Semi-Supervised Semantic Segmentation via Marginal Contextual Information
2308.13900
0
0
📶
Abstract
We present a novel confidence refinement scheme that enhances pseudo labels in semi-supervised semantic segmentation. Unlike existing methods, which filter pixels with low-confidence predictions in isolation, our approach leverages the spatial correlation of labels in segmentation maps by grouping neighboring pixels and considering their pseudo labels collectively. With this contextual information, our method, named S4MC, increases the amount of unlabeled data used during training while maintaining the quality of the pseudo labels, all with negligible computational overhead. Through extensive experiments on standard benchmarks, we demonstrate that S4MC outperforms existing state-of-the-art semi-supervised learning approaches, offering a promising solution for reducing the cost of acquiring dense annotations. For example, S4MC achieves a 1.39 mIoU improvement over the prior art on PASCAL VOC 12 with 366 annotated images. The code to reproduce our experiments is available at https://s4mcontext.github.io/
Create account to get full access
Overview
- This paper presents a novel approach called S4MC for enhancing pseudo labels in semi-supervised semantic segmentation.
- Unlike existing methods that filter low-confidence predictions in isolation, S4MC leverages the spatial correlation of labels in segmentation maps by grouping neighboring pixels and considering their pseudo labels collectively.
- This contextual information allows S4MC to increase the amount of unlabeled data used during training while maintaining the quality of the pseudo labels, with negligible computational overhead.
- Experiments on standard benchmarks show that S4MC outperforms existing state-of-the-art semi-supervised learning approaches, offering a promising solution for reducing the cost of acquiring dense annotations.
Plain English Explanation
In the field of computer vision, semantic segmentation is the task of dividing an image into different regions and labeling each one with its semantic meaning, such as "sky," "road," or "person." This is a crucial step for many applications, like self-driving cars or image understanding.
However, training accurate semantic segmentation models requires a lot of labeled training data, which can be time-consuming and expensive to acquire. Semi-supervised learning is a technique that aims to address this by using a small amount of labeled data along with a larger amount of unlabeled data to train the model.
One popular approach in semi-supervised learning is to use "pseudo labels" - predictions made by the model on the unlabeled data that are treated as ground truth during training. The key challenge is ensuring the quality of these pseudo labels, as low-confidence predictions can actually harm the model's performance.
The novel method presented in this paper, called S4MC, addresses this challenge in a clever way. Instead of considering each pixel's pseudo label in isolation, S4MC looks at the labels of neighboring pixels as a group. This "contextual information" allows the method to better distinguish between high-confidence and low-confidence regions, enabling it to use more of the unlabeled data while maintaining the quality of the pseudo labels.
Through experiments, the researchers show that S4MC outperforms other state-of-the-art semi-supervised learning approaches, leading to significant improvements in semantic segmentation accuracy. This is an important step towards reducing the cost and effort required to train these models, which could have a big impact on real-world applications.
Technical Explanation
The core idea behind S4MC is to leverage the spatial correlation of labels in segmentation maps to improve the quality of pseudo labels used in semi-supervised learning. Unlike previous methods that filter pixels with low-confidence predictions in isolation, S4MC groups neighboring pixels and considers their pseudo labels collectively.
Specifically, the S4MC algorithm first divides the unlabeled images into small superpixels - coherent regions of similar pixels. It then computes a confidence score for each superpixel based on the consistency of the pseudo labels within that region. Superpixels with high-confidence scores are kept as pseudo-labeled data, while those with low-confidence scores are discarded.
This contextual approach allows S4MC to retain more of the unlabeled data for training, as it can identify regions where the pseudo labels are reliable even if individual pixel predictions are not very confident. The researchers show that this leads to significant performance gains compared to prior semi-supervised methods that filter pixels independently.
The S4MC method is implemented as a simple post-processing step that can be applied to the output of any existing semantic segmentation model. Experiments on standard benchmarks like PASCAL VOC 12 and Cityscapes demonstrate that S4MC consistently outperforms state-of-the-art semi-supervised approaches, with negligible computational overhead.
Critical Analysis
The S4MC paper presents a well-designed and effective solution for improving pseudo labels in semi-supervised semantic segmentation. The key innovation of leveraging spatial context is a clever way to address the limitations of previous pixel-level filtering approaches.
That said, the paper does not explore the potential limitations or failure modes of the S4MC method. For example, it's unclear how the approach would perform on datasets with more complex or diverse scene compositions, where the assumption of spatially correlated labels may not hold as strongly.
Additionally, the paper focuses solely on semantic segmentation and does not consider other dense prediction tasks, such as medical image segmentation or video segmentation. It would be interesting to see if the S4MC ideas could be generalized to these related domains.
