Multi-Level Label Correction by Distilling Proximate Patterns for Semi-supervised Semantic Segmentation
2404.02065
0
0
Abstract
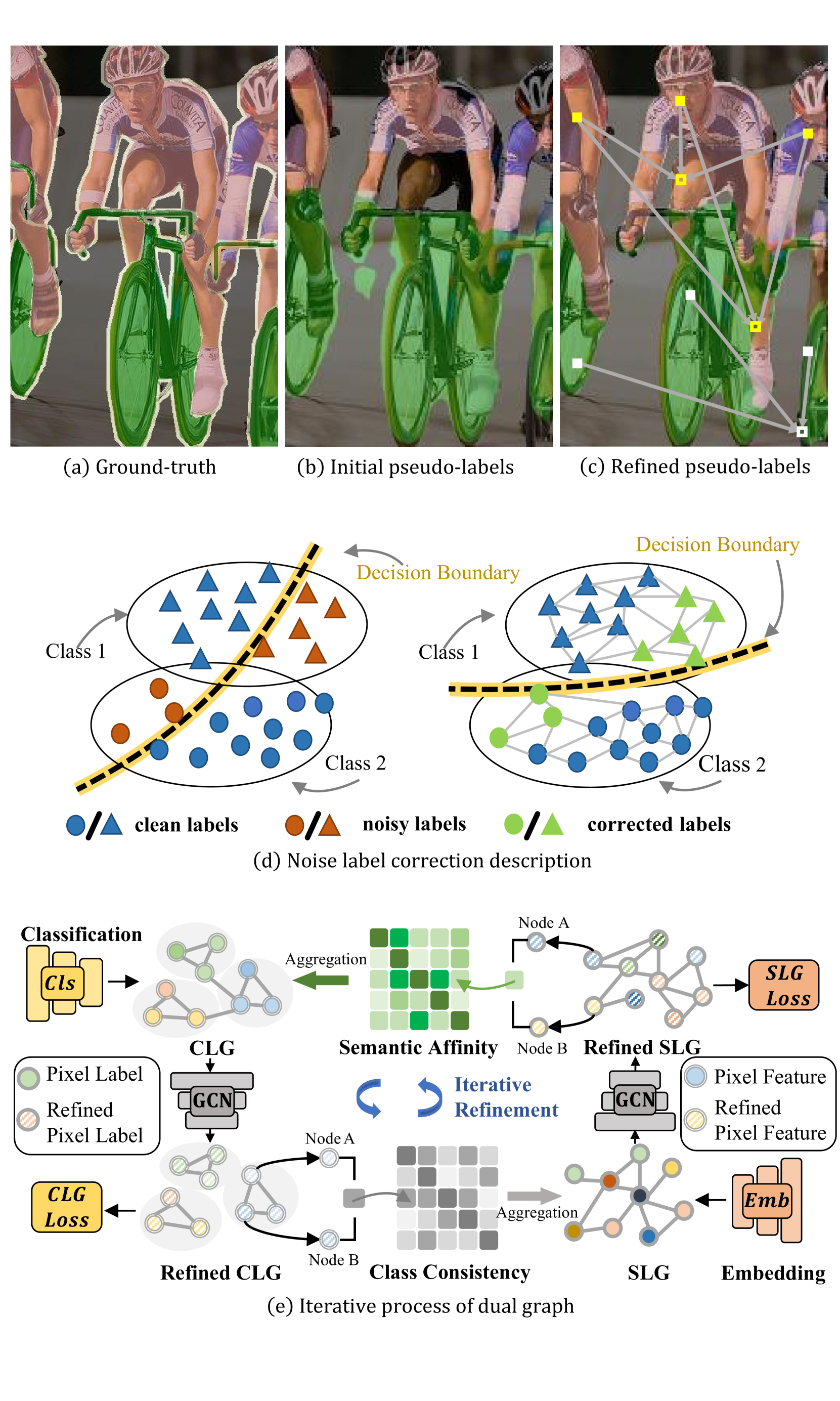
Semi-supervised semantic segmentation relieves the reliance on large-scale labeled data by leveraging unlabeled data. Recent semi-supervised semantic segmentation approaches mainly resort to pseudo-labeling methods to exploit unlabeled data. However, unreliable pseudo-labeling can undermine the semi-supervision processes. In this paper, we propose an algorithm called Multi-Level Label Correction (MLLC), which aims to use graph neural networks to capture structural relationships in Semantic-Level Graphs (SLGs) and Class-Level Graphs (CLGs) to rectify erroneous pseudo-labels. Specifically, SLGs represent semantic affinities between pairs of pixel features, and CLGs describe classification consistencies between pairs of pixel labels. With the support of proximate pattern information from graphs, MLLC can rectify incorrectly predicted pseudo-labels and can facilitate discriminative feature representations. We design an end-to-end network to train and perform this effective label corrections mechanism. Experiments demonstrate that MLLC can significantly improve supervised baselines and outperforms state-of-the-art approaches in different scenarios on Cityscapes and PASCAL VOC 2012 datasets. Specifically, MLLC improves the supervised baseline by at least 5% and 2% with DeepLabV2 and DeepLabV3+ respectively under different partition protocols.
