A Simple Recipe for Language-guided Domain Generalized Segmentation
2311.17922
0
0
🐍
Abstract
Generalization to new domains not seen during training is one of the long-standing challenges in deploying neural networks in real-world applications. Existing generalization techniques either necessitate external images for augmentation, and/or aim at learning invariant representations by imposing various alignment constraints. Large-scale pretraining has recently shown promising generalization capabilities, along with the potential of binding different modalities. For instance, the advent of vision-language models like CLIP has opened the doorway for vision models to exploit the textual modality. In this paper, we introduce a simple framework for generalizing semantic segmentation networks by employing language as the source of randomization. Our recipe comprises three key ingredients: (i) the preservation of the intrinsic CLIP robustness through minimal fine-tuning, (ii) language-driven local style augmentation, and (iii) randomization by locally mixing the source and augmented styles during training. Extensive experiments report state-of-the-art results on various generalization benchmarks. Code is accessible at https://github.com/astra-vision/FAMix .
Create account to get full access
Overview
- Generalization to new domains is a longstanding challenge in deploying neural networks in real-world applications.
- Existing techniques rely on external images for augmentation or aim to learn invariant representations through alignment constraints.
- Large-scale pretraining, like the vision-language model CLIP, has shown promise for enabling vision models to exploit textual modality.
- This paper introduces a simple framework for generalizing semantic segmentation networks using language as the source of randomization.
Plain English Explanation
Neural networks, a type of machine learning model, are very powerful at recognizing patterns in data. However, one of the persistent issues with using neural networks in real-world applications is their ability to generalize, or apply what they've learned, to new situations that are different from their original training data.
The researchers in this paper tackled this challenge by developing a new approach that uses language as a way to help the neural network learn to be more adaptable. Traditionally, techniques for improving generalization have relied on adding more training images or trying to force the network to learn features that are consistent across different visual styles.
Instead, this new method takes advantage of the fact that language models, like the CLIP system, have become quite good at extracting meaningful information from text. By incorporating language-driven "style augmentation" during training, the researchers were able to create a neural network for semantic segmentation (the task of identifying and outlining different objects in an image) that could perform well on a variety of new visual domains, without needing to retrain on those specific domains.
The key innovations are: 1) preserving the inherent robustness of the CLIP model through minimal fine-tuning, 2) using language to generate new visual styles to augment the training data, and 3) randomly mixing the original and augmented styles during training to improve generalization.
Technical Explanation
The core of this paper's approach is using language as a source of randomization to improve the generalization capabilities of semantic segmentation networks. The authors leveraged the powerful vision-language model CLIP, which has shown strong cross-modal transfer abilities.
Their framework consists of three main components:
-
Preserve CLIP Robustness: The researchers start by fine-tuning a pre-trained CLIP model on the semantic segmentation task, but with minimal updates to the model parameters. This preserves the inherent robustness and cross-modal understanding that CLIP has acquired during its large-scale pretraining.
-
Language-Driven Style Augmentation: To generate diverse visual styles, the authors use text prompts to guide a style transfer model. This allows them to create a wide range of augmented training samples with different visual appearances, all grounded in natural language.
-
Style Mixing during Training: During the training process, the researchers randomly mix the original training images with the language-driven augmented images. This style mixing forces the network to learn representations that are robust to variations in visual appearance, further improving its ability to generalize.
The researchers evaluated their approach on several benchmarks for domain generalization in semantic segmentation, including PACS, DomainNet, and Office-Home. Their method achieved state-of-the-art performance, demonstrating the effectiveness of using language as a source of randomization for boosting neural network generalization.
Critical Analysis
The paper presents a compelling and straightforward approach to improving the generalization capabilities of semantic segmentation models. By leveraging the cross-modal understanding of CLIP and using language-driven style augmentation, the researchers were able to train models that perform well on a diverse range of visual domains without the need for extensive retraining.
