Sequential Disentanglement by Extracting Static Information From A Single Sequence Element

0

Sign in to get full access
Overview
- This paper introduces a novel method for sequentially disentangling information from a single sequence element.
- The approach extracts "static" information that remains constant across a sequence, rather than relying on dynamic changes over time.
- The authors demonstrate the effectiveness of their method on several tasks, including time series classification and disentangled representation learning.
Plain English Explanation
The paper presents a new way to extract meaningful information from sequential data, such as video or audio recordings. Traditional methods often focus on how the data changes over time, but this new approach instead looks for the underlying "static" information that remains constant throughout the sequence.
Imagine you're watching a video of a person speaking. Even as the person's facial expressions and body movements change, there are certain features that stay the same, like their identity, gender, or native language. The authors' method aims to identify and separate out these constant, or "static," aspects of the data, rather than just looking at how it evolves over time.
By isolating this static information, the researchers show they can improve the performance of machine learning models on tasks like classifying time series data or learning disentangled representations - representations that capture different independent factors of variation in the data. This could be useful in applications like speech recognition, image analysis, or medical diagnostics, where being able to focus on the key underlying characteristics is important.
The core insight is that there is often valuable information "hidden" in individual data points that gets lost when we only consider how the data changes over time. This new method provides a way to extract and leverage that static information, leading to better model performance and more interpretable representations of the underlying phenomena.
Technical Explanation
The key innovation in this paper is a new approach for sequentially disentangling information from a single sequence element. Rather than relying on temporal dynamics to disentangle latent factors, as in previous work (Comparing Information Content of Representation Spaces for Disentanglement in VAEs, Improving Reconstruction for Disentangled Representation Learners), the authors propose extracting "static" information that is constant across the sequence.
The method first encodes each sequence element into a latent representation. It then uses a neural network to predict a set of "static" latent variables from a single sequence element, which are constrained to be consistent across the entire sequence. This allows the model to isolate the constant, underlying factors in the data while still capturing the dynamic, time-varying aspects.
The authors evaluate their approach on several tasks, including time series classification and disentangled representation learning. They demonstrate that by focusing on the static information, their method can outperform baselines that rely more heavily on the temporal evolution of the data.
One key challenge in this area is the combinatorial nature of disentangled representations. The authors' approach aims to address this by identifying the most salient static factors, rather than attempting to disentangle all possible factors of variation.
Critical Analysis
The authors provide a compelling demonstration of the value of extracting static information from sequential data. By isolating the constant underlying factors, their method can learn more robust and interpretable representations, with benefits for downstream tasks.
However, the paper does not fully address the potential limitations of this approach. For example, it's unclear how well the method would scale to more complex, high-dimensional sequences, where the distinction between static and dynamic information may be less clear-cut. Additionally, the authors do not explore the sensitivity of their approach to noise or missing data in the input sequences.
Another potential issue is the reliance on neural networks to predict the static latent variables. While this allows for flexibility in modeling the relationships, it also introduces additional complexity and potential for overfitting. It may be worthwhile to explore simpler, more constrained approaches to static information extraction.
Despite these caveats, the core insight of the paper - that valuable information can be encoded in individual data points, rather than just in their temporal dynamics - is an important one. As the authors suggest, this could have broad implications for a range of application domains, from speech recognition to medical diagnostics. Further research is needed to fully understand the limitations and potential of this approach.
Conclusion
This paper presents a novel method for sequentially disentangling information from a single sequence element, by extracting the "static" information that remains constant across the sequence. The authors demonstrate the effectiveness of this approach on several tasks, including time series classification and disentangled representation learning.
The key contribution is the insight that valuable information can be encoded in individual data points, rather than just in their temporal dynamics. By isolating these constant, underlying factors, the method can learn more robust and interpretable representations, with potential benefits for a wide range of applications.
While the paper does not address all the potential limitations of this approach, it represents an important step forward in our understanding of how to effectively leverage sequential data. As the field of machine learning continues to grapple with the challenges of disentangled representation learning, this work provides a promising new direction for research and exploration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Sequential Disentanglement by Extracting Static Information From A Single Sequence Element
Nimrod Berman, Ilan Naiman, Idan Arbiv, Gal Fadlon, Omri Azencot
One of the fundamental representation learning tasks is unsupervised sequential disentanglement, where latent codes of inputs are decomposed to a single static factor and a sequence of dynamic factors. To extract this latent information, existing methods condition the static and dynamic codes on the entire input sequence. Unfortunately, these models often suffer from information leakage, i.e., the dynamic vectors encode both static and dynamic information, or vice versa, leading to a non-disentangled representation. Attempts to alleviate this problem via reducing the dynamic dimension and auxiliary loss terms gain only partial success. Instead, we propose a novel and simple architecture that mitigates information leakage by offering a simple and effective subtraction inductive bias while conditioning on a single sample. Remarkably, the resulting variational framework is simpler in terms of required loss terms, hyperparameters, and data augmentation. We evaluate our method on multiple data-modality benchmarks including general time series, video, and audio, and we show beyond state-of-the-art results on generation and prediction tasks in comparison to several strong baselines.
Read more6/27/2024