Create account to get full access
Overview
- The paper proposes a semi-supervised semantic segmentation approach called "Multi-Level Label Correction by Distilling Proximate Patterns" (MLCD).
- The key ideas are to leverage unlabeled data and correct mistakes in pseudo-labels using a graph convolution network.
- The method aims to improve semantic segmentation performance in scenarios with limited labeled data.
Plain English Explanation
Semantic segmentation is the process of identifying and labeling different objects or regions within an image. This is an important task for many computer vision applications, such as self-driving cars and medical image analysis.
One challenge with semantic segmentation is that collecting and annotating large datasets can be time-consuming and expensive. The paper addresses this by using a semi-supervised approach, which means it leverages both labeled and unlabeled data.
The core idea is to first generate "pseudo-labels" for the unlabeled data using an initial model. However, these pseudo-labels may contain mistakes. The paper proposes a novel method to correct these errors by leveraging the relationships between neighboring pixels or regions in the image.
Specifically, the method uses a graph convolutional network to model the connections between similar pixels or regions. This allows the model to "distill" correct patterns from the labeled data and use them to refine the pseudo-labels for the unlabeled data. The authors call this "multi-level label correction" because it happens at different scales within the image.
By incorporating this label correction process, the model is able to learn more effectively from the unlabeled data and improve its overall segmentation performance, even when the amount of labeled data is limited.
Technical Explanation
The MLCD method consists of three main components:
-
Pseudo-Label Generation: An initial segmentation model is used to generate pseudo-labels for the unlabeled data. This provides a starting point for the semi-supervised learning process.
-
Multi-Level Graph Convolution: A graph convolutional network is used to model the relationships between neighboring pixels or regions in the image. This allows the model to capture the spatial and semantic context at multiple levels of granularity.
-
Label Correction: The graph convolution outputs are used to refine the pseudo-labels, correcting mistakes and aligning the labels with the true underlying structure of the data.
The key innovation is the use of the graph convolution to leverage the intrinsic structure of the image data, rather than treating each pixel or region in isolation. This allows the model to learn more robust and accurate segmentation models, even when only a small amount of labeled data is available.
Critical Analysis
The paper provides a thorough evaluation of the MLCD method on several standard semantic segmentation datasets, demonstrating consistent improvements over baseline semi-supervised approaches. However, the authors acknowledge that the method relies on the initial pseudo-label quality, which could be a limitation in scenarios with very limited labeled data.
Additionally, the graph convolution process adds computational complexity, which may impact inference speed. Further research could explore ways to strike a better balance between accuracy and efficiency.
Overall, the MLCD method represents a promising direction for leveraging unlabeled data to improve semantic segmentation, particularly in settings with scarce labeled examples. The technical insights on using graph-based reasoning to refine pseudo-labels are likely to inspire future work in this area.
Conclusion
The "Multi-Level Label Correction by Distilling Proximate Patterns" (MLCD) method addresses the challenge of performing accurate semantic segmentation with limited labeled data. By generating pseudo-labels for unlabeled data and then refining them using a graph convolutional network, the approach is able to effectively leverage both labeled and unlabeled information.
This semi-supervised technique could have important practical implications, as it can help reduce the manual effort required to annotate large-scale datasets for semantic segmentation tasks. The technical insights on using graph-based reasoning to model spatial and semantic context could also inspire further advancements in this area of computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LayerMatch: Do Pseudo-labels Benefit All Layers?
