Semantic Augmentation in Images using Language
2404.02353
0
0
Abstract
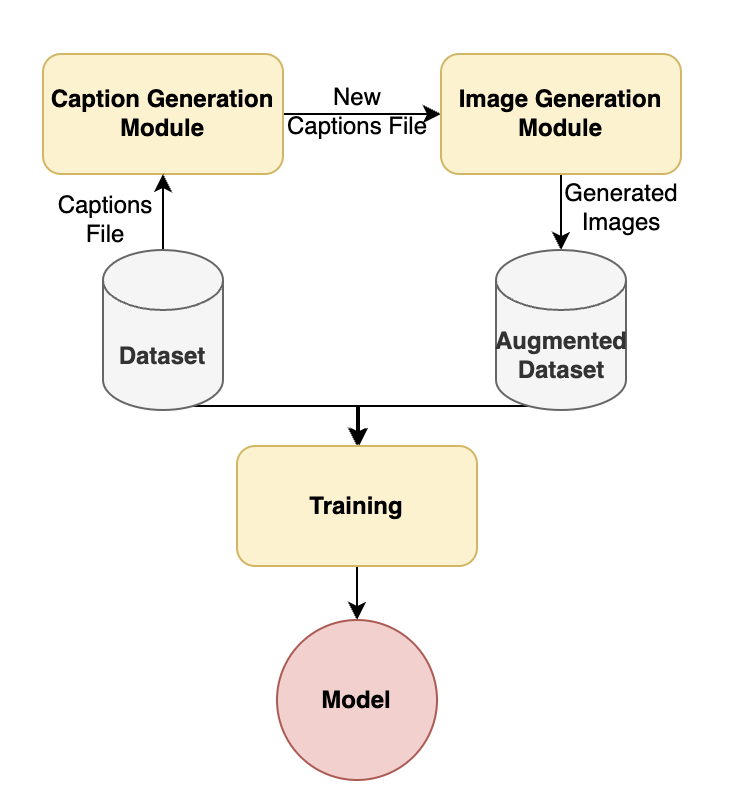
Deep Learning models are incredibly data-hungry and require very large labeled datasets for supervised learning. As a consequence, these models often suffer from overfitting, limiting their ability to generalize to real-world examples. Recent advancements in diffusion models have enabled the generation of photorealistic images based on textual inputs. Leveraging the substantial datasets used to train these diffusion models, we propose a technique to utilize generated images to augment existing datasets. This paper explores various strategies for effective data augmentation to improve the out-of-domain generalization capabilities of deep learning models.
Create account to get full access
Overview
• This paper explores using language to augment the semantic content of images, which could have applications in areas like computer vision and image editing.
• The key idea is to use language models to generate additional information about the contents and meaning of images, going beyond just the visual elements.
• The authors propose several novel techniques for this "semantic augmentation" and evaluate them on standard computer vision benchmarks.
Plain English Explanation
The researchers in this paper are looking at ways to enhance images using language. Typically, when we work with images in areas like computer vision or photo editing, we focus a lot on the visual aspects - the objects, colors, textures, and so on that we can see. But the researchers wanted to go beyond that and also capture more of the meaning and context behind the images.
Their approach is to use powerful language models - AI systems that can understand and generate human language. By connecting these language models to images, they can generate additional text-based information that describes the semantic content and significance of what's shown in the image. For example, an image of a park might not only be labeled with the objects present, but also get captions describing the activities, emotions, or broader meaning.
The key innovations in this paper are the specific techniques they developed to effectively link language and visual data in this way. They evaluated these methods on standard computer vision benchmarks to show their effectiveness. Ultimately, this kind of semantic augmentation could enable richer, more contextual understanding and manipulation of visual data - with applications ranging from improved image captioning to more intelligent photo editing tools.
Technical Explanation
The core of this work is developing novel techniques for what the authors call "semantic augmentation" - using language models to generate semantic information that enhances the content of images beyond just their visual elements.
The first key contribution is a model architecture that fuses visual and language representations. It takes an input image and a language prompt, and outputs a semantically-augmented representation of the image. This is achieved through carefully designed attention mechanisms that allow the language model to selectively attend to and enrich different parts of the visual input.
Additionally, the authors propose techniques for training these models in both supervised and unsupervised ways. In the supervised case, they use image-text paired data to directly optimize the semantic augmentation. In the unsupervised case, they leverage self-supervised language modeling objectives to imbue the system with general language understanding without explicit image-text alignment.
The models are evaluated on standard computer vision benchmarks like COCO and Flickr30k, where the semantically-augmented images show improvements on tasks like image captioning and visual question answering compared to purely visual-based approaches.
