Semantic are Beacons: A Semantic Perspective for Unveiling Parameter-Efficient Fine-Tuning in Knowledge Learning
2405.18292
0
0

Abstract
Parameter-Efficient Fine-Tuning (PEFT) methods enable efficient adaptation of Large Language Models (LLMs) to various downstream applications. However, the effectiveness of the PEFT diminishes notably when downstream tasks require accurate learning of factual knowledge. In this paper, we adopt a semantic perspective to investigate this phenomenon, uncovering the reasons behind PEFT's limitations in knowledge learning task. Our findings reveal that: (1) PEFT presents a notable risk of pushing the model away from the intended knowledge target; (2) multiple knowledge interfere with each other, and such interference suppresses the learning and expression of knowledge features. Based on these insights, we introduce a data filtering strategy to exclude data that is detrimental to knowledge learning and a re-weighted learning strategy to make the model attentive to semantic distance during knowledge learning. Experimental results demonstrate the effectiveness of the proposed method on open-source large language model, further validate the semantic challenge in PEFT, thus paving the way for future research.
Create account to get full access
Overview
- This paper explores a semantic perspective on parameter-efficient fine-tuning, a technique for adapting large pre-trained models to new tasks with fewer trainable parameters.
- The authors propose that semantic information, captured by the model's internal representations, can serve as "beacons" to guide the fine-tuning process and enable more efficient knowledge transfer.
- The paper presents a novel fine-tuning approach and thorough empirical analysis across multiple tasks and datasets, demonstrating the effectiveness of the semantic perspective.
Plain English Explanation
When training machine learning models, a common challenge is adapting large, pre-trained models to new tasks or datasets. This process, known as fine-tuning, typically requires retraining a significant portion of the model's parameters, which can be computationally expensive and data-intensive.
The researchers behind this paper suggest an alternative approach, where the semantic information - the meaning and understanding - captured by the pre-trained model can serve as a guide or "beacon" during the fine-tuning process. By focusing on these semantic representations, the model can learn new tasks more efficiently, using fewer trainable parameters.
This parameter-efficient fine-tuning technique can be particularly useful in low-resource settings where data or computational power is limited, or when scaling large models to diverse tasks and applications.
The authors conduct a thorough empirical analysis across multiple datasets and tasks, demonstrating the effectiveness of their semantic-guided approach compared to traditional fine-tuning methods. This research provides valuable insights into optimizing the fine-tuning process and unlocking the full potential of large, pre-trained models.
Technical Explanation
The core premise of this paper is that the semantic information captured by pre-trained models can serve as "beacons" to guide the fine-tuning process and enable more efficient knowledge transfer. The authors propose a novel fine-tuning approach that leverages these semantic representations, in contrast to the traditional fine-tuning method that focuses solely on the task-specific objective.
The researchers first conduct a detailed analysis of the semantic information present in pre-trained models, exploring how it evolves during the fine-tuning process. They then develop a fine-tuning framework that selectively updates the model's parameters based on the semantic relevance of different regions of the network.
Through extensive experiments across diverse tasks and datasets, the authors demonstrate the effectiveness of their semantic-guided fine-tuning approach. They show that by focusing on the semantic information, the model can achieve comparable performance to traditional fine-tuning methods while using significantly fewer trainable parameters.
The paper also provides a comprehensive analysis of the underlying factors that contribute to the success of their approach, including the impact of dataset size, task complexity, and model architecture. The authors delve into the intricacies of the fine-tuning process, offering insights that can inform the development of more efficient and versatile transfer learning techniques.
Critical Analysis
The researchers present a well-designed and thorough study, with a clear focus on exploring the semantic perspective as a means to improve parameter-efficient fine-tuning. The proposed approach is theoretically sound and the empirical results provide strong evidence for its effectiveness.
However, the paper does acknowledge some limitations and potential areas for further research. For instance, the authors note that the semantic-guided fine-tuning may be less effective for tasks that require significant structural changes to the model, as the approach primarily focuses on the semantic representations.
Additionally, the paper does not delve into the computational and memory footprint of the proposed fine-tuning framework, which could be a crucial consideration, especially when dealing with large-scale models and constrained deployment environments.
Further research could explore the interplay between the semantic representations, task-specific objectives, and the underlying model architecture in greater depth. Investigating the generalizability of the semantic-guided approach to a wider range of tasks and domains would also be valuable.
Conclusion
This paper offers a novel and insightful perspective on parameter-efficient fine-tuning, highlighting the potential of leveraging semantic information to guide the knowledge transfer process. The authors' empirical analysis demonstrates the effectiveness of their approach, which can have significant implications for the efficient adaptation of large, pre-trained models to diverse applications and low-resource settings.
By shifting the focus to the semantic representations within the model, this research provides a compelling framework for optimizing the fine-tuning process and unlocking the full potential of transfer learning. The insights and techniques presented in this work can inspire further advancements in the field of efficient model adaptation and knowledge reuse.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
A Semantic-based Layer Freezing Approach to Efficient Fine-Tuning of Language Models
Jian Gu, Aldeida Aleti, Chunyang Chen, Hongyu Zhang
0
0
Finetuning language models (LMs) is crucial for adapting the models to downstream data and tasks. However, full finetuning is usually costly. Existing work, such as parameter-efficient finetuning (PEFT), often focuses on textit{how to finetune} but neglects the issue of textit{where to finetune}. As a pioneering work on answering where to finetune (at the layer level), we conduct a semantic analysis of the LM inference process. We first propose a virtual transition of the latent representation and then trace its factual transition. Based on the deviation in transitions, we estimate the gain of finetuning each model layer, and further, narrow down the scope for finetuning. We perform extensive experiments across well-known LMs and datasets. The results show that our approach is effective and efficient, and outperforms the existing baselines. Our approach is orthogonal to existing efficient techniques, such as PEFT methods, offering practical values on LM finetuning.
6/18/2024