However, the paper does not delve into the limitations or potential drawbacks of this approach. For example, the performance gains may be dependent on the quality and diversity of the language prompts used for style augmentation. Additionally, the computational and memory requirements of the style transfer model and the style mixing process during training are not discussed.
Further research could explore the generalization performance on even more diverse and challenging real-world datasets, as well as investigate the robustness of the approach to different types of distribution shifts. It would also be valuable to understand the transferability of the learned representations to other computer vision tasks beyond semantic segmentation.
Conclusion
This paper presents a novel and effective approach for improving the generalization capabilities of semantic segmentation models. By leveraging language as a source of randomization, the researchers were able to train neural networks that can perform well on a variety of visual domains, without the need for extensive retraining or large amounts of additional training data.
The key innovations, including preserving the robustness of CLIP, using language-driven style augmentation, and randomly mixing styles during training, demonstrate the power of cross-modal learning and the potential of language to enhance the generalization of computer vision models. These findings have important implications for deploying neural networks in real-world applications, where the ability to adapt to diverse and unseen scenarios is crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
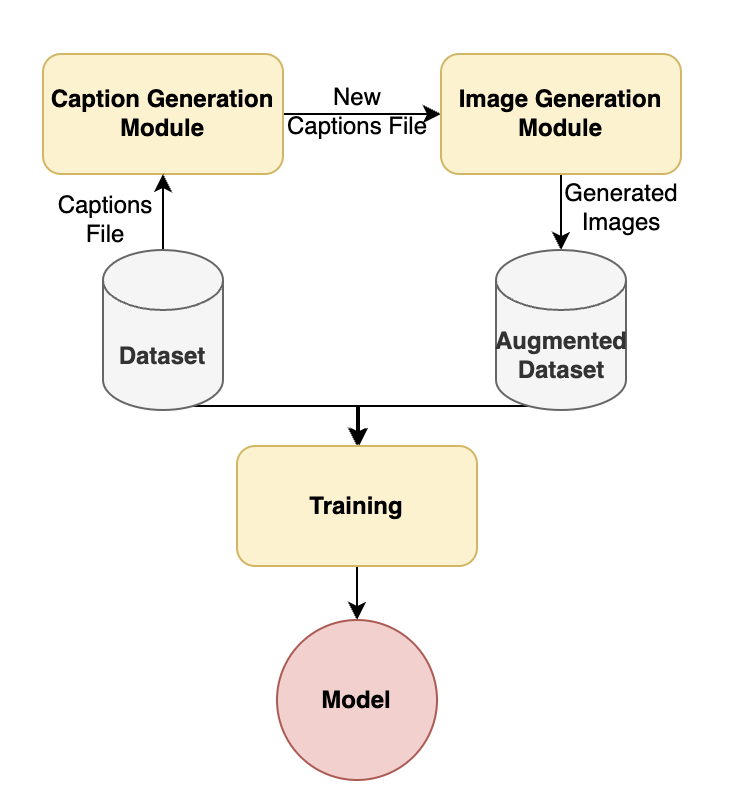
Semantic Augmentation in Images using Language
Sahiti Yerramilli, Jayant Sravan Tamarapalli, Tanmay Girish Kulkarni, Jonathan Francis, Eric Nyberg
0
0
Deep Learning models are incredibly data-hungry and require very large labeled datasets for supervised learning. As a consequence, these models often suffer from overfitting, limiting their ability to generalize to real-world examples. Recent advancements in diffusion models have enabled the generation of photorealistic images based on textual inputs. Leveraging the substantial datasets used to train these diffusion models, we propose a technique to utilize generated images to augment existing datasets. This paper explores various strategies for effective data augmentation to improve the out-of-domain generalization capabilities of deep learning models.
