An Empirical Study of Parameter Efficient Fine-tuning on Vision-Language Pre-train Model
2403.08433
0
0
Abstract
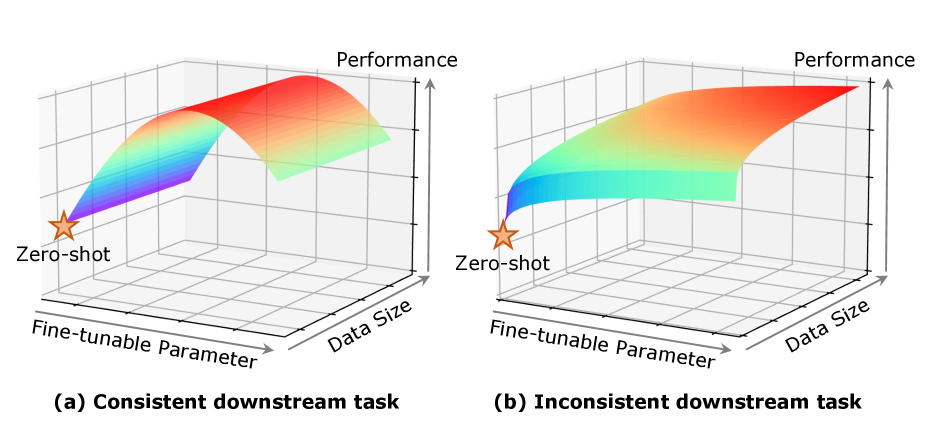
Recent studies applied Parameter Efficient Fine-Tuning techniques (PEFTs) to efficiently narrow the performance gap between pre-training and downstream. There are two important factors for various PEFTs, namely, the accessible data size and fine-tunable parameter size. A natural expectation for PEFTs is that the performance of various PEFTs is positively related to the data size and fine-tunable parameter size. However, according to the evaluation of five PEFTs on two downstream vision-language (VL) tasks, we find that such an intuition holds only if the downstream data and task are not consistent with pre-training. For downstream fine-tuning consistent with pre-training, data size no longer affects the performance, while the influence of fine-tunable parameter size is not monotonous. We believe such an observation could guide the choice of training strategy for various PEFTs.
Create account to get full access
Overview
- This paper presents an empirical study on parameter-efficient fine-tuning of vision-language pre-trained models.
- The study explores various parameter-efficient fine-tuning techniques, including Sparse is Enough, Unlocking Parameter-Efficient Fine-tuning, and Q-PEFT.
- The researchers evaluate the effectiveness of these techniques on a range of vision-language tasks, providing insights into their strengths and limitations.
Plain English Explanation
The paper focuses on a technique called "parameter-efficient fine-tuning," which is a way to adapt large, pre-trained machine learning models to new tasks without having to completely retrain the entire model from scratch. This is particularly useful when you have limited computing resources or a small amount of training data for the new task.
The researchers in this study looked at several different parameter-efficient fine-tuning methods, including Sparse is Enough, Unlocking Parameter-Efficient Fine-tuning, and Q-PEFT. They tested these methods on a variety of vision-language tasks, which involve understanding the content of images and how it relates to language.
The goal was to see how well these parameter-efficient fine-tuning techniques performed compared to fully retraining the entire model from scratch. The researchers found that these techniques can be quite effective, allowing the model to adapt to new tasks with much fewer additional parameters than a full retraining. This could be very useful in scenarios where computational resources or training data are limited.
Technical Explanation
The paper presents an empirical study of parameter-efficient fine-tuning techniques on large vision-language pre-trained models. The researchers explore several methods, including Sparse is Enough, Unlocking Parameter-Efficient Fine-tuning, and Q-PEFT.
The experimental setup involves fine-tuning a pre-trained vision-language model (such as CLIP or ALIGN) on a variety of downstream tasks, including visual question answering, image-text retrieval, and zero-shot image classification. The researchers compare the performance of the parameter-efficient fine-tuning methods to a full fine-tuning baseline, where all model parameters are updated.
