SemioLLM: Assessing Large Language Models for Semiological Analysis in Epilepsy Research

0
Sign in to get full access
Overview
- This paper, titled "SemioLLM: Assessing Large Language Models for Semiological Analysis in Epilepsy Research," explores the use of large language models (LLMs) for semiological analysis in the field of epilepsy research.
- Semiological analysis involves the study of epileptic seizure symptoms, which can provide valuable insights into the underlying neurological mechanisms and help with diagnosis and treatment.
- The researchers investigate the potential of LLMs, such as BERT and GPT-3, to assist in the semiological analysis of epilepsy data.
Plain English Explanation
The paper focuses on using advanced AI models, called large language models (LLMs), to help understand and analyze the symptoms of epilepsy. Epilepsy is a neurological condition where people experience seizures, and the symptoms of these seizures can provide important clues about what's happening in the brain. The researchers wanted to see if LLMs, which are very good at processing and understanding natural language, could be used to analyze the descriptions of epilepsy symptoms and potentially aid in diagnosis and treatment. They compared the performance of different LLMs on this task to see which ones were most effective. This could be a valuable tool for researchers and clinicians working in the field of epilepsy.
Technical Explanation
The paper investigates the use of BERT, GPT-3, and other LLMs for semiological analysis in epilepsy research. The researchers developed a dataset of epilepsy case reports and annotations, which they used to evaluate the performance of the LLMs on tasks like symptom identification, seizure type classification, and syndrome diagnosis. They compared the LLM-based approaches to traditional machine learning methods and found that the LLMs generally outperformed the traditional models, especially in more complex tasks that require contextual understanding of the language.
Critical Analysis
The paper acknowledges several limitations and areas for further research. For example, the dataset used was relatively small, and the researchers note that larger and more diverse datasets would be needed to fully assess the capabilities of the LLMs. Additionally, the paper does not explore the interpretability and explainability of the LLM-based predictions, which could be an important consideration for clinical applications. Further research is needed to understand how these models arrive at their conclusions and to ensure their reliability and trustworthiness.
Conclusion
Overall, this paper presents a promising approach for leveraging the power of large language models to assist in the semiological analysis of epilepsy data. The results suggest that LLMs can outperform traditional machine learning methods in tasks like symptom identification and seizure type classification. While more research is needed, this work highlights the potential of LLMs to enhance epilepsy research and, ultimately, improve patient care.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SemioLLM: Assessing Large Language Models for Semiological Analysis in Epilepsy Research
Meghal Dani, Muthu Jeyanthi Prakash, Zeynep Akata, Stefanie Liebe
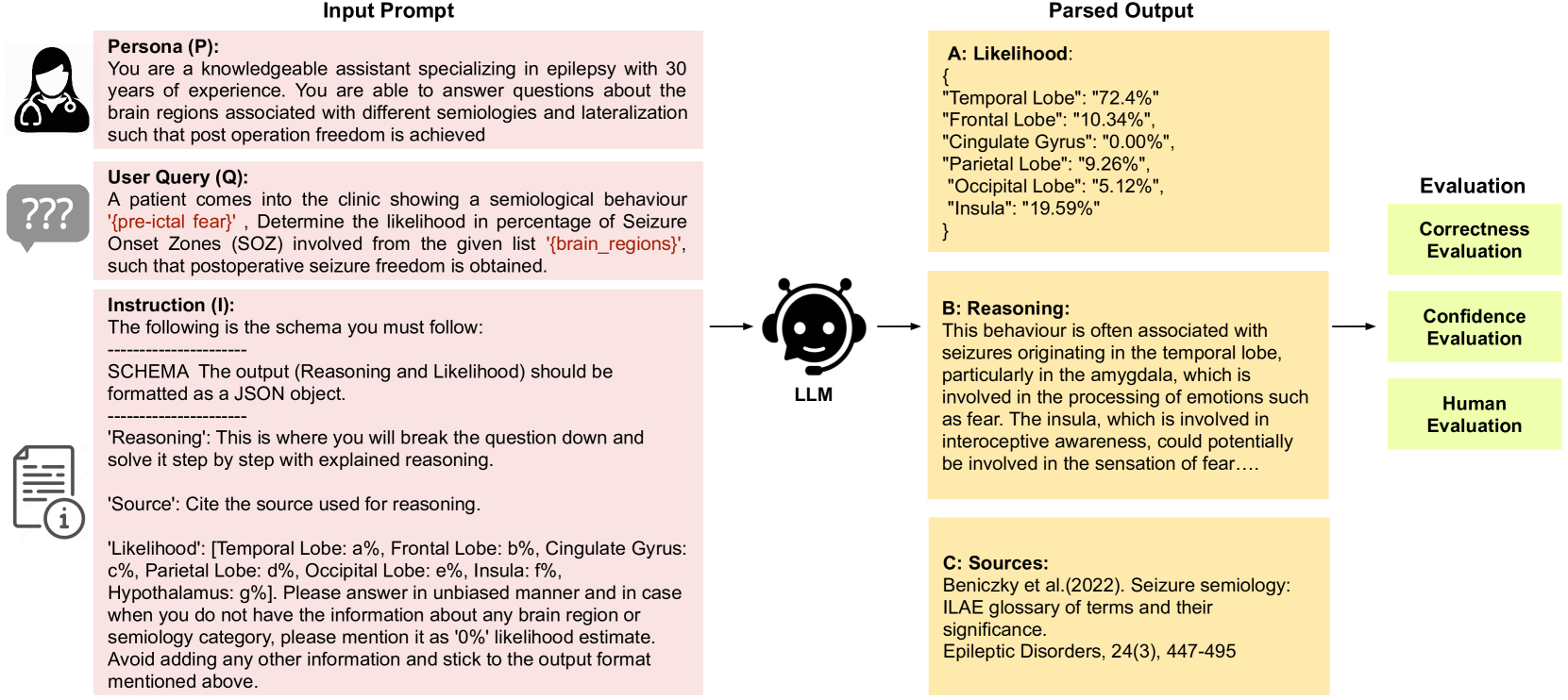
Large Language Models have shown promising results in their ability to encode general medical knowledge in standard medical question-answering datasets. However, their potential application in clinical practice requires evaluation in domain-specific tasks, where benchmarks are largely missing. In this study semioLLM, we test the ability of state-of-the-art LLMs (GPT-3.5, GPT-4, Mixtral 8x7B, and Qwen-72chat) to leverage their internal knowledge and reasoning for epilepsy diagnosis. Specifically, we obtain likelihood estimates linking unstructured text descriptions of seizures to seizure-generating brain regions, using an annotated clinical database containing 1269 