Self-supervised vision-langage alignment of deep learning representations for bone X-rays analysis
2405.08932
0
0

Abstract
This paper proposes leveraging vision-language pretraining on bone X-rays paired with French reports to address downstream tasks of interest on bone radiography. A practical processing pipeline is introduced to anonymize and process French medical reports. Pretraining then consists in the self-supervised alignment of visual and textual embedding spaces derived from deep model encoders. The resulting image encoder is then used to handle various downstream tasks, including quantification of osteoarthritis, estimation of bone age on pediatric wrists, bone fracture and anomaly detection. Our approach demonstrates competitive performance on downstream tasks, compared to alternatives requiring a significantly larger amount of human expert annotations. Our work stands as the first study to integrate French reports to shape the embedding space devoted to bone X-Rays representations, capitalizing on the large quantity of paired images and reports data available in an hospital. By relying on generic vision-laguage deep models in a language-specific scenario, it contributes to the deployement of vision models for wider healthcare applications.
Create account to get full access
Related Work
Vision-Language Pre-training for Medical Imaging
Recent research has explored the use of self-supervised vision-language pre-training to learn rich representations from large-scale medical imaging datasets and text corpora. These approaches can capture meaningful connections between visual features and clinical concepts, enabling improved performance on downstream medical vision tasks.
Robust X-ray Analysis
Efforts have also been made to develop robust X-ray analysis models that can handle variations in image quality, anatomy, and radiological findings. By incorporating specialized architectures and training strategies, these models aim to improve generalization and reliability in real-world clinical settings.
Structured Medical Knowledge Representation
Researchers have explored ways to represent medical knowledge in a structured, faceted manner to enhance the interpretability and performance of medical vision systems. This can involve integrating domain-specific ontologies and knowledge bases with deep learning models.
Language Models for Medical Applications
The use of large language models fine-tuned on medical text corpora has shown promise for tasks like clinical question answering, medical image captioning, and knowledge-guided radiological interpretation. These models can leverage rich textual information to complement visual understanding.
Multimodal Fusion for Medical Imaging
Recent work has explored grounded, knowledge-enhanced multimodal approaches that jointly leverage visual, textual, and structured knowledge for medical imaging tasks. By aligning different modalities, these models can capture more comprehensive and clinically relevant representations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔗
Pre-training on High Definition X-ray Images: An Experimental Study
Xiao Wang, Yuehang Li, Wentao Wu, Jiandong Jin, Yao Rong, Bo Jiang, Chuanfu Li, Jin Tang
0
0
Existing X-ray based pre-trained vision models are usually conducted on a relatively small-scale dataset (less than 500k samples) with limited resolution (e.g., 224 $times$ 224). However, the key to the success of self-supervised pre-training large models lies in massive training data, and maintaining high resolution in the field of X-ray images is the guarantee of effective solutions to difficult miscellaneous diseases. In this paper, we address these issues by proposing the first high-definition (1280 $times$ 1280) X-ray based pre-trained foundation vision model on our newly collected large-scale dataset which contains more than 1 million X-ray images. Our model follows the masked auto-encoder framework which takes the tokens after mask processing (with a high rate) is used as input, and the masked image patches are reconstructed by the Transformer encoder-decoder network. More importantly, we introduce a novel context-aware masking strategy that utilizes the chest contour as a boundary for adaptive masking operations. We validate the effectiveness of our model on two downstream tasks, including X-ray report generation and disease recognition. Extensive experiments demonstrate that our pre-trained medical foundation vision model achieves comparable or even new state-of-the-art performance on downstream benchmark datasets. The source code and pre-trained models of this paper will be released on https://github.com/Event-AHU/Medical_Image_Analysis.
4/30/2024
🤖
Advancing human-centric AI for robust X-ray analysis through holistic self-supervised learning
Th'eo Moutakanni, Piotr Bojanowski, Guillaume Chassagnon, C'eline Hudelot, Armand Joulin, Yann LeCun, Matthew Muckley, Maxime Oquab, Marie-Pierre Revel, Maria Vakalopoulou
0
0
AI Foundation models are gaining traction in various applications, including medical fields like radiology. However, medical foundation models are often tested on limited tasks, leaving their generalisability and biases unexplored. We present RayDINO, a large visual encoder trained by self-supervision on 873k chest X-rays. We compare RayDINO to previous state-of-the-art models across nine radiology tasks, from classification and dense segmentation to text generation, and provide an in depth analysis of population, age and sex biases of our model. Our findings suggest that self-supervision allows patient-centric AI proving useful in clinical workflows and interpreting X-rays holistically. With RayDINO and small task-specific adapters, we reach state-of-the-art results and improve generalization to unseen populations while mitigating bias, illustrating the true promise of foundation models: versatility and robustness.