The results show that the parameter-efficient techniques can achieve comparable or even superior performance to full fine-tuning, but with significantly fewer additional parameters. For example, Sparse is Enough only updates 1-2% of the model parameters, while Unlocking Parameter-Efficient Fine-tuning and Q-PEFT further reduce the parameter count by exploiting the structure of the pre-trained model.
The paper also provides insights into the strengths and limitations of each parameter-efficient fine-tuning method. For instance, Sparse is Enough is more effective for tasks that require global changes to the model, while Unlocking Parameter-Efficient Fine-tuning and Q-PEFT excel at tasks that can be solved with more localized changes.
Critical Analysis
The paper provides a comprehensive and rigorous evaluation of parameter-efficient fine-tuning techniques on vision-language pre-trained models. The researchers carefully design their experiments and thoughtfully discuss the strengths and limitations of each method.
One potential limitation of the study is the scope of the tasks and datasets used. While the researchers cover a range of vision-language tasks, it would be interesting to see how the techniques perform on an even broader set of applications, including those outside the vision-language domain.
Additionally, the paper does not delve deeply into the underlying mechanisms and theoretical foundations of the parameter-efficient fine-tuning methods. A more in-depth analysis of the optimization dynamics and the relationship between the techniques and the structure of the pre-trained models could provide further insights.
Another area for potential improvement is the comparison to other relevant techniques, such as Adapter-based Fine-tuning or Prompt-based Learning. Incorporating these methods into the comparative analysis could give a more comprehensive understanding of the parameter-efficient fine-tuning landscape.
Despite these potential avenues for further research, the paper offers a valuable contribution to the field by providing a thorough empirical study and practical insights into parameter-efficient fine-tuning approaches for vision-language models.
Conclusion
This paper presents an in-depth exploration of parameter-efficient fine-tuning techniques for vision-language pre-trained models. The researchers evaluate several methods, including Sparse is Enough, Unlocking Parameter-Efficient Fine-tuning, and Q-PEFT, on a range of downstream tasks.
The results demonstrate that these parameter-efficient fine-tuning approaches can achieve comparable or even superior performance to full model fine-tuning, while significantly reducing the number of additional parameters required. This could be particularly valuable in scenarios with limited computational resources or training data, making it easier to adapt large, pre-trained models to new applications.
The paper provides valuable insights into the strengths and limitations of the different parameter-efficient fine-tuning methods, offering guidance for practitioners on selecting the most appropriate technique for their specific use cases. Overall, this study contributes to the growing body of research on parameter-efficient fine-tuning, which is an important step towards making large, powerful machine learning models more accessible and practical for a wider range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, Sai Qian Zhang
0
0
Large models represent a groundbreaking advancement in multiple application fields, enabling remarkable achievements across various tasks. However, their unprecedented scale comes with significant computational costs. These models, often consisting of billions of parameters, require vast amounts of computational resources for execution. Especially, the expansive scale and computational demands pose considerable challenges when customizing them for particular downstream tasks, particularly over the hardware platforms constrained by computational capabilities. Parameter Efficient Fine-Tuning (PEFT) provides a practical solution by efficiently adapt the large models over the various downstream tasks. In particular, PEFT refers to the process of adjusting the parameters of a pre-trained large models to adapt it to a specific task while minimizing the number of additional parameters introduced or computational resources required. This approach is particularly important when dealing with large language models with high parameter counts, as fine-tuning these models from scratch can be computationally expensive and resource-intensive, posing considerable challenges in the supporting system platform design. In this survey, we present comprehensive studies of various PEFT algorithms, examining their performance and computational overhead. Moreover, we provide an overview of applications developed using different PEFT algorithms and discuss common techniques employed to mitigate computation costs for PEFT. In addition to the algorithmic perspective, we overview various real-world system designs to investigate the implementation costs associated with different PEFT algorithms. This survey serves as an indispensable resource for researchers aiming to understand both the PEFT algorithm and its system implementation, offering detailed insights into recent advancements and practical applications.
