SelfPose3d: Self-Supervised Multi-Person Multi-View 3d Pose Estimation
2404.02041
0
0
Abstract
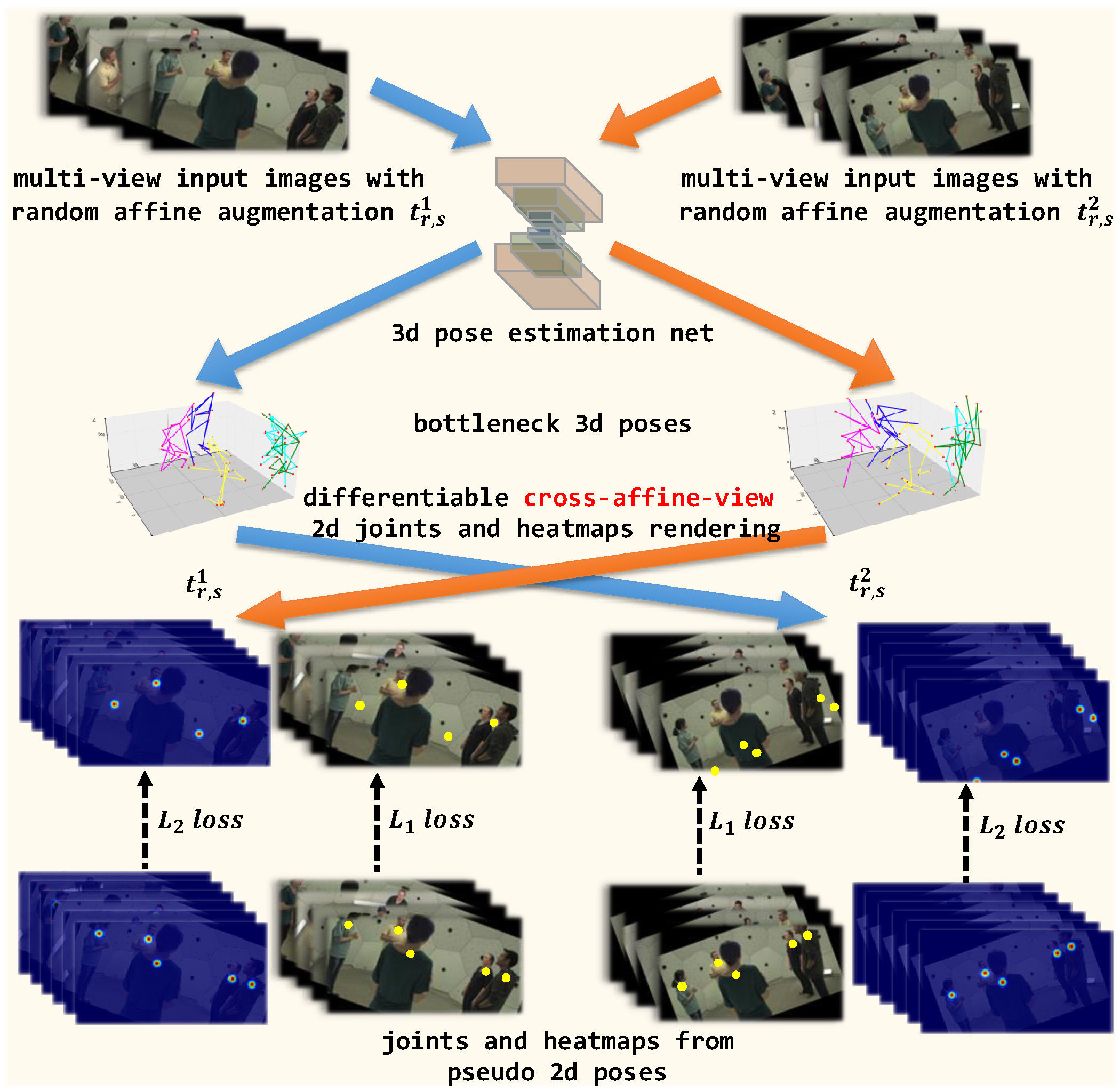
We present a new self-supervised approach, SelfPose3d, for estimating 3d poses of multiple persons from multiple camera views. Unlike current state-of-the-art fully-supervised methods, our approach does not require any 2d or 3d ground-truth poses and uses only the multi-view input images from a calibrated camera setup and 2d pseudo poses generated from an off-the-shelf 2d human pose estimator. We propose two self-supervised learning objectives: self-supervised person localization in 3d space and self-supervised 3d pose estimation. We achieve self-supervised 3d person localization by training the model on synthetically generated 3d points, serving as 3d person root positions, and on the projected root-heatmaps in all the views. We then model the 3d poses of all the localized persons with a bottleneck representation, map them onto all views obtaining 2d joints, and render them using 2d Gaussian heatmaps in an end-to-end differentiable manner. Afterwards, we use the corresponding 2d joints and heatmaps from the pseudo 2d poses for learning. To alleviate the intrinsic inaccuracy of the pseudo labels, we propose an adaptive supervision attention mechanism to guide the self-supervision. Our experiments and analysis on three public benchmark datasets, including Panoptic, Shelf, and Campus, show the effectiveness of our approach, which is comparable to fully-supervised methods. Code is available at url{https://github.com/CAMMA-public/SelfPose3D}
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces SelfPose3d, a self-supervised approach for multi-person, multi-view 3D pose estimation.
- The key innovation is using multi-view consistency as a self-supervision signal to train the model without requiring any ground truth 3D pose annotations.
- The method achieves state-of-the-art performance on 3D pose estimation benchmarks compared to fully-supervised approaches.
Plain English Explanation
SelfPose3d is a new technique for estimating the 3D poses of multiple people in images or videos from multiple camera views. Traditional methods for 3D pose estimation require extensive datasets with ground truth 3D pose information, which is costly and time-consuming to collect.
