Separate and Reconstruct: Asymmetric Encoder-Decoder for Speech Separation

0

Sign in to get full access
Overview
- The paper proposes a new model called "Separate and Reconstruct" for single-channel speech separation.
- The model uses an asymmetric encoder-decoder architecture to separate and reconstruct speech sources.
- The authors claim this approach outperforms existing methods on standard speech separation benchmarks.
Plain English Explanation
The goal of speech separation is to take a recording with multiple people talking at the same time and extract the individual speech signals. This is a challenging problem, as the voices can overlap and interfere with each other.
The "Separate and Reconstruct" model aims to solve this by using an encoder-decoder neural network. The encoder first separates the mixed speech into individual source signals. Then the decoder reconstructs each source, cleaning up the signal and making it sound more natural.
The key innovation is that the encoder and decoder have different architectures, allowing them to specialize in their respective tasks of separation and reconstruction. This asymmetric design is what gives the model its strength, outperforming previous speech separation approaches.
The authors demonstrate the effectiveness of their model on standard speech separation benchmarks, where it achieves state-of-the-art performance. This suggests the "Separate and Reconstruct" approach is a promising direction for building more robust and accurate speech separation systems.
Technical Explanation
The paper proposes a new model called "Separate and Reconstruct" for single-channel speech separation. The core idea is to use an asymmetric encoder-decoder architecture, where the encoder and decoder have different designs optimized for the tasks of separation and reconstruction, respectively.
The encoder first takes the mixed speech input and separates it into individual source signals. It uses a convolutional neural network (CNN) with dilated convolutions to capture long-range dependencies in the speech. The decoder then reconstructs each source signal independently, using a more complex recurrent neural network (RNN) architecture to generate high-quality waveforms.
The asymmetric design allows the encoder to focus on the separation task, while the decoder can specialize in the more challenging reconstruction step. The authors argue this division of labor leads to superior performance compared to previous symmetric encoder-decoders.
The model is evaluated on standard speech separation benchmarks like WSJ0-2mix and LibriSpeech, where it achieves state-of-the-art results. Ablation studies demonstrate the importance of the asymmetric architecture, as well as other key design choices like the use of dilated convolutions.
Critical Analysis
The paper presents a well-designed and effective speech separation model. The core contribution of the asymmetric encoder-decoder architecture is compelling, and the experimental results convincingly demonstrate its advantages over prior work.
However, the authors do not delve deeply into the limitations or potential downsides of their approach. For example, the model may struggle with highly overlapping or noisy speech, or it may not generalize well to speakers or acoustic conditions not seen during training.
Additionally, the model's computational complexity and inference latency are not discussed. These factors could be important for real-world deployment, especially in applications like real-time teleconferencing or hearing aids.
Further research is needed to explore the robustness and generalization capabilities of the "Separate and Reconstruct" model, as well as to understand its practical tradeoffs in terms of efficiency and deployability. Nevertheless, this work represents a significant advance in the field of single-channel speech separation.
Conclusion
The "Separate and Reconstruct" model proposed in this paper is a novel and effective approach to single-channel speech separation. By using an asymmetric encoder-decoder architecture, the model is able to outperform previous methods on standard benchmarks.
This research demonstrates the potential benefits of tailoring neural network components to specific subtasks, rather than using a one-size-fits-all design. The separation and reconstruction stages of speech separation can be better addressed by distinct modules, leading to improved overall performance.
While the paper does not address all potential limitations, the "Separate and Reconstruct" model represents an important step forward in building more robust and accurate speech separation systems. As the field continues to evolve, this work may inspire further innovations and pave the way for practical applications in areas like teleconferencing, hearing assistive devices, and audio processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Separate and Reconstruct: Asymmetric Encoder-Decoder for Speech Separation
Ui-Hyeop Shin, Sangyoun Lee, Taehan Kim, Hyung-Min Park
Since the success of a time-domain speech separation, further improvements have been made by expanding the length and channel of a feature sequence to increase the amount of computation. When temporally expanded to a long sequence, the feature is segmented into chunks as a dual-path model in most studies of speech separation. In particular, it is common for the process of separating features corresponding to each speaker to be located in the final stage of the network. However, it is more advantageous and intuitive to proactively expand the feature sequence to include the number of speakers as an extra dimension. In this paper, we present an asymmetric strategy in which the encoder and decoder are partitioned to perform distinct processing in separation tasks. The encoder analyzes features, and the output of the encoder is split into the number of speakers to be separated. The separated sequences are then reconstructed by the weight-shared decoder, as Siamese network, in addition to cross-speaker processing. By using the Siamese network in the decoder, without using speaker information, the network directly learns to discriminate the features using a separation objective. With a common split layer, intermediate encoder features for skip connections are also split for the reconstruction decoder based on the U-Net structure. In addition, instead of segmenting the feature into chunks as dual-path, we design global and local Transformer blocks to directly process long sequences. The experimental results demonstrated that this separation-and-reconstruction framework is effective and that the combination of proposed global and local Transformer can sufficiently replace the role of inter- and intra-chunk processing in dual-path structure. Finally, the presented model including both of these achieved state-of-the-art performance with less computation than before in various benchmark datasets.
Read more6/11/2024