4/4/2024

Regularized Training with Generated Datasets for Name-Only Transfer of Vision-Language Models
Minho Park, Sunghyun Park, Jooyeol Yun, Jaegul Choo
0
0
Recent advancements in text-to-image generation have inspired researchers to generate datasets tailored for perception models using generative models, which prove particularly valuable in scenarios where real-world data is limited. In this study, our goal is to address the challenges when fine-tuning vision-language models (e.g., CLIP) on generated datasets. Specifically, we aim to fine-tune vision-language models to a specific classification model without access to any real images, also known as name-only transfer. However, despite the high fidelity of generated images, we observed a significant performance degradation when fine-tuning the model using the generated datasets due to the domain gap between real and generated images. To overcome the domain gap, we provide two regularization methods for training and post-training, respectively. First, we leverage the domain-agnostic knowledge from the original pre-trained vision-language model by conducting the weight-space ensemble of the fine-tuned model on the generated dataset with the original pre-trained model at the post-training. Secondly, we reveal that fine-tuned models with high feature diversity score high performance in the real domain, which indicates that increasing feature diversity prevents learning the generated domain-specific knowledge. Thus, we encourage feature diversity by providing additional regularization at training time. Extensive experiments on various classification datasets and various text-to-image generation models demonstrated that our analysis and regularization techniques effectively mitigate the domain gap, which has long been overlooked, and enable us to achieve state-of-the-art performance by training with generated images. Code is available at https://github.com/pmh9960/regft-for-gen
6/11/2024

Diverse and Tailored Image Generation for Zero-shot Multi-label Classification
Kaixin Zhang, Zhixiang Yuan, Tao Huang
0
0
Recently, zero-shot multi-label classification has garnered considerable attention for its capacity to operate predictions on unseen labels without human annotations. Nevertheless, prevailing approaches often use seen classes as imperfect proxies for unseen ones, resulting in suboptimal performance. Drawing inspiration from the success of text-to-image generation models in producing realistic images, we propose an innovative solution: generating synthetic data to construct a training set explicitly tailored for proxyless training on unseen labels. Our approach introduces a novel image generation framework that produces multi-label synthetic images of unseen classes for classifier training. To enhance diversity in the generated images, we leverage a pre-trained large language model to generate diverse prompts. Employing a pre-trained multi-modal CLIP model as a discriminator, we assess whether the generated images accurately represent the target classes. This enables automatic filtering of inaccurately generated images, preserving classifier accuracy. To refine text prompts for more precise and effective multi-label object generation, we introduce a CLIP score-based discriminative loss to fine-tune the text encoder in the diffusion model. Additionally, to enhance visual features on the target task while maintaining the generalization of original features and mitigating catastrophic forgetting resulting from fine-tuning the entire visual encoder, we propose a feature fusion module inspired by transformer attention mechanisms. This module aids in capturing global dependencies between multiple objects more effectively. Extensive experimental results validate the effectiveness of our approach, demonstrating significant improvements over state-of-the-art methods.
4/5/2024
Transitive Vision-Language Prompt Learning for Domain Generalization
Liyuan Wang, Yan Jin, Zhen Chen, Jinlin Wu, Mengke Li, Yang Lu, Hanzi Wang
0
0
The vision-language pre-training has enabled deep models to make a huge step forward in generalizing across unseen domains. The recent learning method based on the vision-language pre-training model is a great tool for domain generalization and can solve this problem to a large extent. However, there are still some issues that an advancement still suffers from trading-off between domain invariance and class separability, which are crucial in current DG problems. However, there are still some issues that an advancement still suffers from trading-off between domain invariance and class separability, which are crucial in current DG problems. In this paper, we introduce a novel prompt learning strategy that leverages deep vision prompts to address domain invariance while utilizing language prompts to ensure class separability, coupled with adaptive weighting mechanisms to balance domain invariance and class separability. Extensive experiments demonstrate that deep vision prompts effectively extract domain-invariant features, significantly improving the generalization ability of deep models and achieving state-of-the-art performance on three datasets.
4/30/2024