Grounded Knowledge-Enhanced Medical VLP for Chest X-Ray
2404.14750
0
0
🔗
Abstract
Medical vision-language pre-training has emerged as a promising approach for learning domain-general representations of medical image and text. Current algorithms that exploit the global and local alignment between medical image and text could however be marred by the redundant information in medical data. To address this issue, we propose a grounded knowledge-enhanced medical vision-language pre-training (GK-MVLP) framework for chest X-ray. In this framework, medical knowledge is grounded to the appropriate anatomical regions by using a transformer-based grounded knowledge-enhanced module for fine-grained alignment between anatomical region-level visual features and the textural features of medical knowledge. The performance of GK-MVLP is competitive with or exceeds the state of the art on downstream chest X-ray disease classification, disease localization, report generation, and medical visual question-answering tasks. Our results show the advantage of incorporating grounding mechanism to remove biases and improve the alignment between chest X-ray image and radiology report.
Create account to get full access
Overview
- The paper proposes a new framework called "Grounded Knowledge-Enhanced Medical Vision-Language Pre-training (GK-MVLP)" for chest X-ray analysis.
- The key idea is to incorporate medical knowledge and ground it to the appropriate anatomical regions in the X-ray images, improving the alignment between the images and associated text.
- This is done using a transformer-based module that aligns visual features of anatomical regions with the textual features of the medical knowledge.
- The framework outperforms state-of-the-art models on various chest X-ray tasks like disease classification, localization, report generation, and question-answering.
Plain English Explanation
The paper introduces a new approach for teaching AI systems to better understand medical images and the associated text, like radiology reports. Current algorithms try to match the overall image and text, but this can be challenging because medical data often contains a lot of repetitive or redundant information.
To address this, the researchers propose a framework called "Grounded Knowledge-Enhanced Medical Vision-Language Pre-training (GK-MVLP)". The key innovation is that they "ground" the medical knowledge to specific anatomical regions in the X-ray images. This means they use a special module to closely align the visual features of the different body parts with the textual descriptions of those parts.
By doing this, the AI system can better understand the relationship between what it sees in the image and what is described in the text. This leads to improved performance on a variety of medical imaging tasks, like identifying diseases, localizing problems, generating reports, and answering questions about the images.
The key benefit of this approach is that it helps the AI system remove biases and better align the information in the images and text, leading to more robust and accurate medical image understanding.
Technical Explanation
The core innovation of the GK-MVLP framework is the use of a transformer-based "Grounded Knowledge-Enhanced Module" that explicitly aligns the visual features of anatomical regions in the chest X-ray images with the textual features of relevant medical knowledge.
This module takes the visual features extracted from the X-ray image and the textual features from the medical knowledge base as input. It then uses transformer layers to learn fine-grained correspondences between the visual and textual features, effectively "grounding" the medical knowledge to the appropriate anatomical areas.
This grounding mechanism is critical, as it helps address the issue of redundant information in medical data that can confuse standard vision-language pre-training approaches, as mentioned in related work.
The resulting GK-MVLP framework is pre-trained on a large corpus of chest X-ray images and associated radiology reports, leveraging the grounded knowledge module to learn powerful representations. These pre-trained representations are then fine-tuned on various downstream tasks, including disease classification, localization, report generation, and visual question-answering.
The experiments show that the GK-MVLP framework outperforms or matches state-of-the-art models on these diverse medical imaging tasks, highlighting the advantages of incorporating the grounding mechanism to remove biases and improve the alignment between chest X-ray images and radiology reports.
Critical Analysis
The paper presents a compelling approach for improving medical vision-language models by grounding the medical knowledge to specific anatomical regions in the images. This is a thoughtful solution to the challenge of redundant information in medical data that can confuse standard vision-language pre-training.
One potential limitation is the reliance on having access to a comprehensive medical knowledge base that can be aligned with the image features. The performance of the grounding mechanism may be sensitive to the quality and coverage of the available knowledge base.
Additionally, the paper does not delve deeply into potential biases or limitations in the training data, which could be an important consideration for real-world deployment of such systems. Further research may be needed to assess the robustness of the approach to variations in imaging protocols, patient demographics, and other confounding factors.
