SeeSR: Towards Semantics-Aware Real-World Image Super-Resolution
2311.16518
0
0

Abstract
Owe to the powerful generative priors, the pre-trained text-to-image (T2I) diffusion models have become increasingly popular in solving the real-world image super-resolution problem. However, as a consequence of the heavy quality degradation of input low-resolution (LR) images, the destruction of local structures can lead to ambiguous image semantics. As a result, the content of reproduced high-resolution image may have semantic errors, deteriorating the super-resolution performance. To address this issue, we present a semantics-aware approach to better preserve the semantic fidelity of generative real-world image super-resolution. First, we train a degradation-aware prompt extractor, which can generate accurate soft and hard semantic prompts even under strong degradation. The hard semantic prompts refer to the image tags, aiming to enhance the local perception ability of the T2I model, while the soft semantic prompts compensate for the hard ones to provide additional representation information. These semantic prompts encourage the T2I model to generate detailed and semantically accurate results. Furthermore, during the inference process, we integrate the LR images into the initial sampling noise to mitigate the diffusion model's tendency to generate excessive random details. The experiments show that our method can reproduce more realistic image details and hold better the semantics. The source code of our method can be found at https://github.com/cswry/SeeSR.
Create account to get full access
Overview
• The paper proposes a new method called "SeeSR" for real-world image super-resolution that leverages semantic information to improve the quality of the upscaled images. • The method aims to address the limitations of existing super-resolution approaches, which often struggle with real-world images that contain complex semantic content. • The proposed SeeSR model incorporates semantic guidance to better preserve the structural and contextual information of the input image during the upscaling process.
Plain English Explanation
The paper presents a new way to improve the quality of enlarged images, especially for real-world photos that contain a lot of complex information. Existing super-resolution methods, which aim to make low-resolution images look sharper and more detailed, often struggle with real-world images that have a lot of semantic content, such as different objects, scenes, and textures.
The researchers developed a model called "SeeSR" that uses information about the meaning and context of the image, known as "semantic information," to help the super-resolution process. By incorporating this semantic guidance, the SeeSR model can better preserve the structural and contextual details of the original image when it is enlarged, resulting in higher-quality upscaled outputs.
This is important because real-world images often contain a lot of complex information that is difficult for traditional super-resolution methods to handle effectively. The SeeSR approach aims to address this limitation by leveraging the semantic understanding of the image content to guide the upscaling process and produce more accurate and visually pleasing results.
Technical Explanation
The paper proposes a new Semantics-Aware Real-World Image Super-Resolution (SeeSR) model that incorporates semantic information to improve the quality of upscaled real-world images.
The key innovation is the use of a semantic guidance module that learns to capture the semantic context of the input image and then uses this information to guide the super-resolution network. This semantic guidance helps the model better preserve the structural and contextual details of the image during the upscaling process, leading to more accurate and visually appealing results compared to previous super-resolution approaches.
The SeeSR model consists of two main components: a semantic guidance module and a super-resolution network. The semantic guidance module uses a pre-trained image segmentation model to extract semantic features from the input image, which are then combined with the low-resolution input to guide the super-resolution network.
The super-resolution network is based on a deep convolutional neural network architecture and is trained to upscale the low-resolution input while preserving the semantic information provided by the guidance module. The researchers also incorporate various techniques, such as feature fusion and multi-scale learning, to further improve the performance of the super-resolution network.
Critical Analysis
The paper provides a compelling approach to addressing the limitations of existing super-resolution methods when dealing with real-world images. The incorporation of semantic guidance is a promising strategy, as it allows the model to better understand the context and structure of the input image, which is crucial for producing high-quality upscaled outputs.
However, the paper does not thoroughly explore the potential limitations or drawbacks of the SeeSR method. For example, the reliance on a pre-trained segmentation model could introduce additional complexity and potential errors if the segmentation model is not accurate or robust enough. Additionally, the paper does not discuss the computational or memory requirements of the SeeSR model, which could be a concern for real-world deployment, especially on resource-constrained devices.
Further research could explore the generalizability of the SeeSR approach to a wider range of real-world scenarios, as well as investigate ways to make the model more efficient and robust to potential errors in the semantic guidance. It would also be interesting to see how the SeeSR method compares to other state-of-the-art super-resolution techniques that incorporate semantic information in different ways.
Conclusion
The SeeSR paper presents a novel approach to real-world image super-resolution that leverages semantic information to improve the quality of upscaled outputs. By incorporating a semantic guidance module into the super-resolution network, the model can better preserve the structural and contextual details of the input image, leading to more accurate and visually appealing results.
