SimGen: Simulator-conditioned Driving Scene Generation
2406.09386
0
0

Abstract
Controllable synthetic data generation can substantially lower the annotation cost of training data in autonomous driving research and development. Prior works use diffusion models to generate driving images conditioned on the 3D object layout. However, those models are trained on small-scale datasets like nuScenes, which lack appearance and layout diversity. Moreover, the trained models can only generate images based on the real-world layout data from the validation set of the same dataset, where overfitting might happen. In this work, we introduce a simulator-conditioned scene generation framework called SimGen that can learn to generate diverse driving scenes by mixing data from the simulator and the real world. It uses a novel cascade diffusion pipeline to address challenging sim-to-real gaps and multi-condition conflicts. A driving video dataset DIVA is collected to enhance the generative diversity of SimGen, which contains over 147.5 hours of real-world driving videos from 73 locations worldwide and simulated driving data from the MetaDrive simulator. SimGen achieves superior generation quality and diversity while preserving controllability based on the text prompt and the layout pulled from a simulator. We further demonstrate the improvements brought by SimGen for synthetic data augmentation on the BEV detection and segmentation task and showcase its capability in safety-critical data generation. Code, data, and models will be made available.
Create account to get full access
Overview
• This paper introduces SimGen, a system that can generate diverse driving scenes by conditioning on simulation data. • The key ideas are to leverage the rich diversity of simulation data to generate realistic and varied driving scenes, and to enable customizing the generated scenes based on specific simulation parameters. • The paper explores techniques for capturing the appearance and layout diversity observed in real-world driving data, and demonstrates the capability to generate customized scenes that match the characteristics of target simulation environments.
Plain English Explanation
The researchers developed a system called SimGen that can create diverse driving scenes by using information from driving simulations. The key advantage of this approach is that simulations can capture a wide variety of driving scenarios, which SimGen then leverages to generate realistic and varied driving scenes.
Rather than generating scenes from scratch, SimGen conditions the generation process on specific parameters from the simulation data. This allows customizing the generated scenes to match the characteristics of a target simulation environment, such as the visual appearance or the layout of the road network.
The paper explores techniques for understanding and replicating the diversity observed in real-world driving data, in terms of both the visual appearance of the scenes and the spatial layout of the road network and other elements. By tapping into the rich simulation data, SimGen can produce a broad range of driving scenes that capture this real-world complexity.
Technical Explanation
The researchers developed SimGen, a system that can generate diverse driving scenes by conditioning the generation process on simulation data. The key idea is to leverage the rich diversity captured in simulation environments to enable the generation of realistic and varied driving scenes.
SimGen first analyzes the appearance and layout diversity present in the DIVA dataset, a large-scale collection of real-world driving data. The paper explores techniques to understand and model the diversity in visual appearance as well as the spatial layout of the driving scenes.
Building on this analysis, the SimGen architecture takes simulation parameters as input and generates driving scenes that match the characteristics of the target simulation environment. This allows customizing the generated scenes to specific simulation use cases, such as visual fidelity or road network layout.
The paper presents experiments demonstrating SimGen's ability to generate diverse driving scenes that capture the complexity of real-world data, while also enabling control over the characteristics of the generated scenes through the simulation input parameters.
Critical Analysis
The SimGen approach offers a promising way to leverage simulation data to generate diverse and customizable driving scenes. By tapping into the rich diversity captured in simulations, the system can produce driving scenes with a level of realism and complexity that is difficult to achieve through purely generative approaches.
However, the paper does not address potential biases or limitations that may be present in the simulation data itself. The diversity observed in the generated scenes is ultimately bounded by the diversity present in the underlying simulation environments. Careful consideration is needed to ensure the simulation data is sufficiently broad and representative of real-world driving scenarios.
Additionally, the paper focuses on visual and spatial aspects of the driving scenes, but does not explore the generation of dynamic elements, such as vehicle behaviors or interactions. Extending SimGen to generate more comprehensive driving scenes, including realistic agent behaviors, could be an area for future research.
Conclusion
The SimGen system presented in this paper demonstrates a novel approach to driving scene generation that leverages the diversity and customizability of simulation data. By conditioning the generation process on simulation parameters, the system can produce realistic and varied driving scenes that match the characteristics of target simulation environments.
