Exploring Generative AI for Sim2Real in Driving Data Synthesis
2404.09111
0
0
Abstract
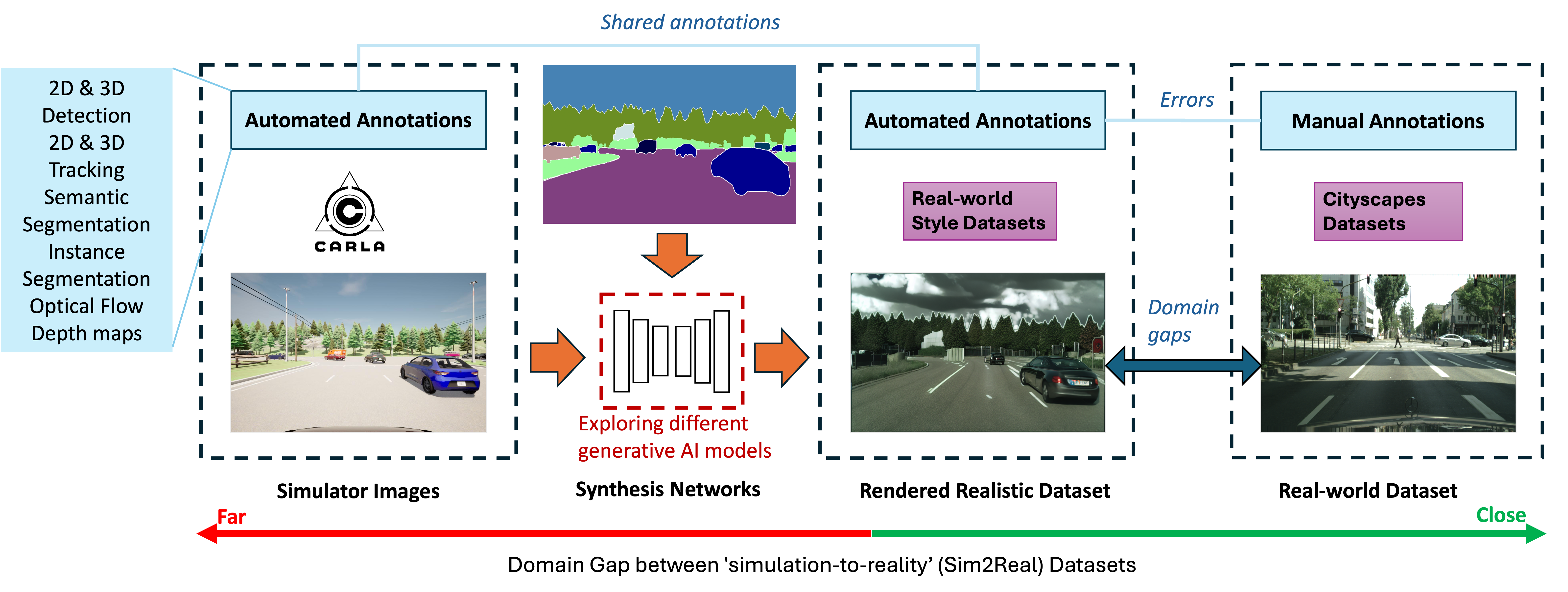
Datasets are essential for training and testing vehicle perception algorithms. However, the collection and annotation of real-world images is time-consuming and expensive. Driving simulators offer a solution by automatically generating various driving scenarios with corresponding annotations, but the simulation-to-reality (Sim2Real) domain gap remains a challenge. While most of the Generative Artificial Intelligence (AI) follows the de facto Generative Adversarial Nets (GANs)-based methods, the recent emerging diffusion probabilistic models have not been fully explored in mitigating Sim2Real challenges for driving data synthesis. To explore the performance, this paper applied three different generative AI methods to leverage semantic label maps from a driving simulator as a bridge for the creation of realistic datasets. A comparative analysis of these methods is presented from the perspective of image quality and perception. New synthetic datasets, which include driving images and auto-generated high-quality annotations, are produced with low costs and high scene variability. The experimental results show that although GAN-based methods are adept at generating high-quality images when provided with manually annotated labels, ControlNet produces synthetic datasets with fewer artefacts and more structural fidelity when using simulator-generated labels. This suggests that the diffusion-based approach may provide improved stability and an alternative method for addressing Sim2Real challenges.
