Sequential Recommendation for Optimizing Both Immediate Feedback and Long-term Retention

0
Sign in to get full access
Overview
- This paper proposes a sequential recommendation model that aims to optimize both immediate user feedback and long-term retention.
- The model leverages a multi-task learning approach to jointly optimize for short-term engagement and long-term learning.
- The authors evaluate their model on real-world datasets and find it outperforms existing recommendation methods.
Plain English Explanation
The researchers have developed a new type of recommendation system that tries to achieve two important goals at the same time. The first goal is to provide recommendations that users will immediately enjoy and engage with. The second, more long-term goal is to help users retain and remember the content they interact with.
Imagine you're shopping for clothes online. A traditional recommendation system might suggest items that you'll likely click on and buy right away. But those purchases may not actually lead to you keeping or enjoying the clothes in the long run. The new system the researchers proposed tries to balance short-term enjoyment with long-term value.
To do this, the model uses a technique called multi-task learning. This allows it to optimize for both immediate user feedback and long-term retention at the same time. The researchers tested their model on real-world datasets and found it outperformed existing recommendation methods.
The key insight is that optimizing solely for short-term engagement can lead to recommendations that are fun in the moment but don't have much lasting impact. By also considering long-term retention, the model can identify content that users will not only enjoy right away, but also continue to find valuable over time.
Technical Explanation
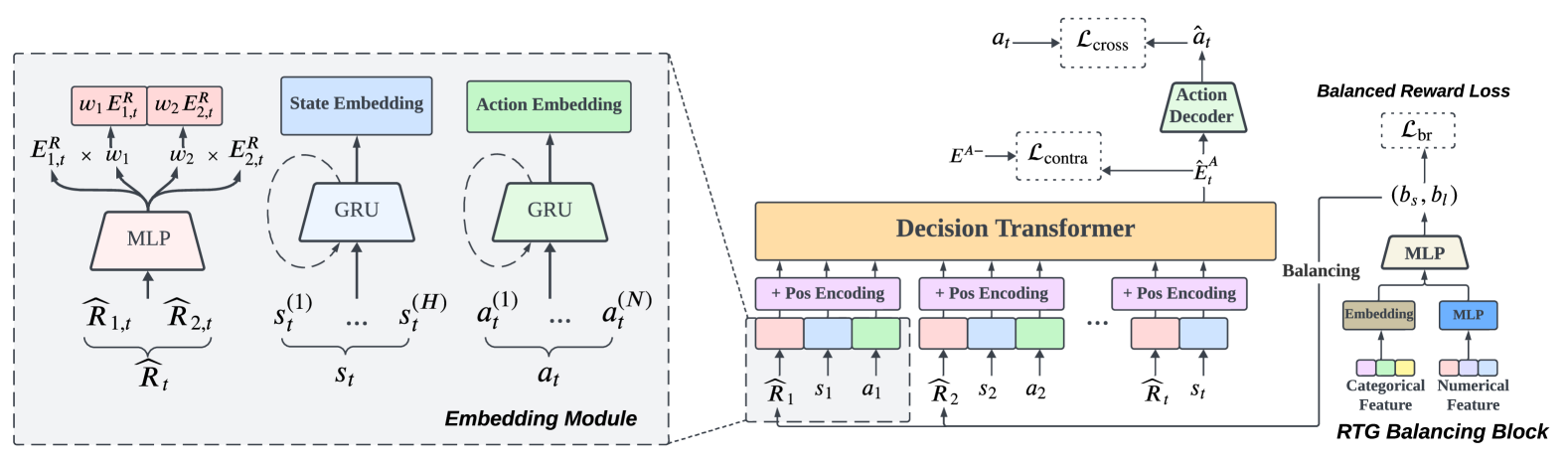
The paper introduces a sequential recommendation model called SeqRec that optimizes for both short-term user feedback and long-term retention. The model uses a multi-task learning approach, where one task predicts the user's immediate response to a recommendation, and the other task predicts the user's long-term engagement with the recommended content.
The architecture of SeqRec consists of a shared encoder that learns representations from the user's interaction history, and two separate decoders - one for predicting short-term feedback and one for predicting long-term retention. The model is trained end-to-end to optimize both objectives simultaneously.