Chaoqi Liang, Guanglei Yang, Lifeng Qiao, Zitong Huang, Hongliang Yan, Yunchao Wei, Wangmeng Zuo
0
0
Deep neural networks have achieved remarkable performance across various tasks when supplied with large-scale labeled data. However, the collection of labeled data can be time-consuming and labor-intensive. Semi-supervised learning (SSL), particularly through pseudo-labeling algorithms that iteratively assign pseudo-labels for self-training, offers a promising solution to mitigate the dependency of labeled data. Previous research generally applies a uniform pseudo-labeling strategy across all model layers, assuming that pseudo-labels exert uniform influence throughout. Contrasting this, our theoretical analysis and empirical experiment demonstrate feature extraction layer and linear classification layer have distinct learning behaviors in response to pseudo-labels. Based on these insights, we develop two layer-specific pseudo-label strategies, termed Grad-ReLU and Avg-Clustering. Grad-ReLU mitigates the impact of noisy pseudo-labels by removing the gradient detrimental effects of pseudo-labels in the linear classification layer. Avg-Clustering accelerates the convergence of feature extraction layer towards stable clustering centers by integrating consistent outputs. Our approach, LayerMatch, which integrates these two strategies, can avoid the severe interference of noisy pseudo-labels in the linear classification layer while accelerating the clustering capability of the feature extraction layer. Through extensive experimentation, our approach consistently demonstrates exceptional performance on standard semi-supervised learning benchmarks, achieving a significant improvement of 10.38% over baseline method and a 2.44% increase compared to state-of-the-art methods.
6/28/2024
📶
New!Semi-Supervised Semantic Segmentation via Marginal Contextual Information
Moshe Kimhi, Shai Kimhi, Evgenii Zheltonozhskii, Or Litany, Chaim Baskin
0
0
We present a novel confidence refinement scheme that enhances pseudo labels in semi-supervised semantic segmentation. Unlike existing methods, which filter pixels with low-confidence predictions in isolation, our approach leverages the spatial correlation of labels in segmentation maps by grouping neighboring pixels and considering their pseudo labels collectively. With this contextual information, our method, named S4MC, increases the amount of unlabeled data used during training while maintaining the quality of the pseudo labels, all with negligible computational overhead. Through extensive experiments on standard benchmarks, we demonstrate that S4MC outperforms existing state-of-the-art semi-supervised learning approaches, offering a promising solution for reducing the cost of acquiring dense annotations. For example, S4MC achieves a 1.39 mIoU improvement over the prior art on PASCAL VOC 12 with 366 annotated images. The code to reproduce our experiments is available at https://s4mcontext.github.io/
7/4/2024
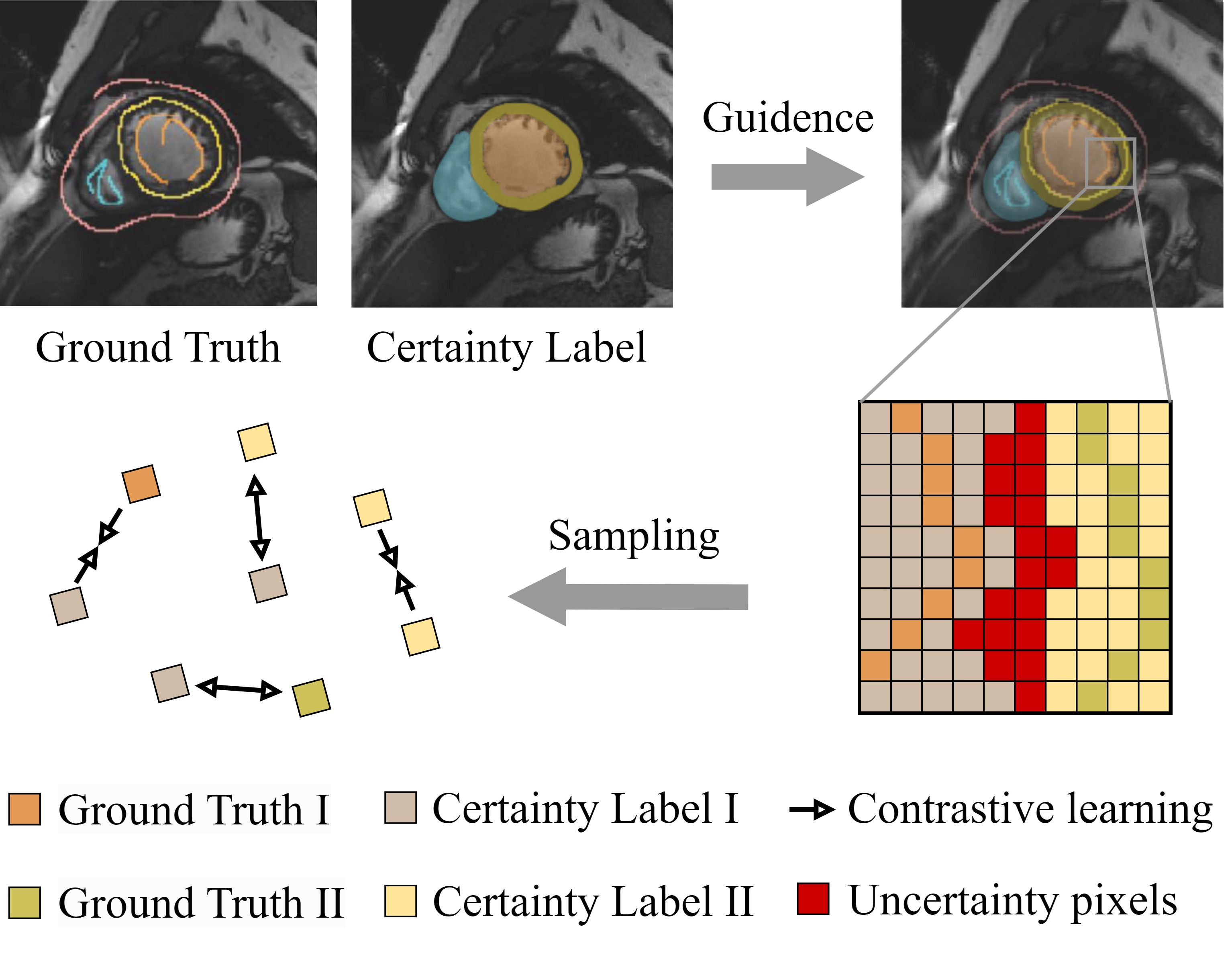
PCLMix: Weakly Supervised Medical Image Segmentation via Pixel-Level Contrastive Learning and Dynamic Mix Augmentation