Critical Analysis
The paper presents a compelling approach for enhancing images with richer semantic information using language models. The authors demonstrate effective techniques for fusing visual and language representations, and show the benefits of this semantic augmentation on downstream tasks.
That said, the evaluation is limited to standard benchmarks, and the authors acknowledge that more work is needed to understand the full potential and limitations of this approach. For example, it's unclear how well the models would generalize to more open-ended or creative image-language tasks.
Additionally, the paper does not deeply explore potential biases or failure modes that could arise from relying on large language models, which are known to sometimes exhibit undesirable societal biases. Careful consideration of these issues will be important as this technology is developed further.
Overall, this work represents an interesting step towards more semantically-aware computer vision, with promising future applications. But as with any emerging AI technology, continued scrutiny and responsible development will be crucial.
Conclusion
This paper introduces novel techniques for semantically augmenting images using language models. By fusing visual and language representations, the authors demonstrate how images can be enhanced with richer contextual information that goes beyond just their visual elements.
The proposed methods show promising results on standard computer vision benchmarks, pointing to potential applications in areas like image captioning, visual question answering, and even intelligent photo editing tools. As this technology matures, it will be important to carefully consider potential biases and limitations, but the core idea of semantically-aware image understanding represents an exciting direction for the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
A Simple Recipe for Language-guided Domain Generalized Segmentation
Mohammad Fahes, Tuan-Hung Vu, Andrei Bursuc, Patrick P'erez, Raoul de Charette
0
0
Generalization to new domains not seen during training is one of the long-standing challenges in deploying neural networks in real-world applications. Existing generalization techniques either necessitate external images for augmentation, and/or aim at learning invariant representations by imposing various alignment constraints. Large-scale pretraining has recently shown promising generalization capabilities, along with the potential of binding different modalities. For instance, the advent of vision-language models like CLIP has opened the