Large Language Models for In-Context Student Modeling: Synthesizing Student's Behavior in Visual Programming
2310.10690
0
0
Abstract
Student modeling is central to many educational technologies as it enables predicting future learning outcomes and designing targeted instructional strategies. However, open-ended learning domains pose challenges for accurately modeling students due to the diverse behaviors and a large space of possible misconceptions. To approach these challenges, we explore the application of large language models (LLMs) for in-context student modeling in open-ended learning domains. More concretely, given a particular student's attempt on a reference task as observation, the objective is to synthesize the student's attempt on a target task. We introduce a novel framework, LLM for Student Synthesis (LLM-SS), that leverages LLMs for synthesizing a student's behavior. Our framework can be combined with different LLMs; moreover, we fine-tune LLMs to boost their student modeling capabilities. We instantiate several methods based on LLM-SS framework and evaluate them using an existing benchmark, StudentSyn, for student attempt synthesis in a visual programming domain. Experimental results show that our methods perform significantly better than the baseline method NeurSS provided in the StudentSyn benchmark. Furthermore, our method using a fine-tuned version of the GPT-3.5 model is significantly better than using the base GPT-3.5 model and gets close to human tutors' performance.
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) for in-context student modeling in the context of visual programming.
- The researchers investigate how LLMs can be used to synthesize a student's behavior in visual programming tasks from a single observation.
- The goal is to enable more personalized and adaptive learning experiences for students in visual programming environments.
Plain English Explanation
The researchers in this study wanted to see if large language models (LLMs) - powerful AI systems trained on huge amounts of text data - could be used to better understand how students learn and behave when working on visual programming tasks.
Visual programming is a way of coding where you use visual elements like blocks or diagrams instead of just typing out text. The researchers thought that LLMs might be able to take a single observation of a student working on a visual programming task and then "synthesize" or re-create the student's full thought process and behavior.
This could be really useful for creating more personalized and adaptive learning experiences for students. If the system can understand how each individual student tackles problems, it could provide better feedback, guidance, and support tailored to their unique needs and learning style.
Technical Explanation
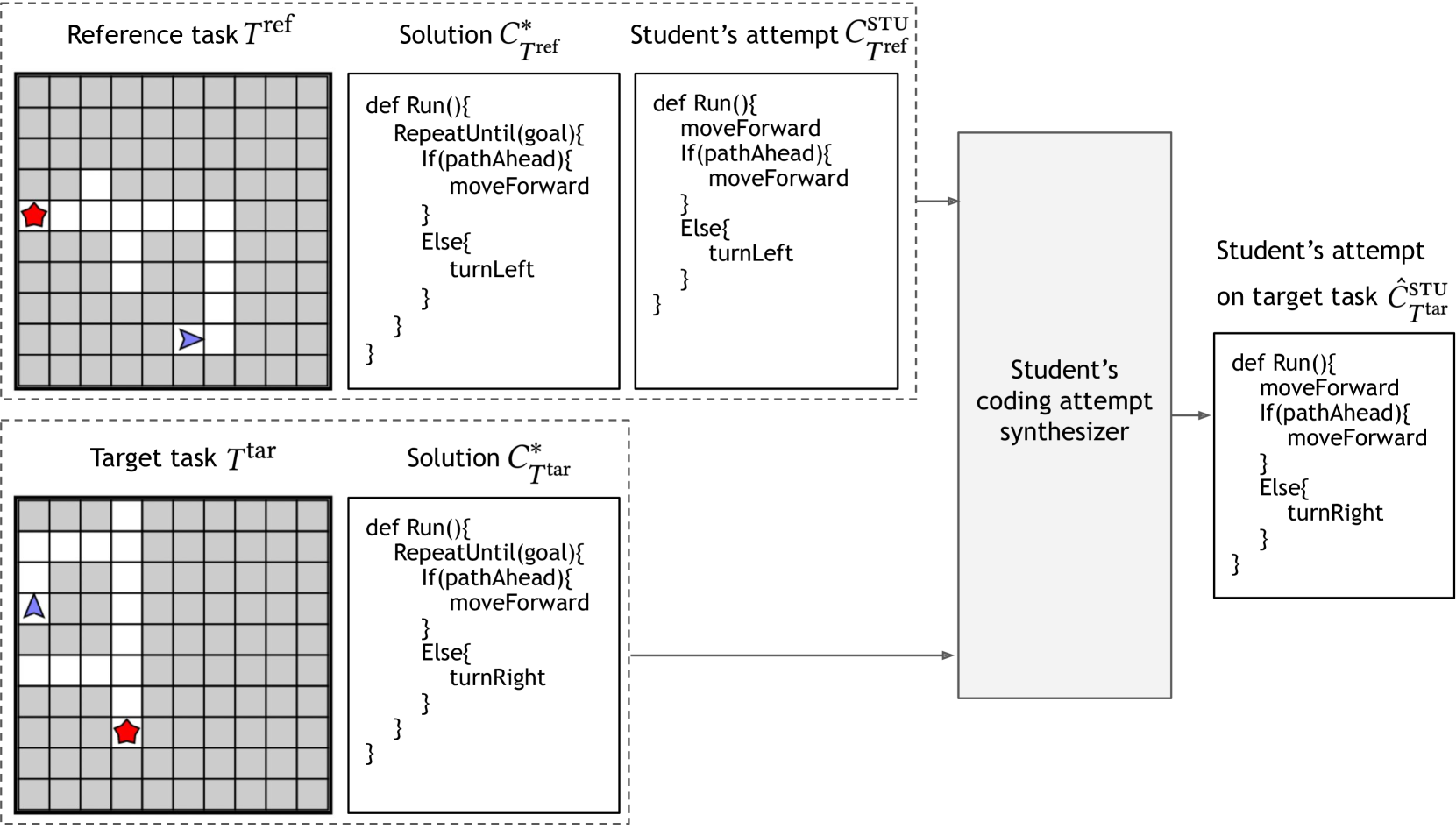
The paper explores the use of large language models for in-context student modeling in visual programming environments. The key idea is to leverage the powerful language understanding capabilities of LLMs to synthesize a student's full problem-solving behavior from a single observation.
The researchers formulate the task as a one-shot behavior synthesis problem. Given an initial observation of a student's actions in a visual programming environment, the goal is to generate a sequence of subsequent actions that plausibly continue the student's problem-solving process. To achieve this, the authors propose an LLM-based approach that encodes the initial observation and then iteratively generates likely next steps.