4/30/2024

An Empirical Study on Parameter-Efficient Fine-Tuning for MultiModal Large Language Models
Xiongtao Zhou, Jie He, Yuhua Ke, Guangyao Zhu, V'ictor Guti'errez-Basulto, Jeff Z. Pan
0
0
Multimodal large language models (MLLMs) fine-tuned with multimodal instruction datasets have demonstrated remarkable capabilities in multimodal tasks. However, fine-tuning all parameters of MLLMs has become challenging as they usually contain billions of parameters. To address this issue, we study parameter-efficient fine-tuning (PEFT) methods for MLLMs. We aim to identify effective methods for enhancing the performance of MLLMs in scenarios where only a limited number of parameters are trained. This paper conducts empirical studies using four popular PEFT methods to fine-tune the LLM component of open-source MLLMs. We present a comprehensive analysis that encompasses various aspects, including the impact of PEFT methods on various models, parameters and location of the PEFT module, size of fine-tuning data, model stability based on PEFT methods, MLLM's generalization, and hallucination. We evaluated four PEFT methods on seven datasets from two different categories: unseen and seen datasets. Across all experiments, we show that the adapter is the best-performing PEFT method. At the same time, fine-tuning the connector layers leads to improved performance in most MLLMs. Code and data are available at https://github.com/alenai97/PEFT-MLLM.git.
6/10/2024

Parameter Efficient Fine Tuning: A Comprehensive Analysis Across Applications
Charith Chandra Sai Balne, Sreyoshi Bhaduri, Tamoghna Roy, Vinija Jain, Aman Chadha
0
0
The rise of deep learning has marked significant progress in fields such as computer vision, natural language processing, and medical imaging, primarily through the adaptation of pre-trained models for specific tasks. Traditional fine-tuning methods, involving adjustments to all parameters, face challenges due to high computational and memory demands. This has led to the development of Parameter Efficient Fine-Tuning (PEFT) techniques, which selectively update parameters to balance computational efficiency with performance. This review examines PEFT approaches, offering a detailed comparison of various strategies highlighting applications across different domains, including text generation, medical imaging, protein modeling, and speech synthesis. By assessing the effectiveness of PEFT methods in reducing computational load, speeding up training, and lowering memory usage, this paper contributes to making deep learning more accessible and adaptable, facilitating its wider application and encouraging innovation in model optimization. Ultimately, the paper aims to contribute towards insights into PEFT's evolving landscape, guiding researchers and practitioners in overcoming the limitations of conventional fine-tuning approaches.
4/23/2024
🖼️
Parameter-Efficient Fine-Tuning for Medical Image Analysis: The Missed Opportunity
Raman Dutt, Linus Ericsson, Pedro Sanchez, Sotirios A. Tsaftaris, Timothy Hospedales
0
0
Foundation models have significantly advanced medical image analysis through the pre-train fine-tune paradigm. Among various fine-tuning algorithms, Parameter-Efficient Fine-Tuning (PEFT) is increasingly utilized for knowledge transfer across diverse tasks, including vision-language and text-to-image generation. However, its application in medical image analysis is relatively unexplored due to the lack of a structured benchmark for evaluating PEFT methods. This study fills this gap by evaluating 17 distinct PEFT algorithms across convolutional and transformer-based networks on image classification and text-to-image generation tasks using six medical datasets of varying size, modality, and complexity. Through a battery of over 700 controlled experiments, our findings demonstrate PEFT's effectiveness, particularly in low data regimes common in medical imaging, with performance gains of up to 22% in discriminative and generative tasks. These recommendations can assist the community in incorporating PEFT into their workflows and facilitate fair comparisons of future PEFT methods, ensuring alignment with advancements in other areas of machine learning and AI.
6/11/2024