SelfPose3d avoids this limitation by using a self-supervised approach. The model is trained to ensure that the 3D poses it estimates are consistent across the different camera views of the same scene. In other words, the 3D poses should "line up" when viewed from multiple angles. This self-supervision signal allows the model to learn effective 3D pose estimation without needing any ground truth 3D pose data.
The key insight is that even though we don't have the actual 3D poses, we can leverage the geometric constraints of the multi-view setup to train the model. If the 3D poses are not consistent across views, then the model is not doing a good job. By optimizing for this multi-view consistency, the model can learn to estimate accurate 3D poses in a self-supervised way.
Technical Explanation
SelfPose3d consists of three main components:
- A 2D pose estimation network that takes in images from each camera view and outputs 2D pose keypoints.
- A 3D pose lifting network that takes the 2D poses and lifts them to 3D.
- A multi-view consistency loss that enforces the 3D poses estimated from different views to be aligned.
During training, the model alternates between updating the 2D and 3D networks to minimize the multi-view consistency loss. This forces the 3D pose estimates to be geometrically consistent across views, even without ground truth 3D annotations.
The authors evaluate SelfPose3d on standard 3D pose benchmarks like Human3.6M and MuCo-3DHP. They show that their self-supervised approach outperforms fully-supervised methods that use ground truth 3D poses for training. This demonstrates the power of leveraging multi-view geometry as a powerful self-supervision signal for 3D pose estimation.
Critical Analysis
The authors thoroughly evaluate SelfPose3d and provide convincing results showing its effectiveness. However, a few potential limitations are worth noting:
- The approach assumes multiple calibrated camera views are available during training. This may limit its applicability to real-world scenarios with uncalibrated or unknown camera setups.
- The method focuses on static 3D pose estimation. Extending it to handle dynamic, temporal information could further improve performance.
- While SelfPose3d outperforms supervised methods on benchmarks, there may still be room for improvement in accuracy compared to what is possible with large, annotated 3D pose datasets.
Overall, SelfPose3d is a promising self-supervised approach that could significantly reduce the data collection burden for 3D pose estimation. Further research is needed to address the limitations and explore real-world deployment scenarios.