The paper presents experiments evaluating this approach on a dataset of student interactions in a visual programming environment. The results show that the LLM-based method can effectively reconstruct the students' full solution sequences from limited observations, outperforming baseline techniques. This suggests the potential of using LLMs to optimize educational content and experiences.
Critical Analysis
The paper makes a compelling case for the use of large language models in the context of student modeling for visual programming environments. The authors demonstrate the ability of LLMs to synthesize plausible student behaviors from a single observation, which could enable more personalized and adaptive learning experiences.
However, the study is limited to a specific visual programming environment and dataset. Further research would be needed to assess the generalizability of the approach to other programming domains and student populations. Additionally, the paper does not deeply explore potential biases or limitations that LLMs may introduce when modeling student behavior.
Future work could also investigate the potential of combining LLMs with other AI techniques, such as reinforcement learning or cognitive models, to further enhance the accuracy and interpretability of student behavior synthesis.
Conclusion
This paper presents a novel approach to student modeling in visual programming environments using large language models. The ability to synthesize a student's full problem-solving behavior from a single observation has significant potential to enable more personalized and adaptive learning experiences.
While the study demonstrates promising results, further research is needed to explore the broader applicability and potential limitations of this LLM-based approach. As the field of educational AI continues to evolve, this work highlights the exciting possibilities of leveraging powerful language models to better understand and support student learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Supervised Knowledge Makes Large Language Models Better In-context Learners
Linyi Yang, Shuibai Zhang, Zhuohao Yu, Guangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei Ye, Xing Xie, Weizhu Chen, Yue Zhang
0
0
Large Language Models (LLMs) exhibit emerging in-context learning abilities through prompt engineering. The recent progress in large-scale generative models has further expanded their use in real-world language applications. However, the critical challenge of improving the generalizability and factuality of LLMs in natural language understanding and question answering remains under-explored. While previous in-context learning research has focused on enhancing models to adhere to users' specific instructions and quality expectations, and to avoid undesired outputs, little to no work has explored the use of task-Specific fine-tuned Language Models (SLMs) to improve LLMs' in-context learning during the inference stage. Our primary contribution is the establishment of a simple yet effective framework that enhances the reliability of LLMs as it: 1) generalizes out-of-distribution data, 2) elucidates how LLMs benefit from discriminative models, and 3) minimizes hallucinations in generative tasks. Using our proposed plug-in method, enhanced versions of Llama 2 and ChatGPT surpass their original versions regarding generalizability and factuality. We offer a comprehensive suite of resources, including 16 curated datasets, prompts, model checkpoints, and LLM outputs across 9 distinct tasks. The code and data are released at: https://github.com/YangLinyi/Supervised-Knowledge-Makes-Large-Language-Models-Better-In-context-Learners. Our empirical analysis sheds light on the advantages of incorporating discriminative models into LLMs and highlights the potential of our methodology in fostering more reliable LLMs.