Overall, the GK-MVLP framework represents an interesting and promising direction for advancing medical image understanding. By explicitly modeling the connections between visual and textual features, it offers a compelling approach to enhance the performance and interpretability of AI systems in this critical domain.
Conclusion
The proposed Grounded Knowledge-Enhanced Medical Vision-Language Pre-training (GK-MVLP) framework introduces a novel way to improve the alignment between medical images and associated text by grounding the medical knowledge to the appropriate anatomical regions in the images.
This grounding mechanism helps address the challenge of redundant information in medical data, leading to state-of-the-art performance on a range of chest X-ray analysis tasks, including disease classification, localization, report generation, and visual question-answering.
The success of this approach highlights the importance of incorporating domain-specific knowledge and fine-grained alignment between visual and textual features for advancing medical image understanding. As AI systems continue to play an increasingly important role in healthcare, innovations like GK-MVLP will be crucial for developing trustworthy and effective medical imaging tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CT-GLIP: 3D Grounded Language-Image Pretraining with CT Scans and Radiology Reports for Full-Body Scenarios
Jingyang Lin, Yingda Xia, Jianpeng Zhang, Ke Yan, Le Lu, Jiebo Luo, Ling Zhang
0
0
Medical Vision-Language Pretraining (Med-VLP) establishes a connection between visual content from medical images and the relevant textual descriptions. Existing Med-VLP methods primarily focus on 2D images depicting a single body part, notably chest X-rays. In this paper, we extend the scope of Med-VLP to encompass 3D images, specifically targeting full-body scenarios, by using a multimodal dataset of CT images and reports. Compared with the 2D counterpart, 3D VLP is required to effectively capture essential semantics from significantly sparser representation in 3D imaging. In this paper, we introduce CT-GLIP (Grounded Language-Image Pretraining with CT scans), a novel method that constructs organ-level image-text pairs to enhance multimodal contrastive learning, aligning grounded visual features with precise diagnostic text. Additionally, we developed an abnormality dictionary to augment contrastive learning with diverse contrastive pairs. Our method, trained on a multimodal CT dataset comprising 44,011 organ-level vision-text pairs from 17,702 patients across 104 organs, demonstrates it can identify organs and abnormalities in a zero-shot manner using natural languages. The performance of CT-GLIP is validated on a separate test set of 1,130 patients, focusing on the 16 most frequent abnormalities across 7 organs. The experimental results show our model's superior performance over the standard CLIP framework across zero-shot and fine-tuning scenarios, using both CNN and ViT architectures.
4/30/2024

Learning Generalized Medical Image Representations through Image-Graph Contrastive Pretraining
Sameer Khanna, Daniel Michael, Marinka Zitnik, Pranav Rajpurkar
0
0
Medical image interpretation using deep learning has shown promise but often requires extensive expert-annotated datasets. To reduce this annotation burden, we develop an Image-Graph Contrastive Learning framework that pairs chest X-rays with structured report knowledge graphs automatically extracted from radiology notes. Our approach uniquely encodes the disconnected graph components via a relational graph convolution network and transformer attention. In experiments on the CheXpert dataset, this novel graph encoding strategy enabled the framework to outperform existing methods that use image-text contrastive learning in 1% linear evaluation and few-shot settings, while achieving comparable performance to radiologists. By exploiting unlabeled paired images and text, our framework demonstrates the potential of structured clinical insights to enhance contrastive learning for medical images. This work points toward reducing demands on medical experts for annotations, improving diagnostic precision, and advancing patient care through robust medical image understanding.
