Self-Training Large Language Models for Improved Visual Program Synthesis With Visual Reinforcement
2404.04627
0
0

Abstract
Visual program synthesis is a promising approach to exploit the reasoning abilities of large language models for compositional computer vision tasks. Previous work has used few-shot prompting with frozen LLMs to synthesize visual programs. Training an LLM to write better visual programs is an attractive prospect, but it is unclear how to accomplish this. No dataset of visual programs for training exists, and acquisition of a visual program dataset cannot be easily crowdsourced due to the need for expert annotators. To get around the lack of direct supervision, we explore improving the program synthesis abilities of an LLM using feedback from interactive experience. We propose a method where we exploit existing annotations for a vision-language task to improvise a coarse reward signal for that task, treat the LLM as a policy, and apply reinforced self-training to improve the visual program synthesis ability of the LLM for that task. We describe a series of experiments on object detection, compositional visual question answering, and image-text retrieval, and show that in each case, the self-trained LLM outperforms or performs on par with few-shot frozen LLMs that are an order of magnitude larger. Website: https://zaidkhan.me/ViReP
Create account to get full access
Overview
- This paper explores a novel approach to improve the visual program synthesis capabilities of large language models through self-training and visual reinforcement.
- The researchers developed a framework that allows large language models to learn from their own synthesis outputs, iteratively refining their abilities to generate accurate and executable programs for various visual tasks.
- The approach leverages the inherent flexibility and representational power of large language models, combined with the use of visual feedback to guide and enhance their learning.
Plain English Explanation
The paper describes a new way to make large language models better at generating computer programs that can perform visual tasks. Large language models are powerful AI systems that can understand and generate human-like text. However, they often struggle with tasks that require more specific, technical abilities, such as writing code.
The researchers in this paper came up with a solution to this problem. They developed a method that allows large language models to learn from their own attempts at generating visual programs. The models can analyze their own outputs, identify areas for improvement, and then refine their skills through an iterative process of self-training. This is aided by providing the models with visual feedback, which helps them understand how well their generated programs are performing the desired visual tasks.
By leveraging the inherent flexibility and broad knowledge of large language models, and combining it with targeted visual feedback, the researchers were able to significantly improve the models' abilities to synthesize accurate and executable programs for a variety of visual tasks. This approach could have important applications in areas like automated software generation, visual task automation, and even creative coding.
Technical Explanation
The key technical elements of this paper include:
-
Self-Training Framework: The researchers developed a self-training framework that allows large language models to learn from their own synthesis outputs. The models generate programs, execute them, and then use the visual feedback to refine their program generation capabilities.
-
Visual Reinforcement: The self-training process is guided by visual reinforcement, where the models receive feedback on the performance of their generated programs in the form of visual metrics or rewards. This helps the models understand how to improve their program synthesis abilities.
-
Architecture Design: The paper explores different architectural choices, such as incorporating visual feedback directly into the language model's training process or using separate modules for program synthesis and visual evaluation.
-
Benchmark Evaluation: The researchers evaluated their approach on several benchmark tasks for visual program synthesis, demonstrating significant performance improvements compared to previous methods.
-
Generalization and Scalability: The authors also investigated the ability of their self-training framework to generalize to new, unseen tasks and its scalability to larger language models.
Critical Analysis
The paper presents a promising approach to enhancing the visual program synthesis capabilities of large language models. However, the researchers acknowledge several caveats and areas for further exploration:
-
Computational Complexity: The self-training process can be computationally intensive, as it requires repeatedly generating and evaluating programs. Optimizing the efficiency of this process will be important for real-world applications.
-
Generalization Limits: While the framework demonstrated strong performance on the benchmark tasks, the researchers note that further work is needed to understand the limits of its generalization abilities to more diverse and complex visual domains.
-
Interpretability and Transparency: As with many large language models, the inner workings of the self-training process may be opaque, making it challenging to understand the specific mechanisms driving the performance improvements. Enhancing the interpretability of the approach could be valuable.
-
Potential Biases: The self-training process may amplify any biases present in the initial language model or the visual feedback data. Addressing these biases and ensuring fairness and inclusivity will be an important consideration for future research.
Conclusion
This paper presents a novel approach to enhancing the visual program synthesis capabilities of large language models through self-training and visual reinforcement. By leveraging the inherent flexibility and representational power of these models, combined with targeted visual feedback, the researchers were able to demonstrate significant improvements in the ability to generate accurate and executable programs for a variety of visual tasks.