doorway for vision models to exploit the textual modality. In this paper, we introduce a simple framework for generalizing semantic segmentation networks by employing language as the source of randomization. Our recipe comprises three key ingredients: (i) the preservation of the intrinsic CLIP robustness through minimal fine-tuning, (ii) language-driven local style augmentation, and (iii) randomization by locally mixing the source and augmented styles during training. Extensive experiments report state-of-the-art results on various generalization benchmarks. Code is accessible at https://github.com/astra-vision/FAMix .
4/3/2024
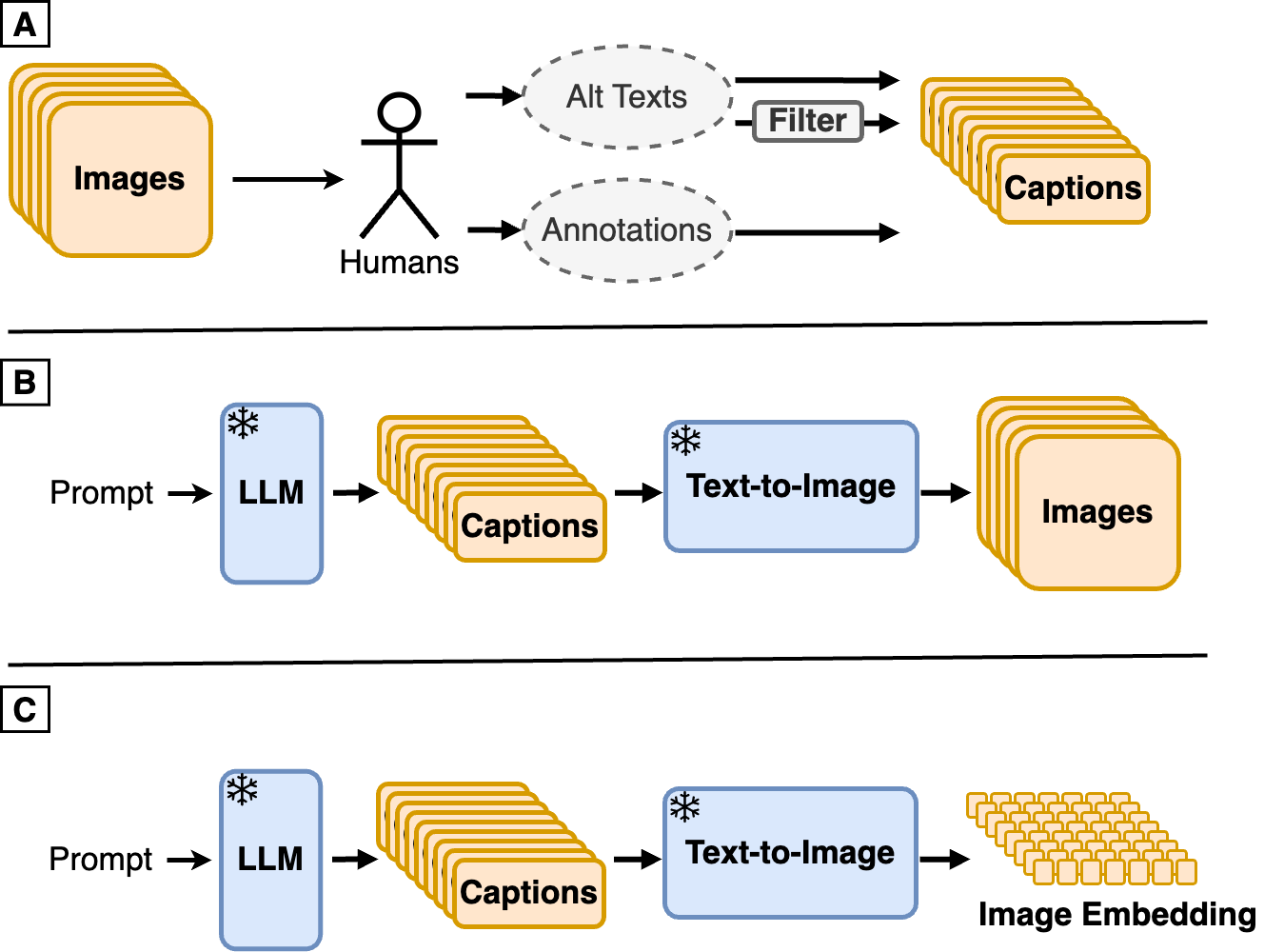
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Sahand Sharifzadeh, Christos Kaplanis, Shreya Pathak, Dharshan Kumaran, Anastasija Ilic, Jovana Mitrovic, Charles Blundell, Andrea Banino
0
0
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). In this work, we investigate an approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs a pretrained text-to-image model to synthesize image embeddings from captions generated by an LLM. Despite the text-to-image model and VLM initially being trained on the same data, our approach leverages the image generator's ability to create novel compositions, resulting in synthetic image embeddings that expand beyond the limitations of the original dataset. Extensive experiments demonstrate that our VLM, finetuned on synthetic data achieves comparable performance to models trained solely on human-annotated data, while requiring significantly less data. Furthermore, we perform a set of analyses on captions which reveals that semantic diversity and balance are key aspects for better downstream performance. Finally, we show that synthesizing images in the image embedding space is 25% faster than in the pixel space. We believe our work not only addresses a significant challenge in VLM training but also opens up promising avenues for the development of self-improving multi-modal models.
6/10/2024
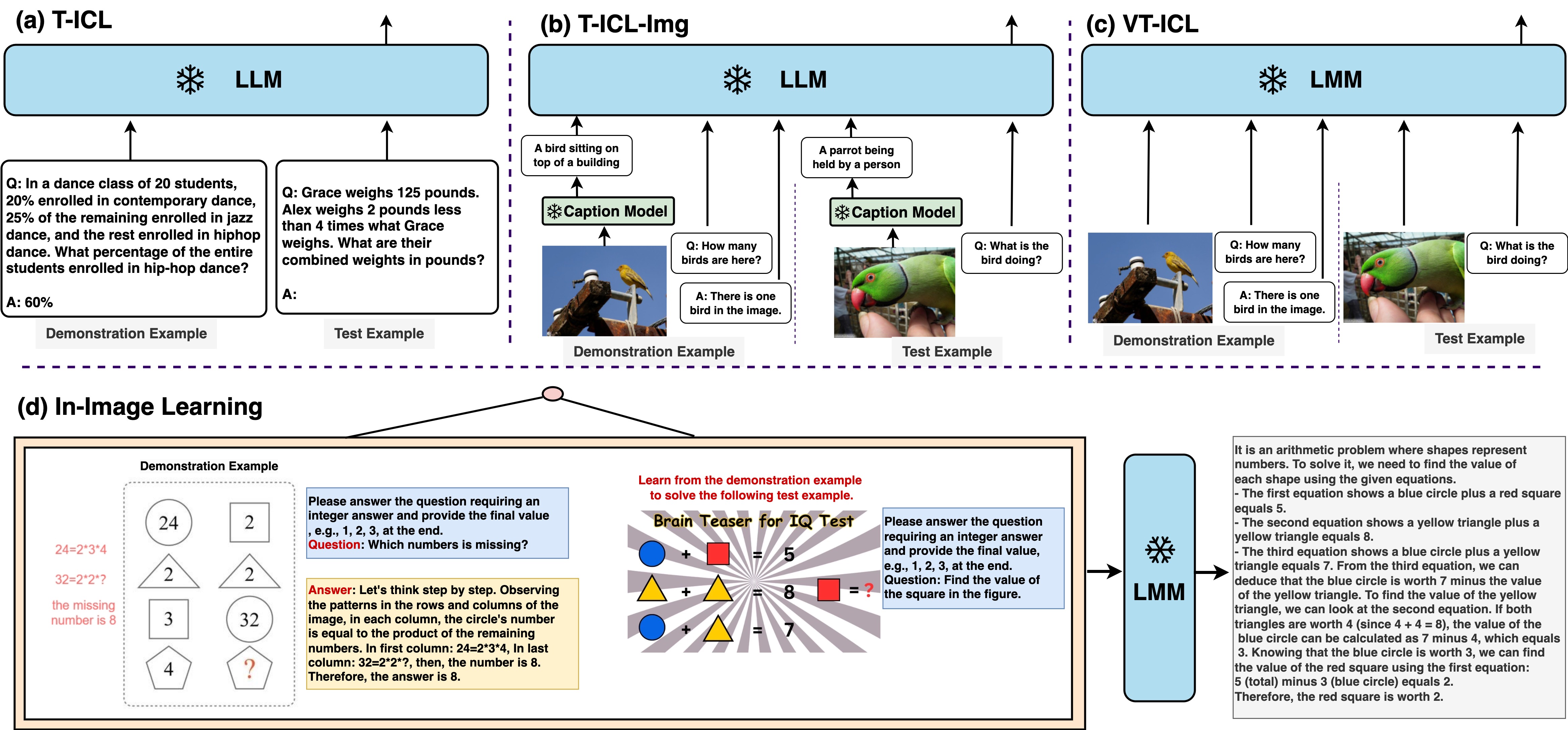
All in an Aggregated Image for In-Image Learning
Lei Wang, Wanyu Xu, Zhiqiang Hu, Yihuai Lan, Shan Dong, Hao Wang, Roy Ka-Wei Lee, Ee-Peng Lim
0
0