Yu Lei, Haolun Luo, Lituan Wang, Zhenwei Zhang, Lei Zhang
0
0
In weakly supervised medical image segmentation, the absence of structural priors and the discreteness of class feature distribution present a challenge, i.e., how to accurately propagate supervision signals from local to global regions without excessively spreading them to other irrelevant regions? To address this, we propose a novel weakly supervised medical image segmentation framework named PCLMix, comprising dynamic mix augmentation, pixel-level contrastive learning, and consistency regularization strategies. Specifically, PCLMix is built upon a heterogeneous dual-decoder backbone, addressing the absence of structural priors through a strategy of dynamic mix augmentation during training. To handle the discrete distribution of class features, PCLMix incorporates pixel-level contrastive learning based on prediction uncertainty, effectively enhancing the model's ability to differentiate inter-class pixel differences and intra-class consistency. Furthermore, to reinforce segmentation consistency and robustness, PCLMix employs an auxiliary decoder for dual consistency regularization. In the inference phase, the auxiliary decoder will be dropped and no computation complexity is increased. Extensive experiments on the ACDC dataset demonstrate that PCLMix appropriately propagates local supervision signals to the global scale, further narrowing the gap between weakly supervised and fully supervised segmentation methods. Our code is available at https://github.com/Torpedo2648/PCLMix.
5/21/2024

Graph Partial Label Learning with Potential Cause Discovering
Hang Gao, Jiaguo Yuan, Jiangmeng Li, Peng Qiao, Fengge Wu, Changwen Zheng, Huaping Liu
0
0
Graph Neural Networks (GNNs) have garnered widespread attention for their potential to address the challenges posed by graph representation learning, which face complex graph-structured data across various domains. However, due to the inherent complexity and interconnectedness of graphs, accurately annotating graph data for training GNNs is extremely challenging. To address this issue, we have introduced Partial Label Learning (PLL) into graph representation learning. PLL is a critical weakly supervised learning problem where each training instance is associated with a set of candidate labels, including the ground-truth label and the additional interfering labels. PLL allows annotators to make errors, which reduces the difficulty of data labeling. Subsequently, we propose a novel graph representation learning method that enables GNN models to effectively learn discriminative information within the context of PLL. Our approach utilizes potential cause extraction to obtain graph data that holds causal relationships with the labels. By conducting auxiliary training based on the extracted graph data, our model can effectively eliminate the interfering information in the PLL scenario. We support the rationale behind our method with a series of theoretical analyses. Moreover, we conduct extensive evaluations and ablation studies on multiple datasets, demonstrating the superiority of our proposed method.
5/24/2024