Conclusion
SelfPose3d introduces a novel self-supervised method for multi-person, multi-view 3D pose estimation. By leveraging multi-view consistency as a self-supervision signal, the model can learn effective 3D pose estimation without requiring any ground truth 3D annotations. The approach achieves state-of-the-art results on standard benchmarks, demonstrating the power of this self-supervised learning strategy. While there are some limitations to address, SelfPose3d represents an important step towards more practical and scalable 3D pose estimation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Multi-person 3D pose estimation from unlabelled data
Daniel Rodriguez-Criado, Pilar Bachiller, George Vogiatzis, Luis J. Manso
0
0
Its numerous applications make multi-human 3D pose estimation a remarkably impactful area of research. Nevertheless, assuming a multiple-view system composed of several regular RGB cameras, 3D multi-pose estimation presents several challenges. First of all, each person must be uniquely identified in the different views to separate the 2D information provided by the cameras. Secondly, the 3D pose estimation process from the multi-view 2D information of each person must be robust against noise and potential occlusions in the scenario. In this work, we address these two challenges with the help of deep learning. Specifically, we present a model based on Graph Neural Networks capable of predicting the cross-view correspondence of the people in the scenario along with a Multilayer Perceptron that takes the 2D points to yield the 3D poses of each person. These two models are trained in a self-supervised manner, thus avoiding the need for large datasets with 3D annotations.
4/10/2024
UPose3D: Uncertainty-Aware 3D Human Pose Estimation with Cross-View and Temporal Cues
Vandad Davoodnia, Saeed Ghorbani, Marc-Andr'e Carbonneau, Alexandre Messier, Ali Etemad
0
0
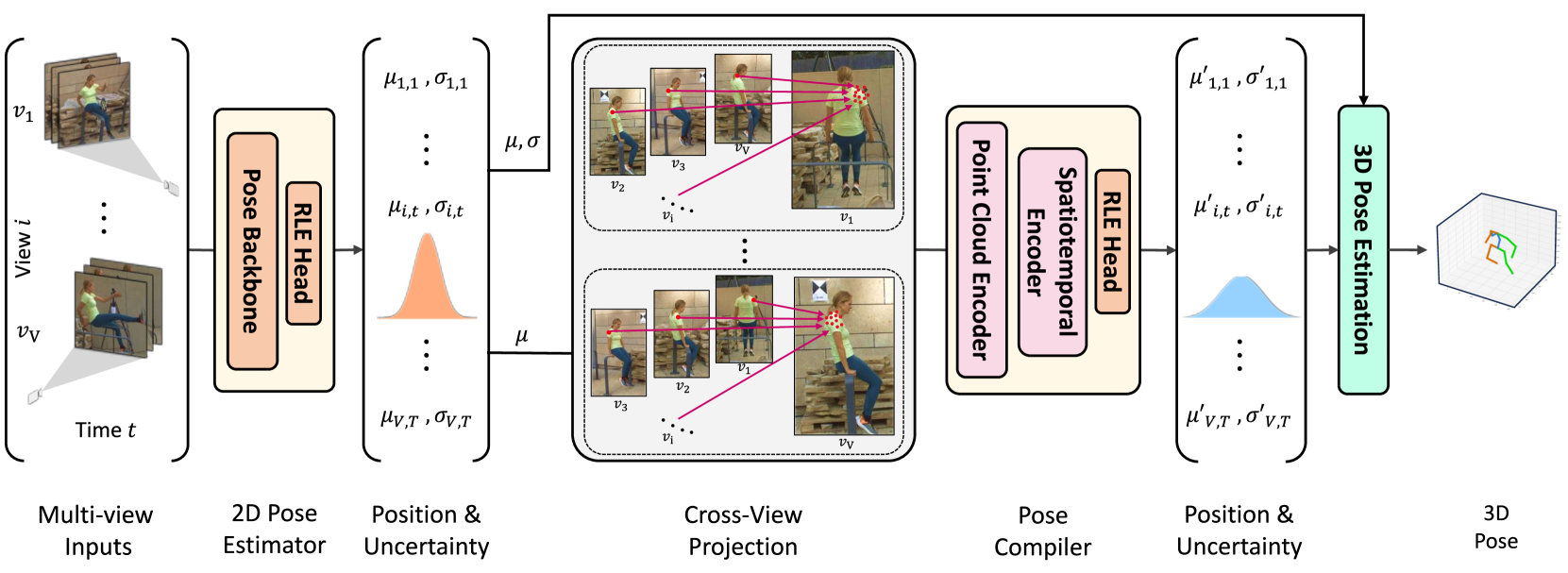
We introduce UPose3D, a novel approach for multi-view 3D human pose estimation, addressing challenges in accuracy and scalability. Our method advances existing pose estimation frameworks by improving robustness and flexibility without requiring direct 3D annotations. At the core of our method, a pose compiler module refines predictions from a 2D keypoints estimator that operates on a single image by leveraging temporal and cross-view information. Our novel cross-view fusion strategy is scalable to any number of cameras, while our synthetic data generation strategy ensures generalization across diverse actors, scenes, and viewpoints. Finally, UPose3D leverages the prediction uncertainty of both the 2D keypoint estimator and the pose compiler module. This provides robustness to outliers and noisy data, resulting in state-of-the-art performance in out-of-distribution settings. In addition, for in-distribution settings, UPose3D yields a performance rivaling methods that rely on 3D annotated data, while being the state-of-the-art among methods relying only on 2D supervision.