This work is an important step forward in addressing the limitations of existing super-resolution methods, which often struggle with complex real-world images. The SeeSR approach has the potential to enable higher-quality image enlargement for a wide range of applications, from digital photography to video streaming and medical imaging. While further research is needed to explore the full potential and limitations of the method, this paper demonstrates the value of incorporating semantic understanding into image processing tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DaLPSR: Leverage Degradation-Aligned Language Prompt for Real-World Image Super-Resolution
Aiwen Jiang, Zhi Wei, Long Peng, Feiqiang Liu, Wenbo Li, Mingwen Wang
0
0
Image super-resolution pursuits reconstructing high-fidelity high-resolution counterpart for low-resolution image. In recent years, diffusion-based models have garnered significant attention due to their capabilities with rich prior knowledge. The success of diffusion models based on general text prompts has validated the effectiveness of textual control in the field of text2image. However, given the severe degradation commonly presented in low-resolution images, coupled with the randomness characteristics of diffusion models, current models struggle to adequately discern semantic and degradation information within severely degraded images. This often leads to obstacles such as semantic loss, visual artifacts, and visual hallucinations, which pose substantial challenges for practical use. To address these challenges, this paper proposes to leverage degradation-aligned language prompt for accurate, fine-grained, and high-fidelity image restoration. Complementary priors including semantic content descriptions and degradation prompts are explored. Specifically, on one hand, image-restoration prompt alignment decoder is proposed to automatically discern the degradation degree of LR images, thereby generating beneficial degradation priors for image restoration. On the other hand, much richly tailored descriptions from pretrained multimodal large language model elicit high-level semantic priors closely aligned with human perception, ensuring fidelity control for image restoration. Comprehensive comparisons with state-of-the-art methods have been done on several popular synthetic and real-world benchmark datasets. The quantitative and qualitative analysis have demonstrated that the proposed method achieves a new state-of-the-art perceptual quality level, especially in real-world cases based on reference-free metrics.
6/26/2024

Beyond Image Super-Resolution for Image Recognition with Task-Driven Perceptual Loss
Jaeha Kim, Junghun Oh, Kyoung Mu Lee
0
0
In real-world scenarios, image recognition tasks, such as semantic segmentation and object detection, often pose greater challenges due to the lack of information available within low-resolution (LR) content. Image super-resolution (SR) is one of the promising solutions for addressing the challenges. However, due to the ill-posed property of SR, it is challenging for typical SR methods to restore task-relevant high-frequency contents, which may dilute the advantage of utilizing the SR method. Therefore, in this paper, we propose Super-Resolution for Image Recognition (SR4IR) that effectively guides the generation of SR images beneficial to achieving satisfactory image recognition performance when processing LR images. The critical component of our SR4IR is the task-driven perceptual (TDP) loss that enables the SR network to acquire task-specific knowledge from a network tailored for a specific task. Moreover, we propose a cross-quality patch mix and an alternate training framework that significantly enhances the efficacy of the TDP loss by addressing potential problems when employing the TDP loss. Through extensive experiments, we demonstrate that our SR4IR achieves outstanding task performance by generating SR images useful for a specific image recognition task, including semantic segmentation, object detection, and image classification. The implementation code is available at https://github.com/JaehaKim97/SR4IR.