The authors evaluate SeqRec on several real-world datasets, including movie ratings and e-commerce purchase data. They compare the performance of SeqRec to several baseline recommendation models, including classic collaborative filtering approaches and more recent deep learning-based methods. The results show that SeqRec outperforms the baselines on metrics capturing both short-term engagement and long-term retention.
Critical Analysis
The paper presents a compelling approach to sequential recommendation that addresses an important practical consideration - balancing short-term user satisfaction with long-term value. However, the authors acknowledge several limitations and areas for future work.
One key limitation is that the model relies on explicit user feedback (e.g. ratings, purchases) to train the short-term and long-term prediction tasks. In many real-world scenarios, such explicit feedback may be scarce, and the model would need to be adapted to work with more implicit signals of user engagement.
Additionally, the authors note that their evaluation focused on relatively static datasets, whereas in many real-world applications, user preferences and item catalogs are constantly evolving. Further research is needed to understand how well SeqRec would perform in dynamic, continuously updating environments.
Another potential area for improvement is the interpretability of the model's recommendations. While the multi-task learning approach allows the model to balance different objectives, it may be difficult for users to understand the reasoning behind specific recommendations. Incorporating more explainable AI techniques could enhance the model's transparency and user trust.
Overall, the SeqRec model represents an interesting step towards building recommendation systems that consider both immediate and long-term user value. Further research and development in this direction could lead to significant improvements in the user experience of various online services.
Conclusion
The paper introduces a sequential recommendation model called SeqRec that aims to optimize for both short-term user feedback and long-term retention. By using a multi-task learning approach, the model is able to balance these two important objectives simultaneously. Evaluations on real-world datasets show that SeqRec outperforms existing recommendation methods, suggesting that considering long-term value alongside short-term engagement can lead to more impactful and valuable recommendations.
This research highlights the importance of looking beyond immediate user satisfaction when designing recommendation systems. By also optimizing for long-term retention, the SeqRec model can identify content that not only engages users in the moment, but also provides lasting value and learning. As online services continue to evolve, developing recommendation techniques that consider both short-term and long-term user needs will be crucial for delivering truly meaningful and valuable experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Sequential Recommendation for Optimizing Both Immediate Feedback and Long-term Retention
Ziru Liu, Shuchang Liu, Zijian Zhang, Qingpeng Cai, Xiangyu Zhao, Kesen Zhao, Lantao Hu, Peng Jiang, Kun Gai
In the landscape of Recommender System (RS) applications, reinforcement learning (RL) has recently emerged as a powerful tool, primarily due to its proficiency in optimizing long-term rewards. Nevertheless, it suffers from instability in the learning process, stemming from the intricate interactions among bootstrapping, off-policy training, and function approximation. Moreover, in multi-reward recommendation scenarios, designing a proper reward setting that reconciles the inner dynamics of various tasks is quite intricate. In response to these challenges, we introduce DT4IER, an advanced decision transformer-based recommendation model that is engineered to not only elevate the effectiveness of recommendations but also to achieve a harmonious balance between immediate user engagement and long-term retention. The DT4IER applies an innovative multi-reward design that adeptly balances short and long-term rewards with user-specific attributes, which serve to enhance the contextual richness of the reward sequence ensuring a more informed and personalized recommendation process. To enhance its predictive capabilities, DT4IER incorporates a high-dimensional encoder, skillfully designed to identify and leverage the intricate interrelations across diverse tasks. Furthermore, we integrate a contrastive learning approach within the action embedding predictions, a strategy that significantly boosts the model's overall performance. Experiments on three real-world datasets demonstrate the effectiveness of DT4IER against state-of-the-art Sequential Recommender Systems (SRSs) and Multi-Task Learning (MTL) models in terms of both prediction accuracy and effectiveness in specific tasks. The source code is accessible online to facilitate replication
Read more6/11/2024
💬
0
Large Language Models Enhanced Sequential Recommendation for Long-tail User and Item
Qidong Liu, Xian Wu, Xiangyu Zhao, Yejing Wang, Zijian Zhang, Feng Tian, Yefeng Zheng
Sequential recommendation systems (SRS) serve the purpose of predicting users' subsequent preferences based on their past interactions and have been applied across various domains such as e-commerce and social networking platforms. However, practical SRS encounters challenges due to the fact that most users engage with only a limited number of items, while the majority of items are seldom consumed. These challenges, termed as the long-tail user and long-tail item dilemmas, often create obstacles for traditional SRS methods. Mitigating these challenges is crucial as they can significantly impact user satisfaction and business profitability. While some research endeavors have alleviated these issues, they still grapple with issues such as seesaw or noise stemming from the scarcity of interactions. The emergence of large language models (LLMs) presents a promising avenue to address these challenges from a semantic standpoint. In this study, we introduce the Large Language Models Enhancement framework for Sequential Recommendation (LLM-ESR), which leverages semantic embeddings from LLMs to enhance SRS performance without increasing computational overhead. To combat the long-tail item challenge, we propose a dual-view modeling approach that fuses semantic information from LLMs with collaborative signals from traditional SRS. To address the long-tail user challenge, we introduce a retrieval augmented self-distillation technique to refine user preference representations by incorporating richer interaction data from similar users. Through comprehensive experiments conducted on three authentic datasets using three widely used SRS models, our proposed enhancement framework demonstrates superior performance compared to existing methodologies.