5/16/2024
🏷️
3D Human Pose Perception from Egocentric Stereo Videos
Hiroyasu Akada, Jian Wang, Vladislav Golyanik, Christian Theobalt
0
0
While head-mounted devices are becoming more compact, they provide egocentric views with significant self-occlusions of the device user. Hence, existing methods often fail to accurately estimate complex 3D poses from egocentric views. In this work, we propose a new transformer-based framework to improve egocentric stereo 3D human pose estimation, which leverages the scene information and temporal context of egocentric stereo videos. Specifically, we utilize 1) depth features from our 3D scene reconstruction module with uniformly sampled windows of egocentric stereo frames, and 2) human joint queries enhanced by temporal features of the video inputs. Our method is able to accurately estimate human poses even in challenging scenarios, such as crouching and sitting. Furthermore, we introduce two new benchmark datasets, i.e., UnrealEgo2 and UnrealEgo-RW (RealWorld). The proposed datasets offer a much larger number of egocentric stereo views with a wider variety of human motions than the existing datasets, allowing comprehensive evaluation of existing and upcoming methods. Our extensive experiments show that the proposed approach significantly outperforms previous methods. We will release UnrealEgo2, UnrealEgo-RW, and trained models on our project page.
5/16/2024
🤔
Cross-view and Cross-pose Completion for 3D Human Understanding
Matthieu Armando, Salma Galaaoui, Fabien Baradel, Thomas Lucas, Vincent Leroy, Romain Br'egier, Philippe Weinzaepfel, Gr'egory Rogez
0
0
Human perception and understanding is a major domain of computer vision which, like many other vision subdomains recently, stands to gain from the use of large models pre-trained on large datasets. We hypothesize that the most common pre-training strategy of relying on general purpose, object-centric image datasets such as ImageNet, is limited by an important domain shift. On the other hand, collecting domain-specific ground truth such as 2D or 3D labels does not scale well. Therefore, we propose a pre-training approach based on self-supervised learning that works on human-centric data using only images. Our method uses pairs of images of humans: the first is partially masked and the model is trained to reconstruct the masked parts given the visible ones and a second image. It relies on both stereoscopic (cross-view) pairs, and temporal (cross-pose) pairs taken from videos, in order to learn priors about 3D as well as human motion. We pre-train a model for body-centric tasks and one for hand-centric tasks. With a generic transformer architecture, these models outperform existing self-supervised pre-training methods on a wide set of human-centric downstream tasks, and obtain state-of-the-art performance for instance when fine-tuning for model-based and model-free human mesh recovery.
4/19/2024