Create account to get full access
Overview
- This research explores the use of generative AI models, specifically diffusion models, for synthesizing driving data to bridge the gap between simulated and real-world environments in autonomous driving applications.
- The study investigates the potential of generating realistic driving scenes and scenarios that can be used to train and evaluate machine learning models for self-driving cars, addressing the challenge of data scarcity in the real world.
- The paper presents a novel approach to leveraging generative AI techniques to create synthetic driving data that can be used to improve deep learning predictions on simulated images and enhance the performance of simulation-based reinforcement learning for real-world autonomous driving.
Plain English Explanation
Developing autonomous driving systems requires a lot of data, both from simulated and real-world environments. However, collecting real-world driving data can be difficult and expensive. The researchers in this study explored using generative AI models, specifically diffusion models, to create synthetic driving scenes and scenarios that can be used to train and test self-driving car algorithms.
Diffusion models are a type of machine learning model that can generate new images by starting with random noise and gradually transforming it into something that looks like the training data. In this case, the researchers trained the diffusion model on a dataset of real-world driving scenes, and then used the model to generate new, realistic-looking driving scenes.
The goal is to use these synthetic driving scenes to bridge the gap between simulated and real-world environments and improve the performance of machine learning models for autonomous driving. By having access to a larger and more diverse dataset of driving scenarios, the researchers hope to enhance the training and evaluation of self-driving car algorithms, ultimately leading to safer and more reliable autonomous vehicles.
Technical Explanation
The researchers in this study used a diffusion model, a type of generative AI model, to synthesize realistic driving scenes and scenarios. Diffusion models work by starting with random noise and gradually transforming it into something that resembles the training data, in this case, real-world driving scenes.
The researchers trained the diffusion model on a dataset of real-world driving scenes, which allowed the model to learn the patterns and characteristics of these scenes. They then used the trained model to generate new, synthetic driving scenes that closely mimic the real-world data.
The researchers evaluated the quality and realism of the generated driving scenes using both objective and subjective metrics. They found that the synthetic data was able to capture the essential features of real-world driving scenes, such as road layouts, vehicle positioning, and environmental conditions.
By leveraging this synthetic driving data, the researchers explored how it could be used to improve the performance of machine learning models for autonomous driving applications. They demonstrated that the synthetic data could be used to enhance the training and evaluation of simulation-based reinforcement learning algorithms for real-world autonomous driving, as well as improve deep learning predictions on simulated images.
Critical Analysis
The research presented in this paper is a promising approach to addressing the data scarcity challenge in autonomous driving. By leveraging generative AI techniques to synthesize realistic driving scenes, the researchers have demonstrated a novel way to bridge the gap between simulated and real-world environments.
However, it is important to note that the quality and realism of the synthetic data are crucial for its successful application in training and evaluating autonomous driving algorithms. While the researchers have shown promising results, there may be inherent limitations in the diffusion model's ability to capture all the nuances and complexities of real-world driving scenarios.
Additionally, the researchers did not explore the potential biases or systematic errors that may be introduced into the synthetic data, which could impact the performance and reliability of the machine learning models trained on it. Further research is needed to investigate these potential issues and ensure that the synthetic data is truly representative of the real-world.
Another area for further exploration is the integration of the synthetic data with real-world data, and how to effectively leverage both sources to enhance the training and evaluation of autonomous driving algorithms. Combining synthetic and real data could lead to more robust and reliable models, but the researchers did not address this aspect in the current paper.
Conclusion
This research represents an important step forward in the use of generative AI techniques for driving data synthesis. By demonstrating the potential of diffusion models to create realistic synthetic driving scenes, the researchers have opened up new avenues for addressing the data scarcity challenge in autonomous driving.