This work advances the state of the art in synthetic data generation for autonomous driving applications, providing a pathway to create large and diverse datasets that can supplement real-world data collection. Further research on incorporating more comprehensive scene elements and ensuring the fidelity of the simulation data could help expand the capabilities of systems like SimGen and drive progress in the field of autonomous driving.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
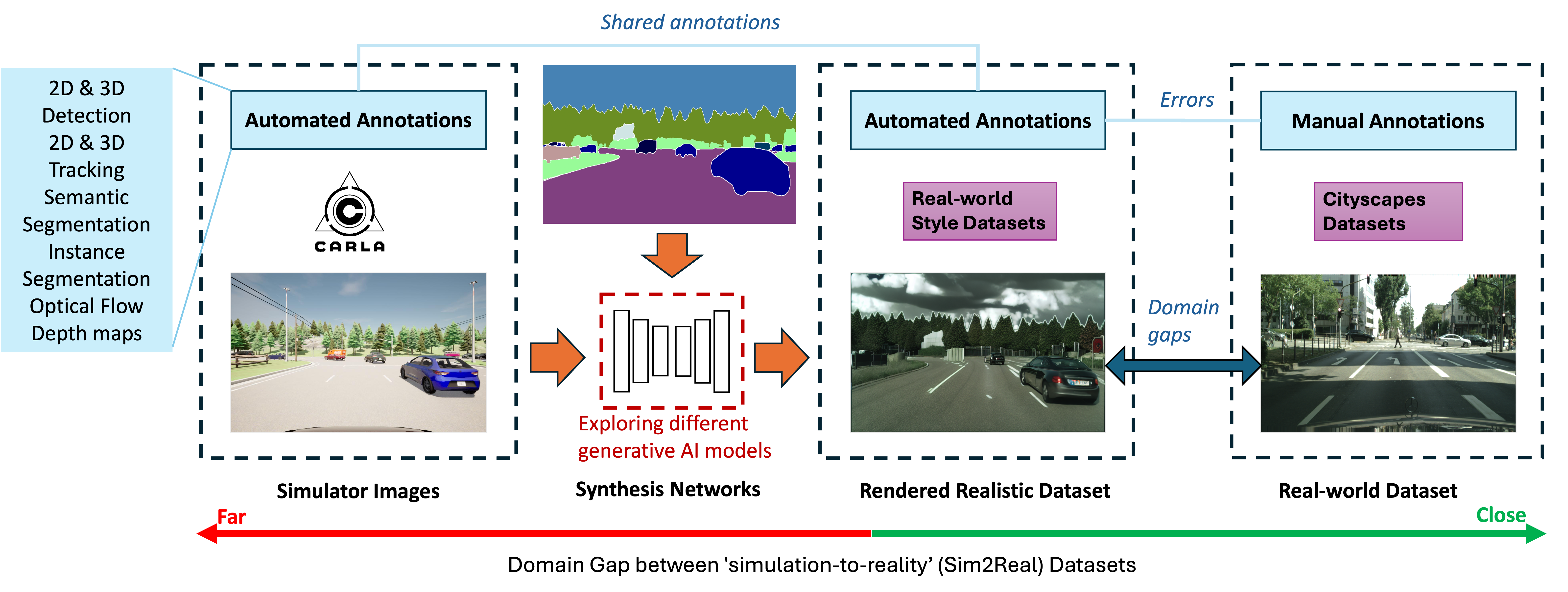
Exploring Generative AI for Sim2Real in Driving Data Synthesis
Haonan Zhao, Yiting Wang, Thomas Bashford-Rogers, Valentina Donzella, Kurt Debattista
0
0
Datasets are essential for training and testing vehicle perception algorithms. However, the collection and annotation of real-world images is time-consuming and expensive. Driving simulators offer a solution by automatically generating various driving scenarios with corresponding annotations, but the simulation-to-reality (Sim2Real) domain gap remains a challenge. While most of the Generative Artificial Intelligence (AI) follows the de facto Generative Adversarial Nets (GANs)-based methods, the recent emerging diffusion probabilistic models have not been fully explored in mitigating Sim2Real challenges for driving data synthesis. To explore the performance, this paper applied three different generative AI methods to leverage semantic label maps from a driving simulator as a bridge for the creation of realistic datasets. A comparative analysis of these methods is presented from the perspective of image quality and perception. New synthetic datasets, which include driving images and auto-generated high-quality annotations, are produced with low costs and high scene variability. The experimental results show that although GAN-based methods are adept at generating high-quality images when provided with manually annotated labels, ControlNet produces synthetic datasets with fewer artefacts and more structural fidelity when using simulator-generated labels. This suggests that the diffusion-based approach may provide improved stability and an alternative method for addressing Sim2Real challenges.
