz Grzeda, Chandhini Suresh, Munaib Din, James Cole, Marc Modat, Thomas C Booth
0
0
Purpose: Most studies evaluating artificial intelligence (AI) models that detect abnormalities in neuroimaging are either tested on unrepresentative patient cohorts or are insufficiently well-validated, leading to poor generalisability to real-world tasks. The aim was to determine the diagnostic test accuracy and summarise the evidence supporting the use of AI models performing first-line, high-volume neuroimaging tasks. Methods: Medline, Embase, Cochrane library and Web of Science were searched until September 2021 for studies that temporally or externally validated AI capable of detecting abnormalities in first-line CT or MR neuroimaging. A bivariate random-effects model was used for meta-analysis where appropriate. PROSPERO: CRD42021269563. Results: Only 16 studies were eligible for inclusion. Included studies were not compromised by unrepresentative datasets or inadequate validation methodology. Direct comparison with radiologists was available in 4/16 studies. 15/16 had a high risk of bias. Meta-analysis was only suitable for intracranial haemorrhage detection in CT imaging (10/16 studies), where AI systems had a pooled sensitivity and specificity 0.90 (95% CI 0.85 - 0.94) and 0.90 (95% CI 0.83 - 0.95) respectively. Other AI studies using CT and MRI detected target conditions other than haemorrhage (2/16), or multiple target conditions (4/16). Only 3/16 studies implemented AI in clinical pathways, either for pre-read triage or as post-read discrepancy identifiers. Conclusion: The paucity of eligible studies reflects that most abnormality detection AI studies were not adequately validated in representative clinical cohorts. The few studies describing how abnormality detection AI could impact patients and clinicians did not explore the full ramifications of clinical implementation.
5/10/2024

Self-supervised Brain Lesion Generation for Effective Data Augmentation of Medical Images
Jiayu Huo, Sebastien Ourselin, Rachel Sparks
0
0
Accurate brain lesion delineation is important for planning neurosurgical treatment. Automatic brain lesion segmentation methods based on convolutional neural networks have demonstrated remarkable performance. However, neural network performance is constrained by the lack of large-scale well-annotated training datasets. In this manuscript, we propose a comprehensive framework to efficiently generate new, realistic samples for training a brain lesion segmentation model. We first train a lesion generator, based on an adversarial autoencoder, in a self-supervised manner. Next, we utilize a novel image composition algorithm, Soft Poisson Blending, to seamlessly combine synthetic lesions and brain images to obtain training samples. Finally, to effectively train the brain lesion segmentation model with augmented images we introduce a new prototype consistence regularization to align real and synthetic features. Our framework is validated by extensive experiments on two public brain lesion segmentation datasets: ATLAS v2.0 and Shift MS. Our method outperforms existing brain image data augmentation schemes. For instance, our method improves the Dice from 50.36% to 60.23% compared to the U-Net with conventional data augmentation techniques for the ATLAS v2.0 dataset.
6/24/2024