Shake to Leak: Fine-tuning Diffusion Models Can Amplify the Generative Privacy Risk
2403.09450
0
0

Abstract
While diffusion models have recently demonstrated remarkable progress in generating realistic images, privacy risks also arise: published models or APIs could generate training images and thus leak privacy-sensitive training information. In this paper, we reveal a new risk, Shake-to-Leak (S2L), that fine-tuning the pre-trained models with manipulated data can amplify the existing privacy risks. We demonstrate that S2L could occur in various standard fine-tuning strategies for diffusion models, including concept-injection methods (DreamBooth and Textual Inversion) and parameter-efficient methods (LoRA and Hypernetwork), as well as their combinations. In the worst case, S2L can amplify the state-of-the-art membership inference attack (MIA) on diffusion models by $5.4%$ (absolute difference) AUC and can increase extracted private samples from almost $0$ samples to $15.8$ samples on average per target domain. This discovery underscores that the privacy risk with diffusion models is even more severe than previously recognized. Codes are available at https://github.com/VITA-Group/Shake-to-Leak.
Create account to get full access
Overview
- This paper investigates the potential privacy risks associated with fine-tuning diffusion models, a type of generative AI system.
- The authors demonstrate that fine-tuning these models can amplify the ability to extract sensitive information from the training data, a phenomenon they call "Shake to Leak".
- The paper examines various attack scenarios and provides empirical evidence of this generative privacy risk, as well as potential mitigation strategies.
Plain English Explanation
Diffusion models are a type of machine learning system that can generate new images, text, or other data by learning patterns from existing examples. These models have become increasingly powerful and are used in many applications, from creating digital art to generating synthetic text.
However, the paper raises concerns that fine-tuning diffusion models - the process of further training them on a specific dataset - can actually increase the risk of privacy breaches. The authors call this phenomenon "Shake to Leak", where small changes to the model can cause it to reveal sensitive information from the training data.
The research explores various ways this privacy risk can manifest, such as extracting personal details or generating content that resembles specific individuals. Through experiments, the authors demonstrate that fine-tuning diffusion models can amplify this generative privacy risk, even when the original models were not designed to be privacy-preserving.
The paper also discusses potential mitigation strategies, such as developing diffusion models that are more resilient to this issue or applying privacy-preserving techniques during the fine-tuning process. However, the authors note that further research is needed to fully address this challenge.
The findings highlight the importance of carefully considering the privacy implications of generative AI systems, especially as they become more widely adopted and used for sensitive applications. As these technologies continue to evolve, it will be crucial to develop robust safeguards to protect individual privacy.
Technical Explanation
The paper presents a detailed analysis of the potential privacy risks associated with fine-tuning diffusion models, a type of generative AI system. The authors introduce the concept of "Shake to Leak", where small changes to the model can cause it to reveal sensitive information from the training data.
Through a series of experiments, the researchers demonstrate that fine-tuning diffusion models can amplify this generative privacy risk. They explore various attack scenarios, such as extracting personal details or generating content that resembles specific individuals, and provide empirical evidence of this phenomenon.
The paper also discusses potential mitigation strategies, including developing diffusion models that are more resilient to this issue or applying privacy-preserving techniques during the fine-tuning process. However, the authors acknowledge that further research is needed to fully address this challenge.
The findings contribute to the growing body of research on the privacy implications of generative AI systems, highlighting the importance of carefully considering these risks as the technology continues to evolve. The insights from this paper can inform the development of more robust and privacy-preserving generative models in the future.
Critical Analysis
The paper presents a well-designed and thorough investigation of the privacy risks associated with fine-tuning diffusion models. The authors provide compelling empirical evidence to support their "Shake to Leak" hypothesis and explore a range of attack scenarios that demonstrate the amplification of generative privacy risks.
However, the paper also acknowledges several limitations and areas for further research. For example, the authors note that the specific vulnerabilities may depend on the fine-tuning process, the datasets used, and the architectural choices of the diffusion models. Additionally, the proposed mitigation strategies, while promising, require further development and evaluation to ensure their effectiveness.
It would be valuable for future research to explore the generalizability of these findings to other types of generative AI systems, as well as to investigate the long-term implications of these privacy risks on individuals and society. The paper also does not delve deeply into the ethical considerations surrounding the use of generative models in sensitive applications, which could be an important area for further discussion.
Overall, this paper makes a significant contribution to the ongoing dialogue around the privacy implications of generative AI systems. By highlighting the potential for fine-tuning to amplify these risks, the authors have raised important questions that should be carefully considered by both researchers and developers in the field.
Conclusion
The "Shake to Leak" paper presents a compelling investigation into the potential privacy risks associated with fine-tuning diffusion models, a type of generative AI system. The authors demonstrate that this process can amplify the ability to extract sensitive information from the training data, posing a significant challenge for the responsible development and deployment of these technologies.