entries. We evaluate the LLM's performance, confidence, reasoning, and citation abilities in comparison to clinical evaluation. Models achieve above-chance classification performance with prompt engineering significantly improving their outcome, with some models achieving close-to-clinical performance and reasoning. However, our analyses also reveal significant pitfalls with several models being overly confident while showing poor performance, as well as exhibiting citation errors and hallucinations. In summary, our work provides the first extensive benchmark comparing current SOTA LLMs in the medical domain of epilepsy and highlights their ability to leverage unstructured texts from patients' medical history to aid diagnostic processes in health care.
Read more7/4/2024
🤯
0
D-NLP at SemEval-2024 Task 2: Evaluating Clinical Inference Capabilities of Large Language Models
Duygu Altinok
Large language models (LLMs) have garnered significant attention and widespread usage due to their impressive performance in various tasks. However, they are not without their own set of challenges, including issues such as hallucinations, factual inconsistencies, and limitations in numerical-quantitative reasoning. Evaluating LLMs in miscellaneous reasoning tasks remains an active area of research. Prior to the breakthrough of LLMs, Transformers had already proven successful in the medical domain, effectively employed for various natural language understanding (NLU) tasks. Following this trend, LLMs have also been trained and utilized in the medical domain, raising concerns regarding factual accuracy, adherence to safety protocols, and inherent limitations. In this paper, we focus on evaluating the natural language inference capabilities of popular open-source and closed-source LLMs using clinical trial reports as the dataset. We present the performance results of each LLM and further analyze their performance on a development set, particularly focusing on challenging instances that involve medical abbreviations and require numerical-quantitative reasoning. Gemini, our leading LLM, achieved a test set F1-score of 0.748, securing the ninth position on the task scoreboard. Our work is the first of its kind, offering a thorough examination of the inference capabilities of LLMs within the medical domain.
Read more5/8/2024
0
MedREQAL: Examining Medical Knowledge Recall of Large Language Models via Question Answering
Juraj Vladika, Phillip Schneider, Florian Matthes
In recent years, Large Language Models (LLMs) have demonstrated an impressive ability to encode knowledge during pre-training on large text corpora. They can leverage this knowledge for downstream tasks like question answering (QA), even in complex areas involving health topics. Considering their high potential for facilitating clinical work in the future, understanding the quality of encoded medical knowledge and its recall in LLMs is an important step forward. In this study, we examine the capability of LLMs to exhibit medical knowledge recall by constructing a novel dataset derived from systematic reviews -- studies synthesizing evidence-based answers for specific medical questions. Through experiments on the new MedREQAL dataset, comprising question-answer pairs extracted from rigorous systematic reviews, we assess six LLMs, such as GPT and Mixtral, analyzing their classification and generation performance. Our experimental insights into LLM performance on the novel biomedical QA dataset reveal the still challenging nature of this task.
Read more6/11/2024

0
A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better protection of patient privacy compared to API-based solutions. This survey systematically explores how to train medical LLMs based on general LLMs. It covers: (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose a appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising future research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants.
Read more6/18/2024