Overall, the S4MC method represents an important step forward in semi-supervised learning for semantic segmentation. While the paper could benefit from a more thorough exploration of the approach's limitations and potential extensions, the core ideas and empirical results are quite compelling and warrant further investigation by the research community.
Conclusion
The S4MC paper presents a novel confidence refinement scheme that enhances pseudo labels in semi-supervised semantic segmentation. By leveraging the spatial correlation of labels in segmentation maps, S4MC is able to increase the amount of unlabeled data used during training while maintaining the quality of the pseudo labels, leading to significant performance improvements over existing state-of-the-art methods.
This work demonstrates the value of incorporating contextual information to improve semi-supervised learning, and could have important implications for reducing the cost and effort required to train accurate semantic segmentation models. As the field of computer vision continues to advance, techniques like S4MC will play an increasingly important role in making these powerful AI systems more accessible and practical for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Semi-supervised Video Semantic Segmentation Using Unreliable Pseudo Labels for PVUW2024
Biao Wu, Diankai Zhang, Si Gao, Chengjian Zheng, Shaoli Liu, Ning Wang
0
0
Pixel-level Scene Understanding is one of the fundamental problems in computer vision, which aims at recognizing object classes, masks and semantics of each pixel in the given image. Compared with image scene parsing, video scene parsing introduces temporal information, which can effectively improve the consistency and accuracy of prediction,because the real-world is actually video-based rather than a static state. In this paper, we adopt semi-supervised video semantic segmentation method based on unreliable pseudo labels. Then, We ensemble the teacher network model with the student network model to generate pseudo labels and retrain the student network. Our method achieves the mIoU scores of 63.71% and 67.83% on development test and final test respectively. Finally, we obtain the 1st place in the Video Scene Parsing in the Wild Challenge at CVPR 2024.
6/4/2024
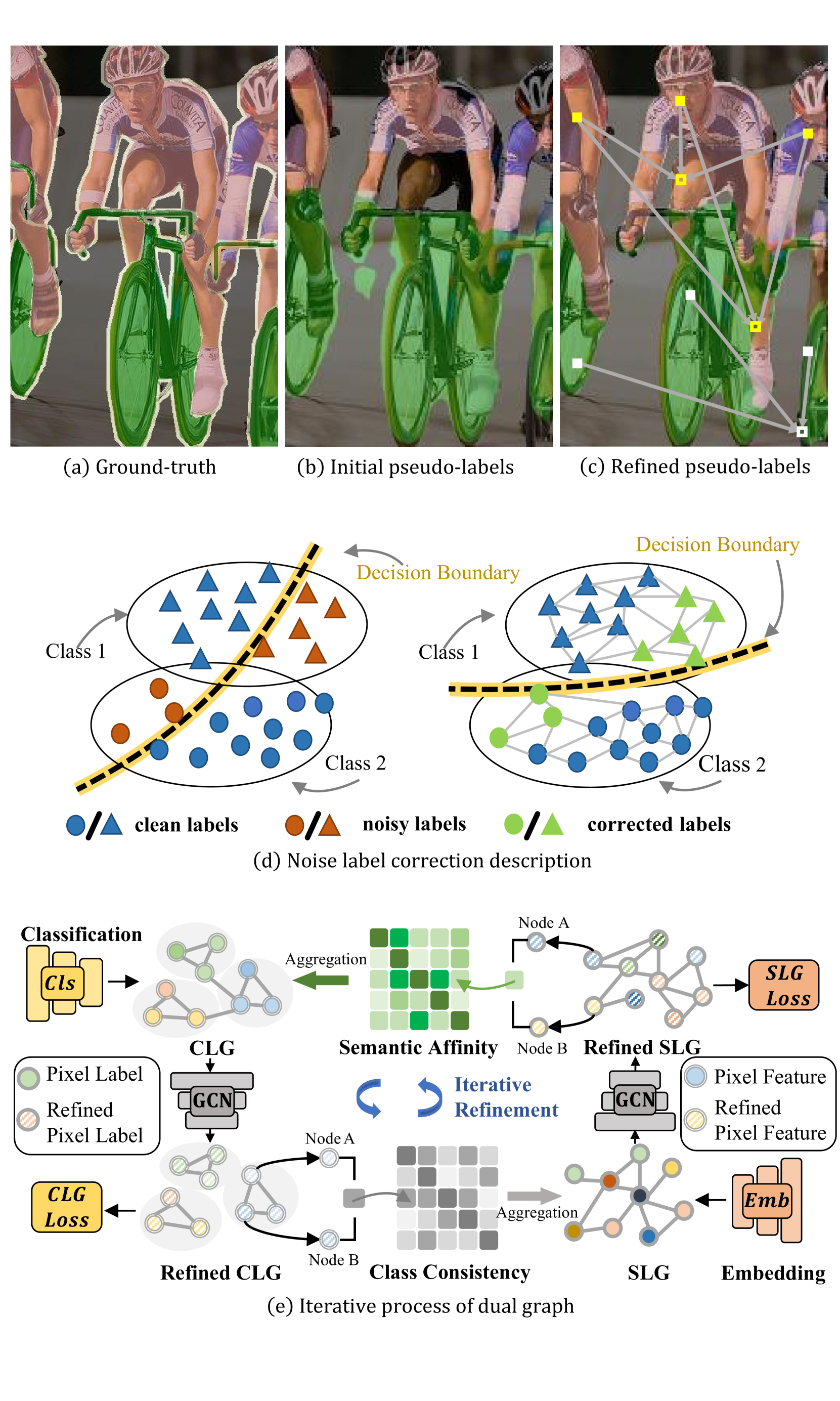
Multi-Level Label Correction by Distilling Proximate Patterns for Semi-supervised Semantic Segmentation
Hui Xiao, Yuting Hong, Li Dong, Diqun Yan, Jiayan Zhuang, Junjie Xiong, Dongtai Liang, Chengbin Peng
0
0
Semi-supervised semantic segmentation relieves the reliance on large-scale labeled data by leveraging unlabeled data. Recent semi-supervised semantic segmentation approaches mainly resort to pseudo-labeling methods to exploit unlabeled data. However, unreliable pseudo-labeling can undermine the semi-supervision processes. In this paper, we propose an algorithm called Multi-Level Label Correction (MLLC), which aims to use graph neural networks to capture structural relationships in Semantic-Level Graphs (SLGs) and Class-Level Graphs (CLGs) to rectify erroneous pseudo-labels. Specifically, SLGs represent semantic affinities between pairs of pixel features, and CLGs describe classification consistencies between pairs of pixel labels. With the support of proximate pattern information from graphs, MLLC can rectify