The implications of this work are potentially far-reaching, as it could lead to advancements in areas such as automated software generation, visual task automation, and even creative coding. While the approach has some caveats and areas for further exploration, the overall findings suggest that this line of research holds promise for expanding the capabilities of large language models and pushing the boundaries of what is possible in the realm of AI-driven visual programming.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Enhancing Large Vision Language Models with Self-Training on Image Comprehension
Yihe Deng, Pan Lu, Fan Yin, Ziniu Hu, Sheng Shen, James Zou, Kai-Wei Chang, Wei Wang
0
0
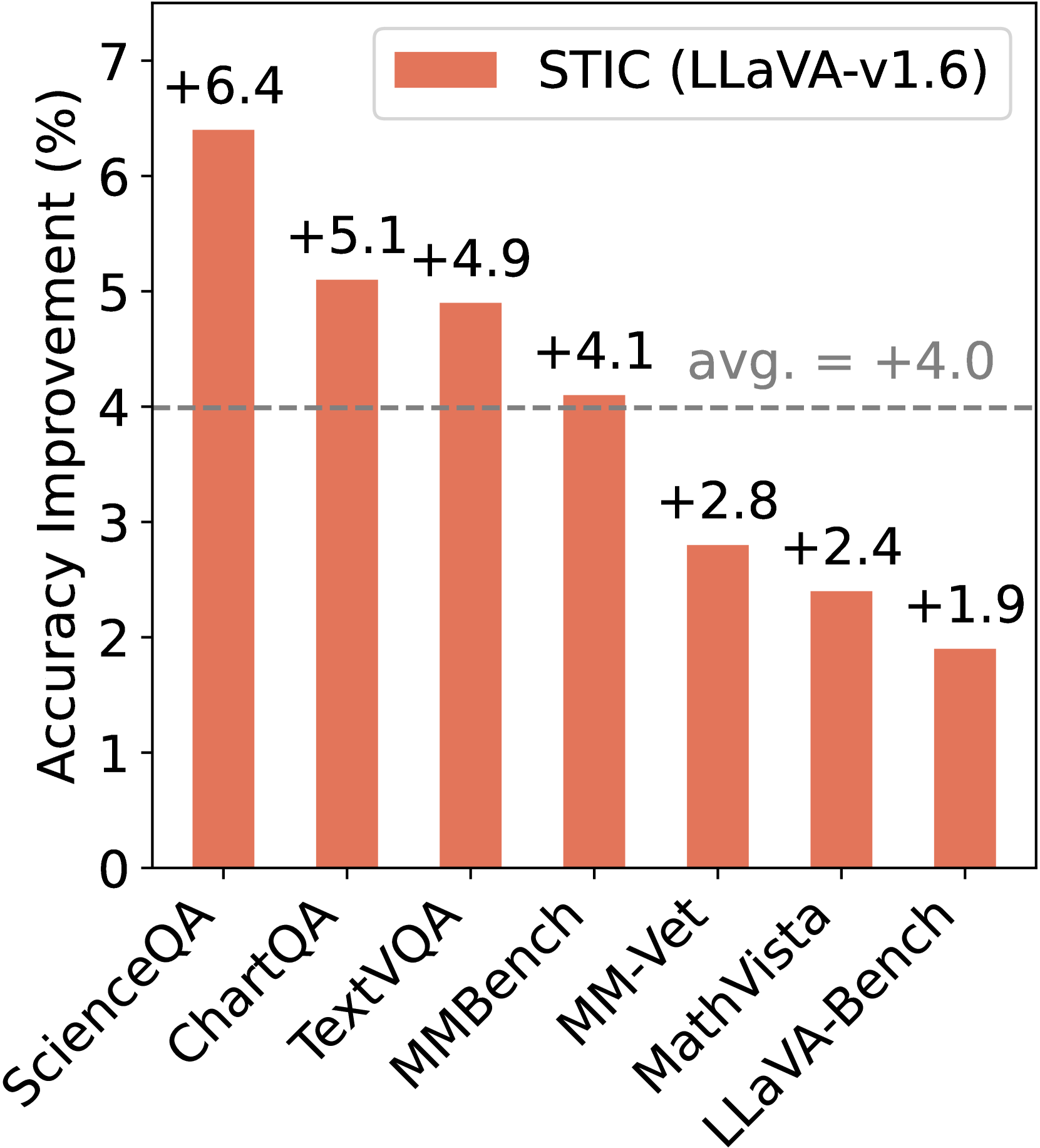
Large vision language models (LVLMs) integrate large language models (LLMs) with pre-trained vision encoders, thereby activating the perception capability of the model to understand image inputs for different queries and conduct subsequent reasoning. Improving this capability requires high-quality vision-language data, which is costly and labor-intensive to acquire. Self-training approaches have been effective in single-modal settings to alleviate the need for labeled data by leveraging model's own generation. However, effective self-training remains a challenge regarding the unique visual perception and reasoning capability of LVLMs. To address this, we introduce Self-Training on Image Comprehension (STIC), which emphasizes a self-training approach specifically for image comprehension. First, the model self-constructs a preference dataset for image descriptions using unlabeled images. Preferred responses are generated through a step-by-step prompt, while dis-preferred responses are generated from either corrupted images or misleading prompts. To further self-improve reasoning on the extracted visual information, we let the model reuse a small portion of existing instruction-tuning data and append its self-generated image descriptions to the prompts. We validate the effectiveness of STIC across seven different benchmarks, demonstrating substantial performance gains of 4.0% on average while using 70% less supervised fine-tuning data than the current method. Further studies investigate various components of STIC and highlight its potential to leverage vast quantities of unlabeled images for self-training. Code and data are made publicly available.