4/16/2024

Versatile Scene-Consistent Traffic Scenario Generation as Optimization with Diffusion
Zhiyu Huang, Zixu Zhang, Ameya Vaidya, Yuxiao Chen, Chen Lv, Jaime Fern'andez Fisac
0
0
Generating realistic and controllable agent behaviors in traffic simulation is crucial for the development of autonomous vehicles. This problem is often formulated as imitation learning (IL) from real-world driving data by either directly predicting future trajectories or inferring cost functions with inverse optimal control. In this paper, we draw a conceptual connection between IL and diffusion-based generative modeling and introduce a novel framework Versatile Behavior Diffusion (VBD) to simulate interactive scenarios with multiple traffic participants. Our model not only generates scene-consistent multi-agent interactions but also enables scenario editing through multi-step guidance and refinement. Experimental evaluations show that VBD achieves state-of-the-art performance on the Waymo Sim Agents benchmark. In addition, we illustrate the versatility of our model by adapting it to various applications. VBD is capable of producing scenarios conditioning on priors, integrating with model-based optimization, sampling multi-modal scene-consistent scenarios by fusing marginal predictions, and generating safety-critical scenarios when combined with a game-theoretic solver.
4/4/2024
🛸
MagicDrive3D: Controllable 3D Generation for Any-View Rendering in Street Scenes
Ruiyuan Gao, Kai Chen, Zhihao Li, Lanqing Hong, Zhenguo Li, Qiang Xu
0
0
While controllable generative models for images and videos have achieved remarkable success, high-quality models for 3D scenes, particularly in unbounded scenarios like autonomous driving, remain underdeveloped due to high data acquisition costs. In this paper, we introduce MagicDrive3D, a novel pipeline for controllable 3D street scene generation that supports multi-condition control, including BEV maps, 3D objects, and text descriptions. Unlike previous methods that reconstruct before training the generative models, MagicDrive3D first trains a video generation model and then reconstructs from the generated data. This innovative approach enables easily controllable generation and static scene acquisition, resulting in high-quality scene reconstruction. To address the minor errors in generated content, we propose deformable Gaussian splatting with monocular depth initialization and appearance modeling to manage exposure discrepancies across viewpoints. Validated on the nuScenes dataset, MagicDrive3D generates diverse, high-quality 3D driving scenes that support any-view rendering and enhance downstream tasks like BEV segmentation. Our results demonstrate the framework's superior performance, showcasing its transformative potential for autonomous driving simulation and beyond.
5/24/2024
🚀
Editable Scene Simulation for Autonomous Driving via Collaborative LLM-Agents
Yuxi Wei, Zi Wang, Yifan Lu, Chenxin Xu, Changxing Liu, Hao Zhao, Siheng Chen, Yanfeng Wang
0
0
Scene simulation in autonomous driving has gained significant attention because of its huge potential for generating customized data. However, existing editable scene simulation approaches face limitations in terms of user interaction efficiency, multi-camera photo-realistic rendering and external digital assets integration. To address these challenges, this paper introduces ChatSim, the first system that enables editable photo-realistic 3D driving scene simulations via natural language commands with external digital assets. To enable editing with high command flexibility,~ChatSim leverages a large language model (LLM) agent collaboration framework. To generate photo-realistic outcomes, ChatSim employs a novel multi-camera neural radiance field method. Furthermore, to unleash the potential of extensive high-quality digital assets, ChatSim employs a novel multi-camera lighting estimation method to achieve scene-consistent assets' rendering. Our experiments on Waymo Open Dataset demonstrate that ChatSim can handle complex language commands and generate corresponding photo-realistic scene videos.
6/27/2024