The findings from this research highlight the importance of considering privacy implications in the design and use of generative AI systems, particularly as they become more widely adopted. While the authors propose potential mitigation strategies, further research is needed to fully address this challenge and ensure that the benefits of these powerful technologies are balanced with robust safeguards for individual privacy.
As the field of generative AI continues to evolve, this paper serves as a valuable contribution to the ongoing discussion around the responsible development and deployment of these systems. By raising awareness of these critical privacy risks, the authors have laid the groundwork for future work that can help unlock the full potential of generative AI while prioritizing the protection of sensitive information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
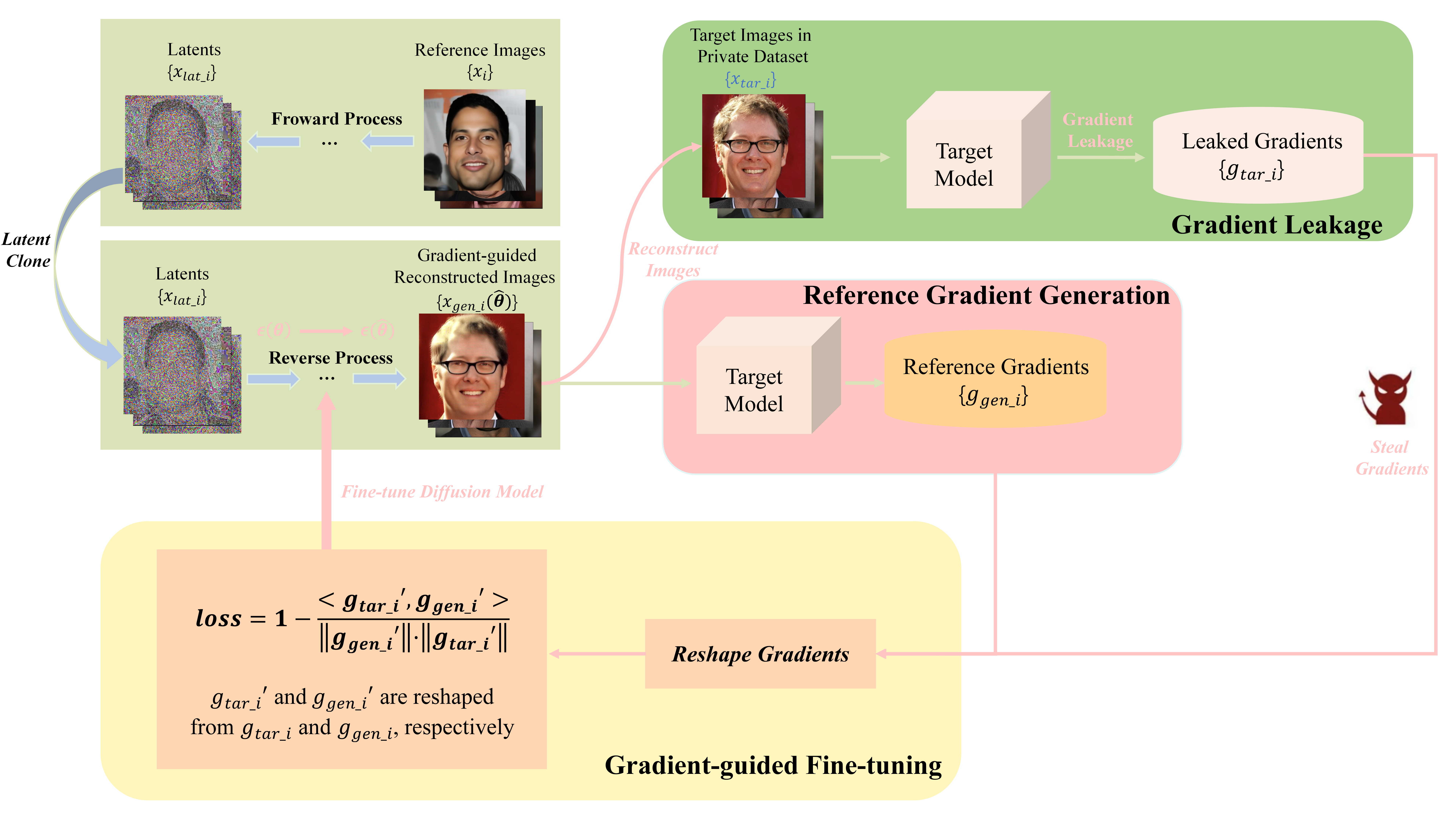
Is Diffusion Model Safe? Severe Data Leakage via Gradient-Guided Diffusion Model
Jiayang Meng, Tao Huang, Hong Chen, Cuiping Li
0
0
Gradient leakage has been identified as a potential source of privacy breaches in modern image processing systems, where the adversary can completely reconstruct the training images from leaked gradients. However, existing methods are restricted to reconstructing low-resolution images where data leakage risks of image processing systems are not sufficiently explored. In this paper, by exploiting diffusion models, we propose an innovative gradient-guided fine-tuning method and introduce a new reconstruction attack that is capable of stealing private, high-resolution images from image processing systems through leaked gradients where severe data leakage encounters. Our attack method is easy to implement and requires little prior knowledge. The experimental results indicate that current reconstruction attacks can steal images only up to a resolution of $128 times 128$ pixels, while our attack method can successfully recover and steal images with resolutions up to $512 times 512$ pixels. Our attack method significantly outperforms the SOTA attack baselines in terms of both pixel-wise accuracy and time efficiency of image reconstruction. Furthermore, our attack can render differential privacy ineffective to some extent.