4/5/2024
🖼️
Semantic Guided Large Scale Factor Remote Sensing Image Super-resolution with Generative Diffusion Prior
Ce Wang, Wanjie Sun
0
0
Remote sensing images captured by different platforms exhibit significant disparities in spatial resolution. Large scale factor super-resolution (SR) algorithms are vital for maximizing the utilization of low-resolution (LR) satellite data captured from orbit. However, existing methods confront challenges in recovering SR images with clear textures and correct ground objects. We introduce a novel framework, the Semantic Guided Diffusion Model (SGDM), designed for large scale factor remote sensing image super-resolution. The framework exploits a pre-trained generative model as a prior to generate perceptually plausible SR images. We further enhance the reconstruction by incorporating vector maps, which carry structural and semantic cues. Moreover, pixel-level inconsistencies in paired remote sensing images, stemming from sensor-specific imaging characteristics, may hinder the convergence of the model and diversity in generated results. To address this problem, we propose to extract the sensor-specific imaging characteristics and model the distribution of them, allowing diverse SR images generation based on imaging characteristics provided by reference images or sampled from the imaging characteristic probability distributions. To validate and evaluate our approach, we create the Cross-Modal Super-Resolution Dataset (CMSRD). Qualitative and quantitative experiments on CMSRD showcase the superiority and broad applicability of our method. Experimental results on downstream vision tasks also demonstrate the utilitarian of the generated SR images. The dataset and code will be publicly available at https://github.com/wwangcece/SGDM
5/14/2024
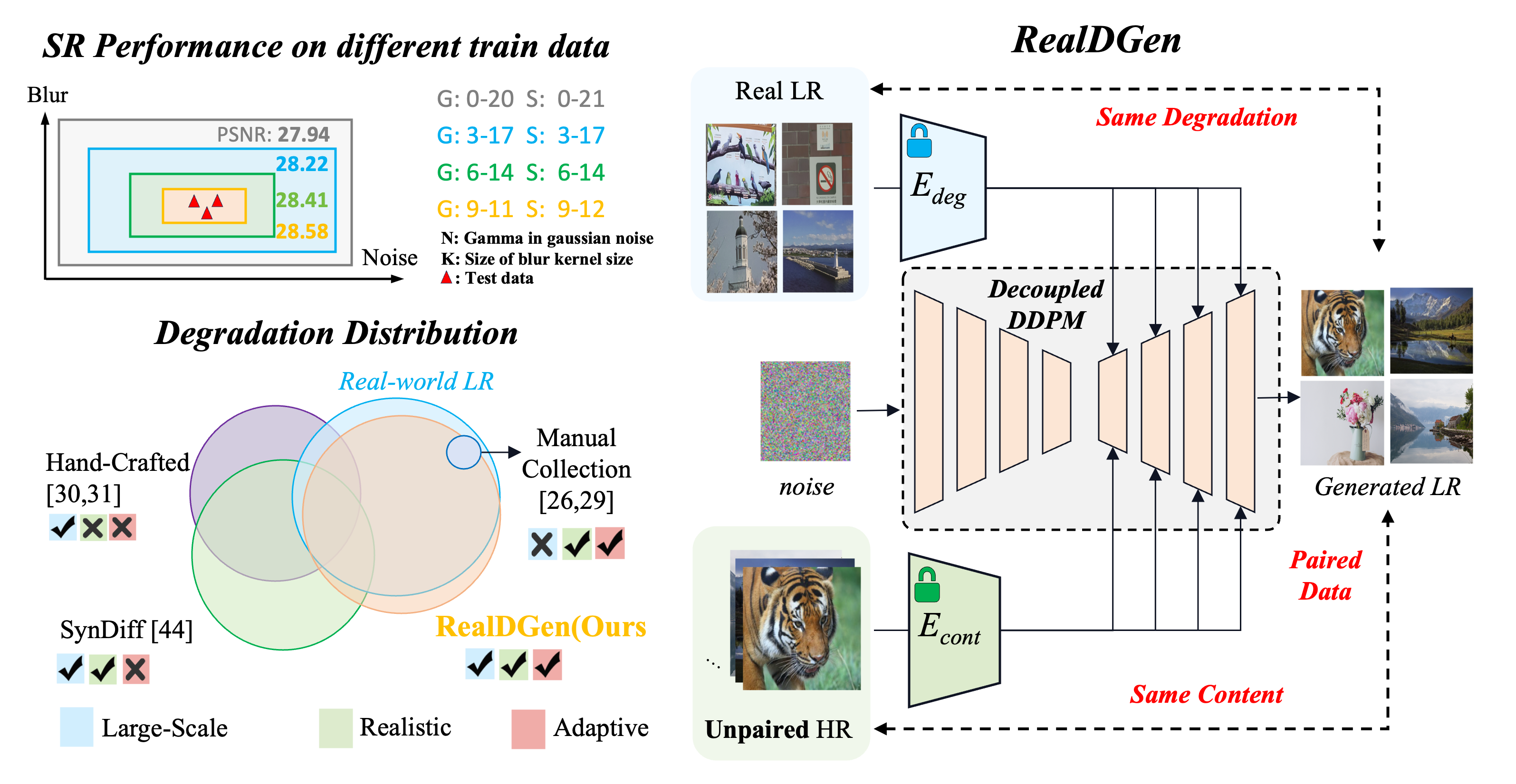
Towards Realistic Data Generation for Real-World Super-Resolution
Long Peng, Wenbo Li, Renjing Pei, Jingjing Ren, Xueyang Fu, Yang Wang, Yang Cao, Zheng-Jun Zha
0
0
Existing image super-resolution (SR) techniques often fail to generalize effectively in complex real-world settings due to the significant divergence between training data and practical scenarios. To address this challenge, previous efforts have either manually simulated intricate physical-based degradations or utilized learning-based techniques, yet these approaches remain inadequate for producing large-scale, realistic, and diverse data simultaneously. In this paper, we introduce a novel Realistic Decoupled Data Generator (RealDGen), an unsupervised learning data generation framework designed for real-world super-resolution. We meticulously develop content and degradation extraction strategies, which are integrated into a novel content-degradation decoupled diffusion model to create realistic low-resolution images from unpaired real LR and HR images. Extensive experiments demonstrate that RealDGen excels in generating large-scale, high-quality paired data that mirrors real-world degradations, significantly advancing the performance of popular SR models on various real-world benchmarks.
6/13/2024