The synthetic data generated by this approach could be used to enhance the training and evaluation of machine learning models for self-driving cars, leading to improved performance and safety. Moreover, this technology could be applied to other domains where data scarcity is a significant challenge, further expanding the impact of generative AI in real-world applications.
As the field of autonomous driving continues to evolve, the ability to generate high-quality synthetic data will become increasingly crucial. The research presented in this paper lays the groundwork for leveraging the power of generative AI to bridge the gap between simulated and real-world environments, paving the way for more robust and reliable autonomous driving systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SimGen: Simulator-conditioned Driving Scene Generation
Yunsong Zhou, Michael Simon, Zhenghao Peng, Sicheng Mo, Hongzi Zhu, Minyi Guo, Bolei Zhou
0
0
Controllable synthetic data generation can substantially lower the annotation cost of training data in autonomous driving research and development. Prior works use diffusion models to generate driving images conditioned on the 3D object layout. However, those models are trained on small-scale datasets like nuScenes, which lack appearance and layout diversity. Moreover, the trained models can only generate images based on the real-world layout data from the validation set of the same dataset, where overfitting might happen. In this work, we introduce a simulator-conditioned scene generation framework called SimGen that can learn to generate diverse driving scenes by mixing data from the simulator and the real world. It uses a novel cascade diffusion pipeline to address challenging sim-to-real gaps and multi-condition conflicts. A driving video dataset DIVA is collected to enhance the generative diversity of SimGen, which contains over 147.5 hours of real-world driving videos from 73 locations worldwide and simulated driving data from the MetaDrive simulator. SimGen achieves superior generation quality and diversity while preserving controllability based on the text prompt and the layout pulled from a simulator. We further demonstrate the improvements brought by SimGen for synthetic data augmentation on the BEV detection and segmentation task and showcase its capability in safety-critical data generation. Code, data, and models will be made available.
6/14/2024
📊
Synthetic Data Generation for Bridging Sim2Real Gap in a Production Environment
Parth Rawal, Mrunal Sompura, Wolfgang Hintze
0
0
Synthetic data is being used lately for training deep neural networks in computer vision applications such as object detection, object segmentation and 6D object pose estimation. Domain randomization hereby plays an important role in reducing the simulation to reality gap. However, this generalization might not be effective in specialized domains like a production environment involving complex assemblies. Either the individual parts, trained with synthetic images, are integrated in much larger assemblies making them indistinguishable from their counterparts and result in false positives or are partially occluded just enough to give rise to false negatives. Domain knowledge is vital in these cases and if conceived effectively while generating synthetic data, can show a considerable improvement in bridging the simulation to reality gap. This paper focuses on synthetic data generation procedures for parts and assemblies used in a production environment. The basic procedures for synthetic data generation and their various combinations are evaluated and compared on images captured in a production environment, where results show up to 15% improvement using combinations of basic procedures. Reducing the simulation to reality gap in this way can aid to utilize the true potential of robot assisted production using artificial intelligence.
5/13/2024
🏅
Simulation-based reinforcement learning for real-world autonomous driving
B{l}a.zej Osi'nski, Adam Jakubowski, Piotr Mi{l}o's, Pawe{l} Zik{e}cina, Christopher Galias, Silviu Homoceanu, Henryk Michalewski
0
0
We use reinforcement learning in simulation to obtain a driving system controlling a full-size real-world vehicle. The driving policy takes RGB images from a single camera and their semantic segmentation as input. We use mostly synthetic data, with labelled real-world data appearing only in the training of the segmentation network. Using reinforcement learning in simulation and synthetic data is motivated by lowering costs and engineering effort. In real-world experiments we confirm that we achieved successful sim-to-real policy transfer. Based on the extensive evaluation, we analyze how design decisions about perception, control, and training impact the real-world performance.