5/17/2024
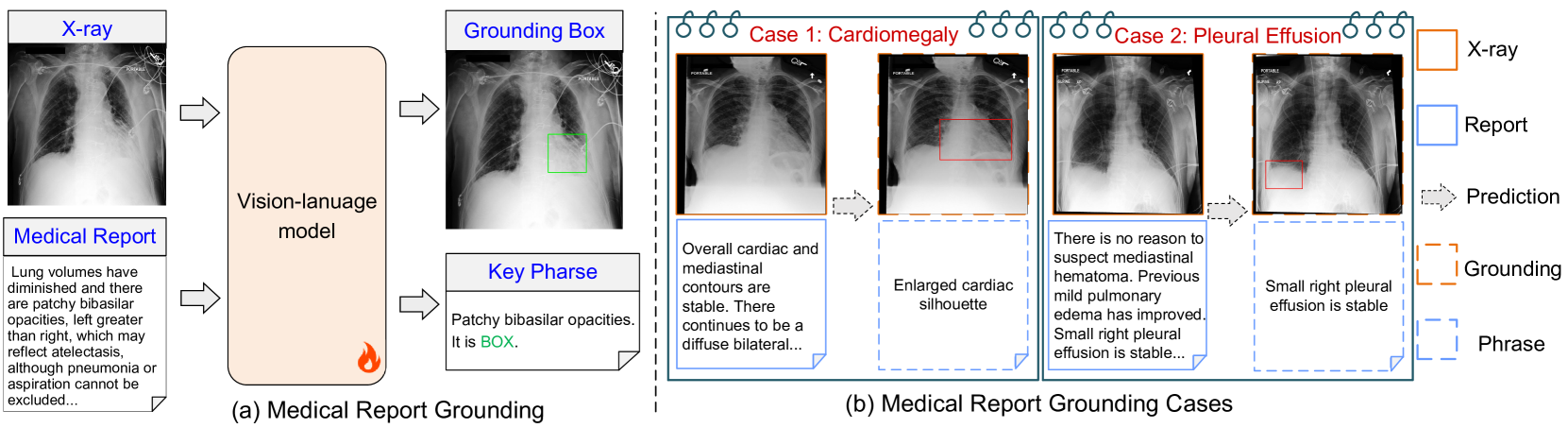
MedRG: Medical Report Grounding with Multi-modal Large Language Model
Ke Zou, Yang Bai, Zhihao Chen, Yang Zhou, Yidi Chen, Kai Ren, Meng Wang, Xuedong Yuan, Xiaojing Shen, Huazhu Fu
0
0
Medical Report Grounding is pivotal in identifying the most relevant regions in medical images based on a given phrase query, a critical aspect in medical image analysis and radiological diagnosis. However, prevailing visual grounding approaches necessitate the manual extraction of key phrases from medical reports, imposing substantial burdens on both system efficiency and physicians. In this paper, we introduce a novel framework, Medical Report Grounding (MedRG), an end-to-end solution for utilizing a multi-modal Large Language Model to predict key phrase by incorporating a unique token, BOX, into the vocabulary to serve as an embedding for unlocking detection capabilities. Subsequently, the vision encoder-decoder jointly decodes the hidden embedding and the input medical image, generating the corresponding grounding box. The experimental results validate the effectiveness of MedRG, surpassing the performance of the existing state-of-the-art medical phrase grounding methods. This study represents a pioneering exploration of the medical report grounding task, marking the first-ever endeavor in this domain.
4/11/2024

Pretraining Vision-Language Model for Difference Visual Question Answering in Longitudinal Chest X-rays
Yeongjae Cho, Taehee Kim, Heejun Shin, Sungzoon Cho, Dongmyung Shin
0
0
Difference visual question answering (diff-VQA) is a challenging task that requires answering complex questions based on differences between a pair of images. This task is particularly important in reading chest X-ray images because radiologists often compare multiple images of the same patient taken at different times to track disease progression and changes in its severity in their clinical practice. However, previous works focused on designing specific network architectures for the diff-VQA task, missing opportunities to enhance the model's performance using a pretrained vision-language model (VLM). Here, we introduce a novel VLM called PLURAL, which is pretrained on natural and longitudinal chest X-ray data for the diff-VQA task. The model is developed using a step-by-step approach, starting with being pretrained on natural images and texts, followed by being trained using longitudinal chest X-ray data. The longitudinal data consist of pairs of X-ray images, along with question-answer sets and radiologist's reports that describe the changes in lung abnormalities and diseases over time. Our experimental results show that the PLURAL model outperforms state-of-the-art methods not only in diff-VQA for longitudinal X-rays but also in conventional VQA for a single X-ray image. Through extensive experiments, we demonstrate the effectiveness of the proposed VLM architecture and pretraining method in improving the model's performance.
6/18/2024