Q-PEFT: Query-dependent Parameter Efficient Fine-tuning for Text Reranking with Large Language Models
Zhiyuan Peng, Xuyang Wu, Qifan Wang, Sravanthi Rajanala, Yi Fang
0
0
Parameter Efficient Fine-Tuning (PEFT) methods have been extensively utilized in Large Language Models (LLMs) to improve the down-streaming tasks without the cost of fine-tuing the whole LLMs. Recent studies have shown how to effectively use PEFT for fine-tuning LLMs in ranking tasks with convincing performance; there are some limitations, including the learned prompt being fixed for different documents, overfitting to specific tasks, and low adaptation ability. In this paper, we introduce a query-dependent parameter efficient fine-tuning (Q-PEFT) approach for text reranking to leak the information of the true queries to LLMs and then make the generation of true queries from input documents much easier. Specifically, we utilize the query to extract the top-$k$ tokens from concatenated documents, serving as contextual clues. We further augment Q-PEFT by substituting the retrieval mechanism with a multi-head attention layer to achieve end-to-end training and cover all the tokens in the documents, guiding the LLMs to generate more document-specific synthetic queries, thereby further improving the reranking performance. Extensive experiments are conducted on four public datasets, demonstrating the effectiveness of our proposed approach.
4/15/2024

Unlocking Parameter-Efficient Fine-Tuning for Low-Resource Language Translation
Tong Su, Xin Peng, Sarubi Thillainathan, David Guzm'an, Surangika Ranathunga, En-Shiun Annie Lee
0
0
Parameter-efficient fine-tuning (PEFT) methods are increasingly vital in adapting large-scale pre-trained language models for diverse tasks, offering a balance between adaptability and computational efficiency. They are important in Low-Resource Language (LRL) Neural Machine Translation (NMT) to enhance translation accuracy with minimal resources. However, their practical effectiveness varies significantly across different languages. We conducted comprehensive empirical experiments with varying LRL domains and sizes to evaluate the performance of 8 PEFT methods with in total of 15 architectures using the SacreBLEU score. We showed that 6 PEFT architectures outperform the baseline for both in-domain and out-domain tests and the Houlsby+Inversion adapter has the best performance overall, proving the effectiveness of PEFT methods.
4/8/2024
An Empirical Study of Parameter Efficient Fine-tuning on Vision-Language Pre-train Model
Yuxin Tian, Mouxing Yang, Yunfan Li, Dayiheng Liu, Xingzhang Ren, Xi Peng, Jiancheng Lv
0
0
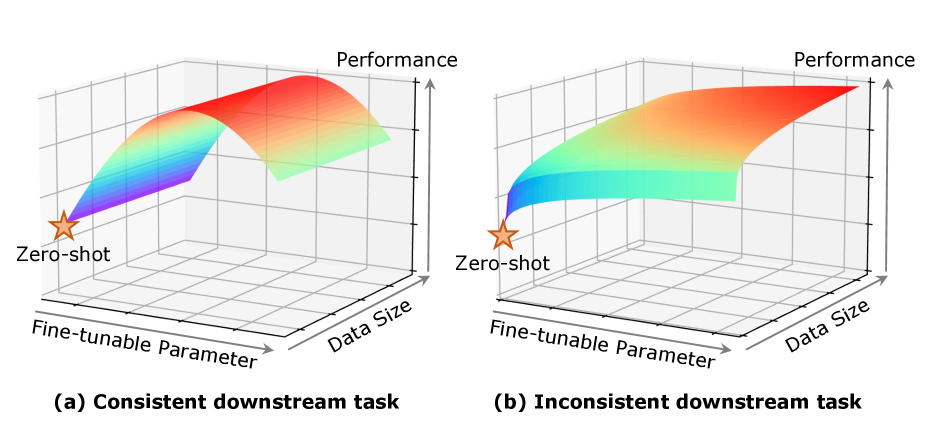
Recent studies applied Parameter Efficient Fine-Tuning techniques (PEFTs) to efficiently narrow the performance gap between pre-training and downstream. There are two important factors for various PEFTs, namely, the accessible data size and fine-tunable parameter size. A natural expectation for PEFTs is that the performance of various PEFTs is positively related to the data size and fine-tunable parameter size. However, according to the evaluation of five PEFTs on two downstream vision-language (VL) tasks, we find that such an intuition holds only if the downstream data and task are not consistent with pre-training. For downstream fine-tuning consistent with pre-training, data size no longer affects the performance, while the influence of fine-tunable parameter size is not monotonous. We believe such an observation could guide the choice of training strategy for various PEFTs.
5/21/2024