4/4/2024
Towards Reducing Data Acquisition and Labeling for Defect Detection using Simulated Data
Lukas Malte Kemeter, Rasmus Hvingelby, Paulina Sierak, Tobias Schon, Bishwajit Gosswam
0
0
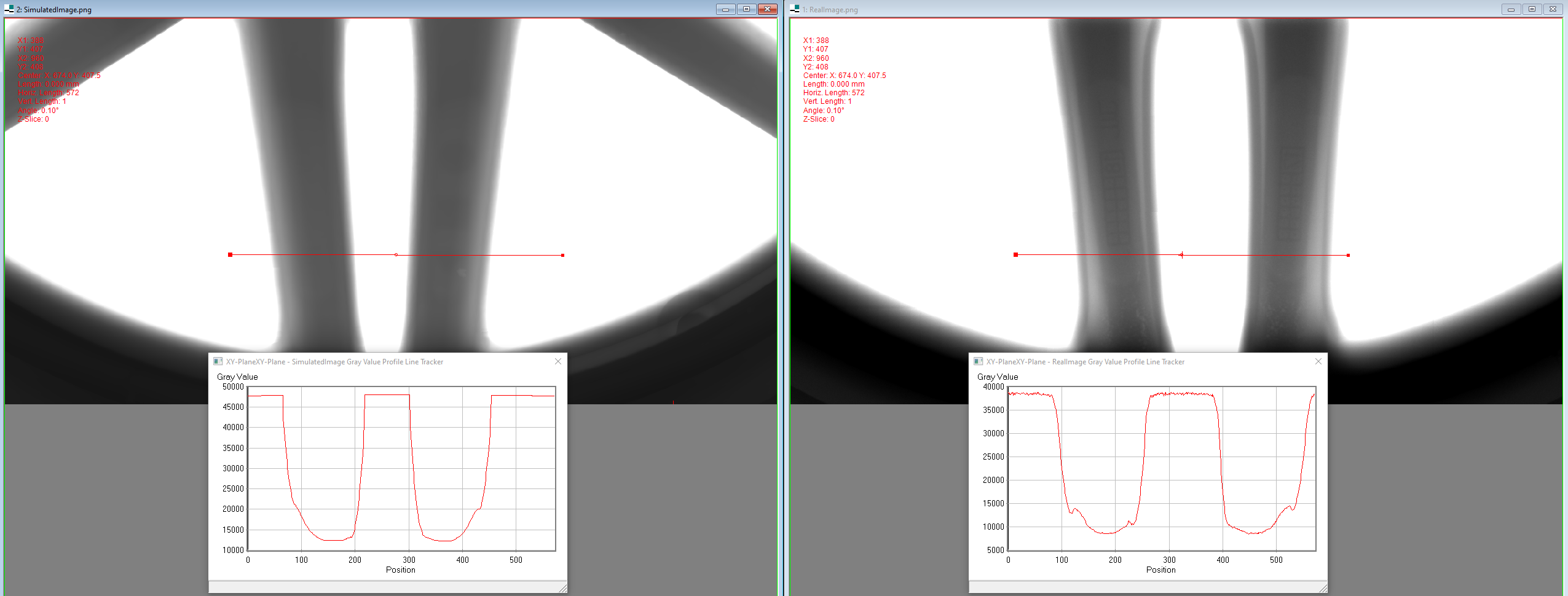
In many manufacturing settings, annotating data for machine learning and computer vision is costly, but synthetic data can be generated at significantly lower cost. Substituting the real-world data with synthetic data is therefore appealing for many machine learning applications that require large amounts of training data. However, relying solely on synthetic data is frequently inadequate for effectively training models that perform well on real-world data, primarily due to domain shifts between the synthetic and real-world data. We discuss approaches for dealing with such a domain shift when detecting defects in X-ray scans of aluminium wheels. Using both simulated and real-world X-ray images, we train an object detection model with different strategies to identify the training approach that generates the best detection results while minimising the demand for annotated real-world training samples. Our preliminary findings suggest that the sim-2-real domain adaptation approach is more cost-efficient than a fully supervised oracle - if the total number of available annotated samples is fixed. Given a certain number of labeled real-world samples, training on a mix of synthetic and unlabeled real-world data achieved comparable or even better detection results at significantly lower cost. We argue that future research into the cost-efficiency of different training strategies is important for a better understanding of how to allocate budget in applied machine learning projects.
6/28/2024