Read more6/3/2024

0
Enhancing Sequential Recommendations through Multi-Perspective Reflections and Iteration
Weicong Qin, Yi Xu, Weijie Yu, Chenglei Shen, Xiao Zhang, Ming He, Jianping Fan, Jun Xu
Sequence recommendation (SeqRec) aims to predict the next item a user will interact with by understanding user intentions and leveraging collaborative filtering information. Large language models (LLMs) have shown great promise in recommendation tasks through prompt-based, fixed reflection libraries, and fine-tuning techniques. However, these methods face challenges, including lack of supervision, inability to optimize reflection sources, inflexibility to diverse user needs, and high computational costs. Despite promising results, current studies primarily focus on reflections of users' explicit preferences (e.g., item titles) while neglecting implicit preferences (e.g., brands) and collaborative filtering information. This oversight hinders the capture of preference shifts and dynamic user behaviors. Additionally, existing approaches lack mechanisms for reflection evaluation and iteration, often leading to suboptimal recommendations. To address these issues, we propose the Mixture of REflectors (MoRE) framework, designed to model and learn dynamic user preferences in SeqRec. Specifically, MoRE introduces three reflectors for generating LLM-based reflections on explicit preferences, implicit preferences, and collaborative signals. Each reflector incorporates a self-improving strategy, termed refining-and-iteration, to evaluate and iteratively update reflections. Furthermore, a meta-reflector employs a contextual bandit algorithm to select the most suitable expert and corresponding reflections for each user's recommendation, effectively capturing dynamic preferences. Extensive experiments on three real-world datasets demonstrate that MoRE consistently outperforms state-of-the-art methods, requiring less training time and GPU memory compared to other LLM-based approaches in SeqRec.
Read more9/11/2024

0
DELRec: Distilling Sequential Pattern to Enhance LLM-based Recommendation
Guohao Sun, Haoyi Zhang
Sequential recommendation (SR) tasks enhance recommendation accuracy by capturing the connection between users' past interactions and their changing preferences. Conventional models often focus solely on capturing sequential patterns within the training data, neglecting the broader context and semantic information embedded in item titles from external sources. This limits their predictive power and adaptability. Recently, large language models (LLMs) have shown promise in SR tasks due to their advanced understanding capabilities and strong generalization abilities. Researchers have attempted to enhance LLMs' recommendation performance by incorporating information from SR models. However, previous approaches have encountered problems such as 1) only influencing LLMs at the result level; 2) increased complexity of LLMs recommendation methods leading to reduced interpretability; 3) incomplete understanding and utilization of SR models information by LLMs. To address these problems, we proposes a novel framework, DELRec, which aims to extract knowledge from SR models and enable LLMs to easily comprehend and utilize this supplementary information for more effective sequential recommendations. DELRec consists of two main stages: 1) SR Models Pattern Distilling, focusing on extracting behavioral patterns exhibited by SR models using soft prompts through two well-designed strategies; 2) LLMs-based Sequential Recommendation, aiming to fine-tune LLMs to effectively use the distilled auxiliary information to perform SR tasks. Extensive experimental results conducted on three real datasets validate the effectiveness of the DELRec framework.
Read more6/19/2024