6/17/2024
Differentially Private Fine-Tuning of Diffusion Models
Yu-Lin Tsai, Yizhe Li, Zekai Chen, Po-Yu Chen, Chia-Mu Yu, Xuebin Ren, Francois Buet-Golfouse
0
0
The integration of Differential Privacy (DP) with diffusion models (DMs) presents a promising yet challenging frontier, particularly due to the substantial memorization capabilities of DMs that pose significant privacy risks. Differential privacy offers a rigorous framework for safeguarding individual data points during model training, with Differential Privacy Stochastic Gradient Descent (DP-SGD) being a prominent implementation. Diffusion method decomposes image generation into iterative steps, theoretically aligning well with DP's incremental noise addition. Despite the natural fit, the unique architecture of DMs necessitates tailored approaches to effectively balance privacy-utility trade-off. Recent developments in this field have highlighted the potential for generating high-quality synthetic data by pre-training on public data (i.e., ImageNet) and fine-tuning on private data, however, there is a pronounced gap in research on optimizing the trade-offs involved in DP settings, particularly concerning parameter efficiency and model scalability. Our work addresses this by proposing a parameter-efficient fine-tuning strategy optimized for private diffusion models, which minimizes the number of trainable parameters to enhance the privacy-utility trade-off. We empirically demonstrate that our method achieves state-of-the-art performance in DP synthesis, significantly surpassing previous benchmarks on widely studied datasets (e.g., with only 0.47M trainable parameters, achieving a more than 35% improvement over the previous state-of-the-art with a small privacy budget on the CelebA-64 dataset). Anonymous codes available at https://anonymous.4open.science/r/DP-LORA-F02F.
6/4/2024

Investigating and Defending Shortcut Learning in Personalized Diffusion Models
Yixin Liu, Ruoxi Chen, Lichao Sun
0
0
Personalized diffusion models have gained popularity for adapting pre-trained text-to-image models to generate images of specific topics with only a few images. However, recent studies find that these models are vulnerable to minor adversarial perturbation, and the fine-tuning performance is largely degraded on corrupted datasets. Such characteristics are further exploited to craft protective perturbation on sensitive images like portraits that prevent unauthorized generation. In response, diffusion-based purification methods have been proposed to remove these perturbations and retain generation performance. However, existing works lack detailed analysis of the fundamental shortcut learning vulnerability of personalized diffusion models and also turn to over-purifying the images cause information loss. In this paper, we take a closer look at the fine-tuning process of personalized diffusion models through the lens of shortcut learning and propose a hypothesis that could explain the underlying manipulation mechanisms of existing perturbation methods. Specifically, we find that the perturbed images are greatly shifted from their original paired prompt in the CLIP-based latent space. As a result, training with this mismatched image-prompt pair creates a construction that causes the models to dump their out-of-distribution noisy patterns to the identifier, thus causing serious performance degradation. Based on this observation, we propose a systematic approach to retain the training performance with purification that realigns the latent image and its semantic meaning and also introduces contrastive learning with a negative token to decouple the learning of wanted clean identity and the unwanted noisy pattern, that shows strong potential capacity against further adaptive perturbation.
6/28/2024

Efficient Differentially Private Fine-Tuning of Diffusion Models
Jing Liu, Andrew Lowy, Toshiaki Koike-Akino, Kieran Parsons, Ye Wang
0
0
The recent developments of Diffusion Models (DMs) enable generation of astonishingly high-quality synthetic samples. Recent work showed that the synthetic samples generated by the diffusion model, which is pre-trained on public data and fully fine-tuned with differential privacy on private data, can train a downstream classifier, while achieving a good privacy-utility tradeoff. However, fully fine-tuning such large diffusion models with DP-SGD can be very resource-demanding in terms of memory usage and computation. In this work, we investigate Parameter-Efficient Fine-Tuning (PEFT) of diffusion models using Low-Dimensional Adaptation (LoDA) with Differential Privacy. We evaluate the proposed method with the MNIST and CIFAR-10 datasets and demonstrate that such efficient fine-tuning can also generate useful synthetic samples for training downstream classifiers, with guaranteed privacy protection of fine-tuning data. Our source code will be made available on GitHub.
6/11/2024