5/31/2024
Large Language Models for In-Context Student Modeling: Synthesizing Student's Behavior in Visual Programming
Manh Hung Nguyen, Sebastian Tschiatschek, Adish Singla
0
0
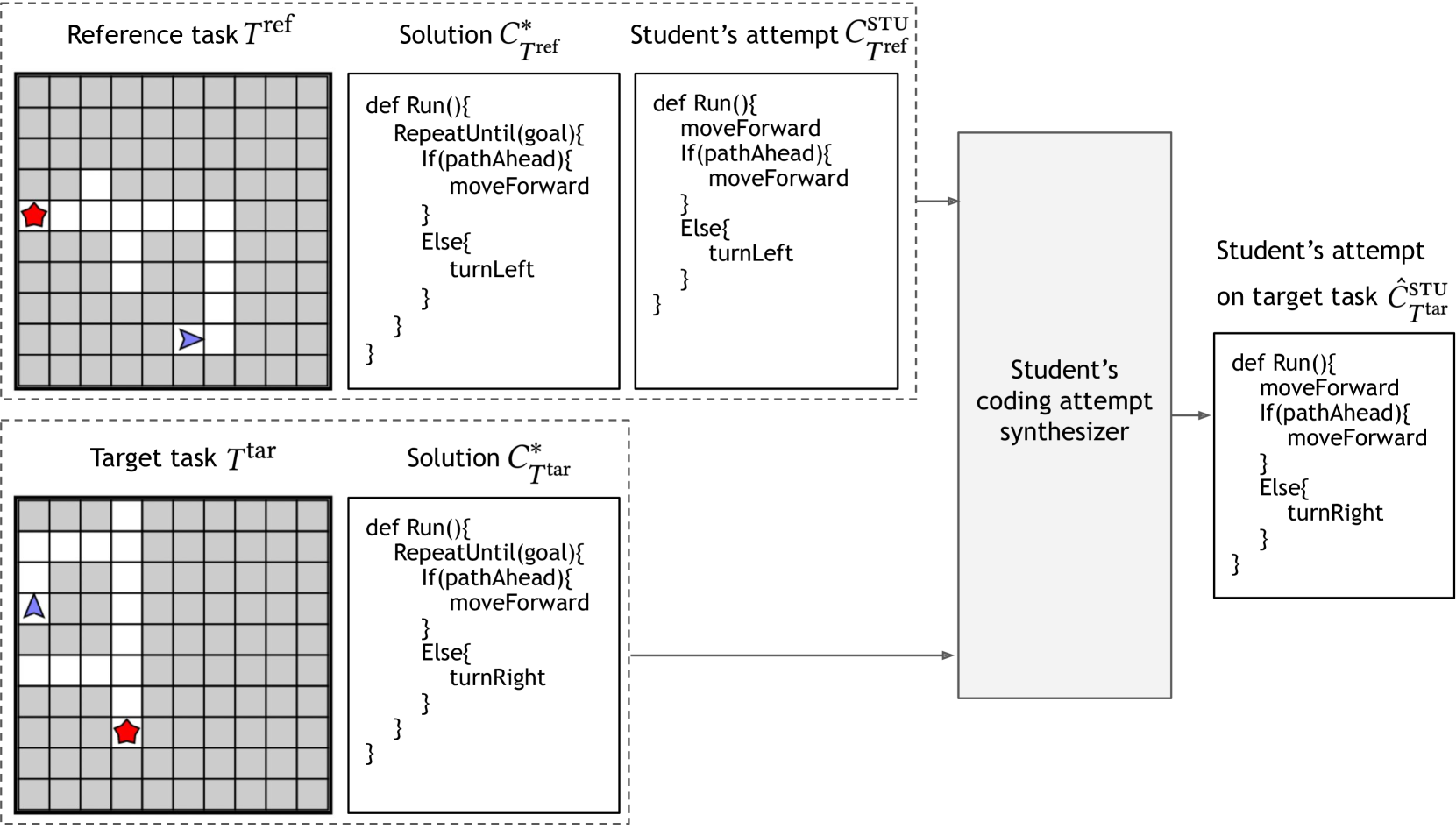
Student modeling is central to many educational technologies as it enables predicting future learning outcomes and designing targeted instructional strategies. However, open-ended learning domains pose challenges for accurately modeling students due to the diverse behaviors and a large space of possible misconceptions. To approach these challenges, we explore the application of large language models (LLMs) for in-context student modeling in open-ended learning domains. More concretely, given a particular student's attempt on a reference task as observation, the objective is to synthesize the student's attempt on a target task. We introduce a novel framework, LLM for Student Synthesis (LLM-SS), that leverages LLMs for synthesizing a student's behavior. Our framework can be combined with different LLMs; moreover, we fine-tune LLMs to boost their student modeling capabilities. We instantiate several methods based on LLM-SS framework and evaluate them using an existing benchmark, StudentSyn, for student attempt synthesis in a visual programming domain. Experimental results show that our methods perform significantly better than the baseline method NeurSS provided in the StudentSyn benchmark. Furthermore, our method using a fine-tuned version of the GPT-3.5 model is significantly better than using the base GPT-3.5 model and gets close to human tutors' performance.
5/7/2024
🏅
Vision-Language Models Provide Promptable Representations for Reinforcement Learning
William Chen, Oier Mees, Aviral Kumar, Sergey Levine
0
0
Humans can quickly learn new behaviors by leveraging background world knowledge. In contrast, agents trained with reinforcement learning (RL) typically learn behaviors from scratch. We thus propose a novel approach that uses the vast amounts of general and indexable world knowledge encoded in vision-language models (VLMs) pre-trained on Internet-scale data for embodied RL. We initialize policies with VLMs by using them as promptable representations: embeddings that encode semantic features of visual observations based on the VLM's internal knowledge and reasoning capabilities, as elicited through prompts that provide task context and auxiliary information. We evaluate our approach on visually-complex, long horizon RL tasks in Minecraft and robot navigation in Habitat. We find that our policies trained on