incorrectly predicted pseudo-labels and can facilitate discriminative feature representations. We design an end-to-end network to train and perform this effective label corrections mechanism. Experiments demonstrate that MLLC can significantly improve supervised baselines and outperforms state-of-the-art approaches in different scenarios on Cityscapes and PASCAL VOC 2012 datasets. Specifically, MLLC improves the supervised baseline by at least 5% and 2% with DeepLabV2 and DeepLabV3+ respectively under different partition protocols.
4/11/2024
🖼️
Semi-supervised Medical Image Segmentation via Geometry-aware Consistency Training
Zihang Liu, Chunhui Zhao
0
0
The performance of supervised deep learning methods for medical image segmentation is often limited by the scarcity of labeled data. As a promising research direction, semi-supervised learning addresses this dilemma by leveraging unlabeled data information to assist the learning process. In this paper, a novel geometry-aware semi-supervised learning framework is proposed for medical image segmentation, which is a consistency-based method. Considering that the hard-to-segment regions are mainly located around the object boundary, we introduce an auxiliary prediction task to learn the global geometric information. Based on the geometric constraint, the ambiguous boundary regions are emphasized through an exponentially weighted strategy for the model training to better exploit both labeled and unlabeled data. In addition, a dual-view network is designed to perform segmentation from different perspectives and reduce the prediction uncertainty. The proposed method is evaluated on the public left atrium benchmark dataset and improves fully supervised method by 8.7% in Dice with 10% labeled images, while 4.3% with 20% labeled images. Meanwhile, our framework outperforms six state-of-the-art semi-supervised segmentation methods.
5/13/2024
🖼️
Leveraging Fixed and Dynamic Pseudo-labels for Semi-supervised Medical Image Segmentation
Suruchi Kumari, Pravendra Singh
0
0
Semi-supervised medical image segmentation has gained growing interest due to its ability to utilize unannotated data. The current state-of-the-art methods mostly rely on pseudo-labeling within a co-training framework. These methods depend on a single pseudo-label for training, but these labels are not as accurate as the ground truth of labeled data. Relying solely on one pseudo-label often results in suboptimal results. To this end, we propose a novel approach where multiple pseudo-labels for the same unannotated image are used to learn from the unlabeled data: the conventional fixed pseudo-label and the newly introduced dynamic pseudo-label. By incorporating multiple pseudo-labels for the same unannotated image into the co-training framework, our approach provides a more robust training approach that improves model performance and generalization capabilities. We validate our novel approach on three semi-supervised medical benchmark segmentation datasets, the Left Atrium dataset, the Pancreas-CT dataset, and the Brats-2019 dataset. Our approach significantly outperforms state-of-the-art methods over multiple medical benchmark segmentation datasets with different labeled data ratios. We also present several ablation experiments to demonstrate the effectiveness of various components used in our approach.
5/14/2024