This paper introduces a new in-context learning (ICL) mechanism called In-Image Learning (I$^2$L) that combines demonstration examples, visual cues, and chain-of-thought reasoning into an aggregated image to enhance the capabilities of Large Multimodal Models (e.g., GPT-4V) in multimodal reasoning tasks. Unlike previous approaches that rely on converting images to text or incorporating visual input into language models, I$^2$L consolidates all information into an aggregated image and leverages image processing, understanding, and reasoning abilities. This has several advantages: it reduces inaccurate textual descriptions of complex images, provides flexibility in positioning demonstration examples, and avoids multiple input images and lengthy prompts. We also introduce I$^2$L-Hybrid, a method that combines the strengths of I$^2$L with other ICL methods. Specifically, it uses an automatic strategy to select the most suitable method (I$^2$L or another certain ICL method) for a specific task instance. We conduct extensive experiments to assess the effectiveness of I$^2$L and I$^2$L-Hybrid on MathVista, which covers a variety of complex multimodal reasoning tasks. Additionally, we investigate the influence of image resolution, the number of demonstration examples in a single image, and the positions of these demonstrations in the aggregated image on the effectiveness of I$^2$L. Our code is publicly available at https://github.com/AGI-Edgerunners/IIL.
4/3/2024
Harnessing the Power of Large Vision Language Models for Synthetic Image Detection
Mamadou Keita, Wassim Hamidouche, Hassen Bougueffa, Abdenour Hadid, Abdelmalik Taleb-Ahmed
0
0
In recent years, the emergence of models capable of generating images from text has attracted considerable interest, offering the possibility of creating realistic images from text descriptions. Yet these advances have also raised concerns about the potential misuse of these images, including the creation of misleading content such as fake news and propaganda. This study investigates the effectiveness of using advanced vision-language models (VLMs) for synthetic image identification. Specifically, the focus is on tuning state-of-the-art image captioning models for synthetic image detection. By harnessing the robust understanding capabilities of large VLMs, the aim is to distinguish authentic images from synthetic images produced by diffusion-based models. This study contributes to the advancement of synthetic image detection by exploiting the capabilities of visual language models such as BLIP-2 and ViTGPT2. By tailoring image captioning models, we address the challenges associated with the potential misuse of synthetic images in real-world applications. Results described in this paper highlight the promising role of VLMs in the field of synthetic image detection, outperforming conventional image-based detection techniques. Code and models can be found at https://github.com/Mamadou-Keita/VLM-DETECT.
4/4/2024