4/12/2024

AutoTutor meets Large Language Models: A Language Model Tutor with Rich Pedagogy and Guardrails
Sankalan Pal Chowdhury, Vil'em Zouhar, Mrinmaya Sachan
0
0
Large Language Models (LLMs) have found several use cases in education, ranging from automatic question generation to essay evaluation. In this paper, we explore the potential of using Large Language Models (LLMs) to author Intelligent Tutoring Systems. A common pitfall of LLMs is their straying from desired pedagogical strategies such as leaking the answer to the student, and in general, providing no guarantees. We posit that while LLMs with certain guardrails can take the place of subject experts, the overall pedagogical design still needs to be handcrafted for the best learning results. Based on this principle, we create a sample end-to-end tutoring system named MWPTutor, which uses LLMs to fill in the state space of a pre-defined finite state transducer. This approach retains the structure and the pedagogy of traditional tutoring systems that has been developed over the years by learning scientists but brings in additional flexibility of LLM-based approaches. Through a human evaluation study on two datasets based on math word problems, we show that our hybrid approach achieves a better overall tutoring score than an instructed, but otherwise free-form, GPT-4. MWPTutor is completely modular and opens up the scope for the community to improve its performance by improving individual modules or using different teaching strategies that it can follow.
4/26/2024
A review on the use of large language models as virtual tutors
Silvia Garc'ia-M'endez, Francisco de Arriba-P'erez, Mar'ia del Carmen Somoza-L'opez
0
0
Transformer architectures contribute to managing long-term dependencies for Natural Language Processing, representing one of the most recent changes in the field. These architectures are the basis of the innovative, cutting-edge Large Language Models (LLMs) that have produced a huge buzz in several fields and industrial sectors, among the ones education stands out. Accordingly, these generative Artificial Intelligence-based solutions have directed the change in techniques and the evolution in educational methods and contents, along with network infrastructure, towards high-quality learning. Given the popularity of LLMs, this review seeks to provide a comprehensive overview of those solutions designed specifically to generate and evaluate educational materials and which involve students and teachers in their design or experimental plan. To the best of our knowledge, this is the first review of educational applications (e.g., student assessment) of LLMs. As expected, the most common role of these systems is as virtual tutors for automatic question generation. Moreover, the most popular models are GTP-3 and BERT. However, due to the continuous launch of new generative models, new works are expected to be published shortly.
5/21/2024

Self-Training Large Language Models for Improved Visual Program Synthesis With Visual Reinforcement
Zaid Khan, Vijay Kumar BG, Samuel Schulter, Yun Fu, Manmohan Chandraker
0
0
Visual program synthesis is a promising approach to exploit the reasoning abilities of large language models for compositional computer vision tasks. Previous work has used few-shot prompting with frozen LLMs to synthesize visual programs. Training an LLM to write better visual programs is an attractive prospect, but it is unclear how to accomplish this. No dataset of visual programs for training exists, and acquisition of a visual program dataset cannot be easily crowdsourced due to the need for expert annotators. To get around the lack of direct supervision, we explore improving the program synthesis abilities of an LLM using feedback from interactive experience. We propose a method where we exploit existing annotations for a vision-language task to improvise a coarse reward signal for that task, treat the LLM as a policy, and apply reinforced self-training to improve the visual program synthesis ability of the LLM for that task. We describe a series of experiments on object detection, compositional visual question answering, and image-text retrieval, and show that in each case, the self-trained LLM outperforms or performs on par with few-shot frozen LLMs that are an order of magnitude larger. Website: https://zaidkhan.me/ViReP
4/9/2024