0
Joint Speaker Features Learning for Audio-visual Multichannel Speech Separation and Recognition
Guinan Li, Jiajun Deng, Youjun Chen, Mengzhe Geng, Shujie Hu, Zhe Li, Zengrui Jin, Tianzi Wang, Xurong Xie, Helen Meng, Xunying Liu
This paper proposes joint speaker feature learning methods for zero-shot adaptation of audio-visual multichannel speech separation and recognition systems. xVector and ECAPA-TDNN speaker encoders are connected using purpose-built fusion blocks and tightly integrated with the complete system training. Experiments conducted on LRS3-TED data simulated multichannel overlapped speech suggest that joint speaker feature learning consistently improves speech separation and recognition performance over the baselines without joint speaker feature estimation. Further analyses reveal performance improvements are strongly correlated with increased inter-speaker discrimination measured using cosine similarity. The best-performing joint speaker feature learning adapted system outperformed the baseline fine-tuned WavLM model by statistically significant WER reductions of 21.6% and 25.3% absolute (67.5% and 83.5% relative) on Dev and Test sets after incorporating WavLM features and video modality.
Read more6/17/2024
0
DualSep: A Light-weight dual-encoder convolutional recurrent network for real-time in-car speech separation
Ziqian Wang, Jiayao Sun, Zihan Zhang, Xingchen Li, Jie Liu, Lei Xie
Advancements in deep learning and voice-activated technologies have driven the development of human-vehicle interaction. Distributed microphone arrays are widely used in in-car scenarios because they can accurately capture the voices of passengers from different speech zones. However, the increase in the number of audio channels, coupled with the limited computational resources and low latency requirements of in-car systems, presents challenges for in-car multi-channel speech separation. To migrate the problems, we propose a lightweight framework that cascades digital signal processing (DSP) and neural networks (NN). We utilize fixed beamforming (BF) to reduce computational costs and independent vector analysis (IVA) to provide spatial prior. We employ dual encoders for dual-branch modeling, with spatial encoder capturing spatial cues and spectral encoder preserving spectral information, facilitating spatial-spectral fusion. Our proposed system supports both streaming and non-streaming modes. Experimental results demonstrate the superiority of the proposed system across various metrics. With only 0.83M parameters and 0.39 real-time factor (RTF) on an Intel Core i7 (2.6GHz) CPU, it effectively separates speech into distinct speech zones. Our demos are available at https://honee-w.github.io/DualSep/.
Read more9/16/2024
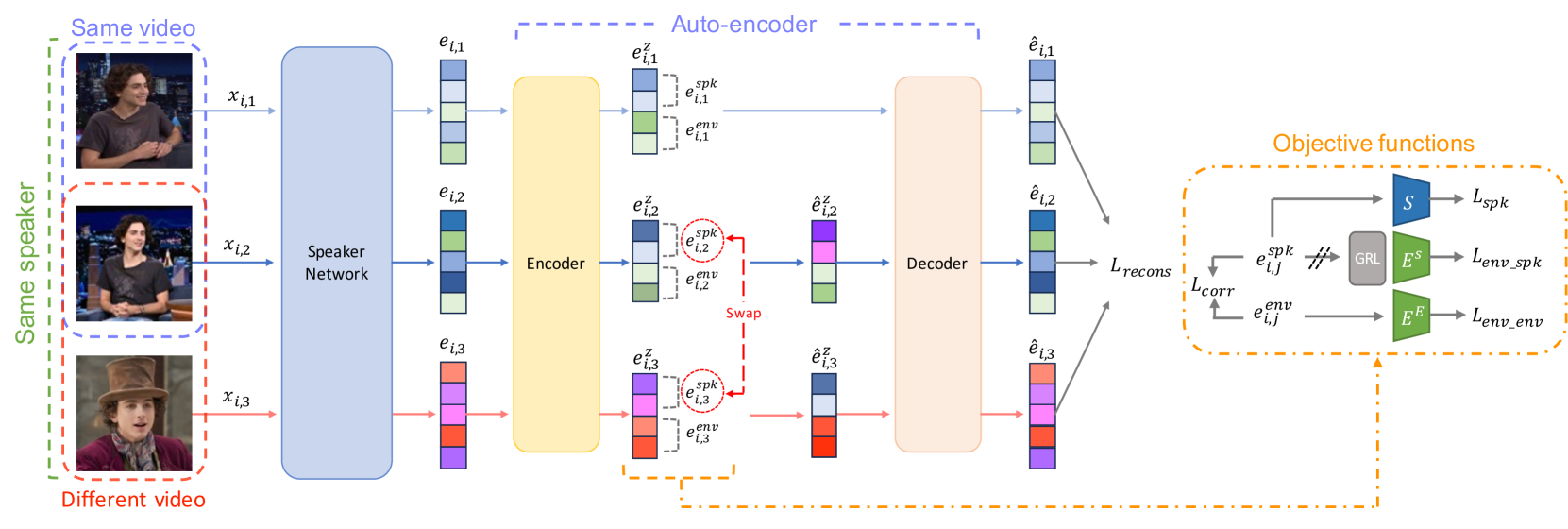
0
Disentangled Representation Learning for Environment-agnostic Speaker Recognition
KiHyun Nam, Hee-Soo Heo, Jee-weon Jung, Joon Son Chung
This work presents a framework based on feature disentanglement to learn speaker embeddings that are robust to environmental variations. Our framework utilises an auto-encoder as a disentangler, dividing the input speaker embedding into components related to the speaker and other residual information. We employ a group of objective functions to ensure that the auto-encoder's code representation - used as the refined embedding - condenses only the speaker characteristics. We show the versatility of our framework through its compatibility with any existing speaker embedding extractor, requiring no structural modifications or adaptations for integration. We validate the effectiveness of our framework by incorporating it into two popularly used embedding extractors and conducting experiments across various benchmarks. The results show a performance improvement of up to 16%. We release our code for this work to be available https://github.com/kaistmm/voxceleb-disentangler
Read more6/21/2024