5/3/2024

DeViDe: Faceted medical knowledge for improved medical vision-language pre-training
Haozhe Luo, Ziyu Zhou, Corentin Royer, Anjany Sekuboyina, Bjoern Menze
0
0
Vision-language pre-training for chest X-rays has made significant strides, primarily by utilizing paired radiographs and radiology reports. However, existing approaches often face challenges in encoding medical knowledge effectively. While radiology reports provide insights into the current disease manifestation, medical definitions (as used by contemporary methods) tend to be overly abstract, creating a gap in knowledge. To address this, we propose DeViDe, a novel transformer-based method that leverages radiographic descriptions from the open web. These descriptions outline general visual characteristics of diseases in radiographs, and when combined with abstract definitions and radiology reports, provide a holistic snapshot of knowledge. DeViDe incorporates three key features for knowledge-augmented vision language alignment: First, a large-language model-based augmentation is employed to homogenise medical knowledge from diverse sources. Second, this knowledge is aligned with image information at various levels of granularity. Third, a novel projection layer is proposed to handle the complexity of aligning each image with multiple descriptions arising in a multi-label setting. In zero-shot settings, DeViDe performs comparably to fully supervised models on external datasets and achieves state-of-the-art results on three large-scale datasets. Additionally, fine-tuning DeViDe on four downstream tasks and six segmentation tasks showcases its superior performance across data from diverse distributions.
4/5/2024
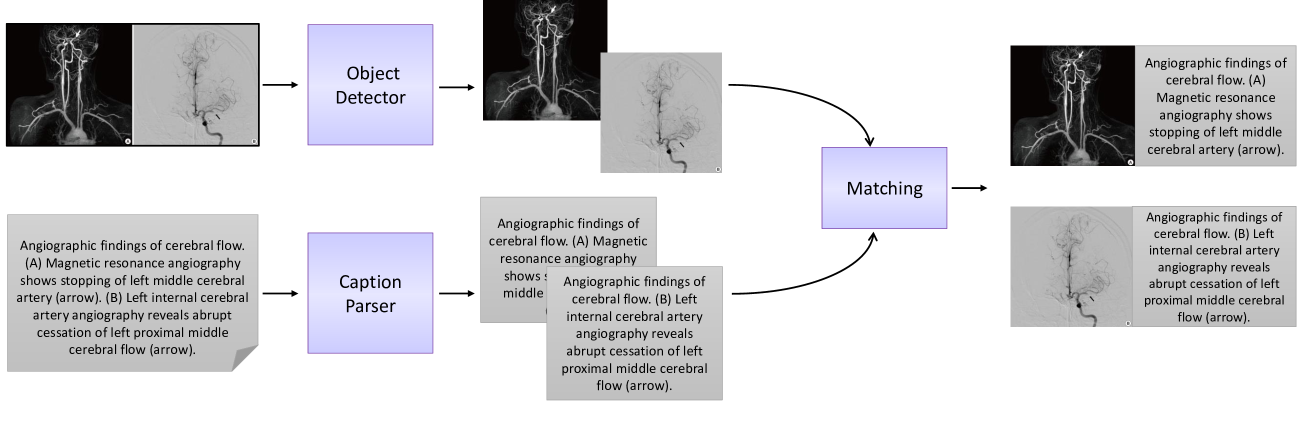
Medical Vision-Language Pre-Training for Brain Abnormalities
Masoud Monajatipoor, Zi-Yi Dou, Aichi Chien, Nanyun Peng, Kai-Wei Chang
0
0
Vision-language models have become increasingly powerful for tasks that require an understanding of both visual and linguistic elements, bridging the gap between these modalities. In the context of multimodal clinical AI, there is a growing need for models that possess domain-specific knowledge, as existing models often lack the expertise required for medical applications. In this paper, we take brain abnormalities as an example to demonstrate how to automatically collect medical image-text aligned data for pretraining from public resources such as PubMed. In particular, we present a pipeline that streamlines the pre-training process by initially collecting a large brain image-text dataset from case reports and published journals and subsequently constructing a high-performance vision-language model tailored to specific medical tasks. We also investigate the unique challenge of mapping subfigures to subcaptions in the medical domain. We evaluated the resulting model with quantitative and qualitative intrinsic evaluations. The resulting dataset and our code can be found here https://github.com/masoud-monajati/MedVL_pretraining_pipeline
4/30/2024