0
Sequential Representation Learning via Static-Dynamic Conditional Disentanglement
Mathieu Cyrille Simon, Pascal Frossard, Christophe De Vleeschouwer
This paper explores self-supervised disentangled representation learning within sequential data, focusing on separating time-independent and time-varying factors in videos. We propose a new model that breaks the usual independence assumption between those factors by explicitly accounting for the causal relationship between the static/dynamic variables and that improves the model expressivity through additional Normalizing Flows. A formal definition of the factors is proposed. This formalism leads to the derivation of sufficient conditions for the ground truth factors to be identifiable, and to the introduction of a novel theoretically grounded disentanglement constraint that can be directly and efficiently incorporated into our new framework. The experiments show that the proposed approach outperforms previous complex state-of-the-art techniques in scenarios where the dynamics of a scene are influenced by its content.
Read more8/13/2024
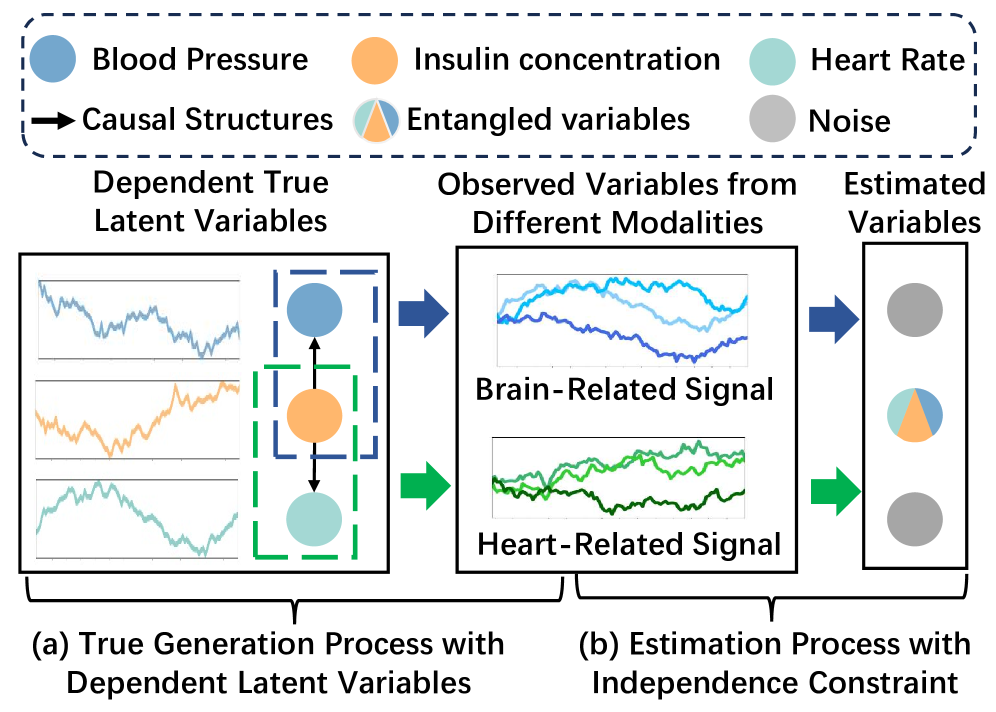
0
From Orthogonality to Dependency: Learning Disentangled Representation for Multi-Modal Time-Series Sensing Signals
Ruichu Cai, Zhifang Jiang, Zijian Li, Weilin Chen, Xuexin Chen, Zhifeng Hao, Yifan Shen, Guangyi Chen, Kun Zhang
Existing methods for multi-modal time series representation learning aim to disentangle the modality-shared and modality-specific latent variables. Although achieving notable performances on downstream tasks, they usually assume an orthogonal latent space. However, the modality-specific and modality-shared latent variables might be dependent on real-world scenarios. Therefore, we propose a general generation process, where the modality-shared and modality-specific latent variables are dependent, and further develop a textbf{M}ulti-modtextbf{A}l textbf{TE}mporal Disentanglement (textbf{MATE}) model. Specifically, our textbf{MATE} model is built on a temporally variational inference architecture with the modality-shared and modality-specific prior networks for the disentanglement of latent variables. Furthermore, we establish identifiability results to show that the extracted representation is disentangled. More specifically, we first achieve the subspace identifiability for modality-shared and modality-specific latent variables by leveraging the pairing of multi-modal data. Then we establish the component-wise identifiability of modality-specific latent variables by employing sufficient changes of historical latent variables. Extensive experimental studies on multi-modal sensors, human activity recognition, and healthcare datasets show a general improvement in different downstream tasks, highlighting the effectiveness of our method in real-world scenarios.
Read more5/28/2024
⛏️
0
Disentangled Representation Learning with Transmitted Information Bottleneck
Zhuohang Dang, Minnan Luo, Chengyou Jia, Guang Dai, Jihong Wang, Xiaojun Chang, Jingdong Wang
Encoding only the task-related information from the raw data, ie, disentangled representation learning, can greatly contribute to the robustness and generalizability of models. Although significant advances have been made by regularizing the information in representations with information theory, two major challenges remain: 1) the representation compression inevitably leads to performance drop; 2) the disentanglement constraints on representations are in complicated optimization. To these issues, we introduce Bayesian networks with transmitted information to formulate the interaction among input and representations during disentanglement. Building upon this framework, we propose textbf{DisTIB} (textbf{T}ransmitted textbf{I}nformation textbf{B}ottleneck for textbf{Dis}entangled representation learning), a novel objective that navigates the balance between information compression and preservation. We employ variational inference to derive a tractable estimation for DisTIB. This estimation can be simply optimized via standard gradient descent with a reparameterization trick. Moreover, we theoretically prove that DisTIB can achieve optimal disentanglement, underscoring its superior efficacy. To solidify our claims, we conduct extensive experiments on various downstream tasks to demonstrate the appealing efficacy of DisTIB and validate our theoretical analyses.
Read more8/15/2024