embeddings from off-the-shelf, general-purpose VLMs outperform equivalent policies trained on generic, non-promptable image embeddings. We also find our approach outperforms instruction-following methods and performs comparably to domain-specific embeddings. Finally, we show that our approach can use chain-of-thought prompting to produce representations of common-sense semantic reasoning, improving policy performance in novel scenes by 1.5 times.
5/24/2024
👀
Calibrated Self-Rewarding Vision Language Models
Yiyang Zhou, Zhiyuan Fan, Dongjie Cheng, Sihan Yang, Zhaorun Chen, Chenhang Cui, Xiyao Wang, Yun Li, Linjun Zhang, Huaxiu Yao
0
0
Large Vision-Language Models (LVLMs) have made substantial progress by integrating pre-trained large language models (LLMs) and vision models through instruction tuning. Despite these advancements, LVLMs often exhibit the hallucination phenomenon, where generated text responses appear linguistically plausible but contradict the input image, indicating a misalignment between image and text pairs. This misalignment arises because the model tends to prioritize textual information over visual input, even when both the language model and visual representations are of high quality. Existing methods leverage additional models or human annotations to curate preference data and enhance modality alignment through preference optimization. These approaches may not effectively reflect the target LVLM's preferences, making the curated preferences easily distinguishable. Our work addresses these challenges by proposing the Calibrated Self-Rewarding (CSR) approach, which enables the model to self-improve by iteratively generating candidate responses, evaluating the reward for each response, and curating preference data for fine-tuning. In the reward modeling, we employ a step-wise strategy and incorporate visual constraints into the self-rewarding process to place greater emphasis on visual input. Empirical results demonstrate that CSR enhances performance and reduces hallucinations across ten benchmarks and tasks, achieving substantial improvements over existing methods by 7.62%. Our empirical results are further supported by rigorous theoretical analysis, under mild assumptions, verifying the effectiveness of introducing visual constraints into the self-rewarding paradigm. Additionally, CSR shows compatibility with different vision-language models and the ability to incrementally improve performance through iterative fine-tuning. Our data and code are available at https://github.com/YiyangZhou/CSR.
6/3/2024