Simplicity Bias of Two-Layer Networks beyond Linearly Separable Data
2405.17299
0
0
📊
Abstract
Simplicity bias, the propensity of deep models to over-rely on simple features, has been identified as a potential reason for limited out-of-distribution generalization of neural networks (Shah et al., 2020). Despite the important implications, this phenomenon has been theoretically confirmed and characterized only under strong dataset assumptions, such as linear separability (Lyu et al., 2021). In this work, we characterize simplicity bias for general datasets in the context of two-layer neural networks initialized with small weights and trained with gradient flow. Specifically, we prove that in the early training phases, network features cluster around a few directions that do not depend on the size of the hidden layer. Furthermore, for datasets with an XOR-like pattern, we precisely identify the learned features and demonstrate that simplicity bias intensifies during later training stages. These results indicate that features learned in the middle stages of training may be more useful for OOD transfer. We support this hypothesis with experiments on image data.
Create account to get full access
Overview
- Researchers have identified a phenomenon called "simplicity bias" where deep neural networks tend to rely too heavily on simple features, limiting their ability to generalize to new, out-of-distribution data.
- Previous work has only characterized simplicity bias under strong assumptions, such as linear separability of the dataset.
- This paper aims to study simplicity bias in the context of general datasets and two-layer neural networks trained with gradient flow.
Plain English Explanation
The researchers are investigating a problem called "simplicity bias" that can prevent deep learning models from performing well on new, unfamiliar data. Simplicity bias means that these models tend to rely too much on simple, easy-to-learn features rather than more complex, nuanced ones that could help them generalize better.
Previous research has only been able to study simplicity bias when the dataset has a specific property called "linear separability." But in the real world, datasets don't always have this property. So the researchers in this paper wanted to take a closer look at simplicity bias in more general datasets, using a simpler type of neural network model with two layers.
Technical Explanation
The researchers focused on two-layer neural networks initialized with small weights and trained using gradient flow, a mathematical technique for optimizing the network's parameters. They made the following key observations:
-
In the early stages of training, the network's features cluster around a few directions that don't depend on the size of the hidden layer. This indicates a strong simplicity bias even in the initial phases of learning.
-
For datasets with an "XOR-like" pattern (a classic example of a non-linearly separable dataset), the researchers were able to precisely identify the specific features the network learns. They found that simplicity bias becomes more pronounced as training progresses.
-
These results suggest that the features learned in the middle stages of training may be more useful for transferring the model's knowledge to new, out-of-distribution data, compared to features learned earlier or later in training.
The researchers support this hypothesis with experiments on image data, though they don't provide full details on these experiments in the paper.
Critical Analysis
The paper provides a thoughtful theoretical analysis of simplicity bias in the context of two-layer neural networks, which helps expand our understanding of this phenomenon beyond the linear separability assumptions of previous work. However, the analysis is limited to a specific network architecture and training setup.
While the researchers identify interesting patterns in the learned features, it's unclear how well these insights translate to more complex, state-of-the-art neural network models. The experiments on image data are briefly mentioned but not thoroughly explored in the paper.
Additional empirical validation on a wider range of datasets and model architectures would help strengthen the generalizability of the findings. Exploring the connections between simplicity bias, neural collapse, and other biases in deep learning would also be a valuable direction for future research.
Conclusion
This paper takes an important step in characterizing simplicity bias in neural networks beyond the constraints of linear separability. The researchers demonstrate that even simple two-layer models exhibit a tendency to rely on a few dominant features, which becomes more pronounced as training progresses.
These insights suggest that the features learned in the middle stages of training may be more useful for transferring a model's knowledge to new, unfamiliar data. This could have significant implications for improving the out-of-distribution generalization capabilities of deep learning systems, an important goal for making these models more robust and reliable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
ReLU Neural Networks with Linear Layers are Biased Towards Single- and Multi-Index Models
Suzanna Parkinson, Greg Ongie, Rebecca Willett
0
0
Neural networks often operate in the overparameterized regime, in which there are far more parameters than training samples, allowing the training data to be fit perfectly. That is, training the network effectively learns an interpolating function, and properties of the interpolant affect predictions the network will make on new samples. This manuscript explores how properties of such functions learned by neural networks of depth greater than two layers. Our framework considers a family of networks of varying depths that all have the same capacity but different representation costs. The representation cost of a function induced by a neural network architecture is the minimum sum of squared weights needed for the network to represent the function; it reflects the function space bias associated with the architecture. Our results show that adding additional linear layers to the input side of a shallow ReLU network yields a representation cost favoring functions with low mixed variation - that is, it has limited variation in directions orthogonal to a low-dimensional subspace and can be well approximated by a single- or multi-index model. Such functions may be represented by the composition of a function with low two-layer representation cost and a low-rank linear operator. Our experiments confirm this behavior in standard network training regimes. They additionally show that linear layers can improve generalization and the learned network is well-aligned with the true latent low-dimensional linear subspace when data is generated using a multi-index model.
6/27/2024
👨🏫
OccamNets: Mitigating Dataset Bias by Favoring Simpler Hypotheses
Robik Shrestha, Kushal Kafle, Christopher Kanan
0
0
Dataset bias and spurious correlations can significantly impair generalization in deep neural networks. Many prior efforts have addressed this problem using either alternative loss functions or sampling strategies that focus on rare patterns. We propose a new direction: modifying the network architecture to impose inductive biases that make the network robust to dataset bias. Specifically, we propose OccamNets, which are biased to favor simpler solutions by design. OccamNets have two inductive biases. First, they are biased to use as little network depth as needed for an individual example. Second, they are biased toward using fewer image locations for prediction. While OccamNets are biased toward simpler hypotheses, they can learn more complex hypotheses if necessary. In experiments, OccamNets outperform or rival state-of-the-art methods run on architectures that do not incorporate these inductive biases. Furthermore, we demonstrate that when the state-of-the-art debiasing methods are combined with OccamNets results further improve.
4/16/2024
🧠
Learning time-scales in two-layers neural networks
Raphael Berthier, Andrea Montanari, Kangjie Zhou
0
0
Gradient-based learning in multi-layer neural networks displays a number of striking features. In particular, the decrease rate of empirical risk is non-monotone even after averaging over large batches. Long plateaus in which one observes barely any progress alternate with intervals of rapid decrease. These successive phases of learning often take place on very different time scales. Finally, models learnt in an early phase are typically `simpler' or `easier to learn' although in a way that is difficult to formalize. Although theoretical explanations of these phenomena have been put forward, each of them captures at best certain specific regimes. In this paper, we study the gradient flow dynamics of a wide two-layer neural network in high-dimension, when data are distributed according to a single-index model (i.e., the target function depends on a one-dimensional projection of the covariates). Based on a mixture of new rigorous results, non-rigorous mathematical derivations, and numerical simulations, we propose a scenario for the learning dynamics in this setting. In particular, the proposed evolution exhibits separation of timescales and intermittency. These behaviors arise naturally because the population gradient flow can be recast as a singularly perturbed dynamical system.
4/19/2024
Simplicity bias, algorithmic probability, and the random logistic map
Boumediene Hamzi, Kamaludin Dingle
0
0
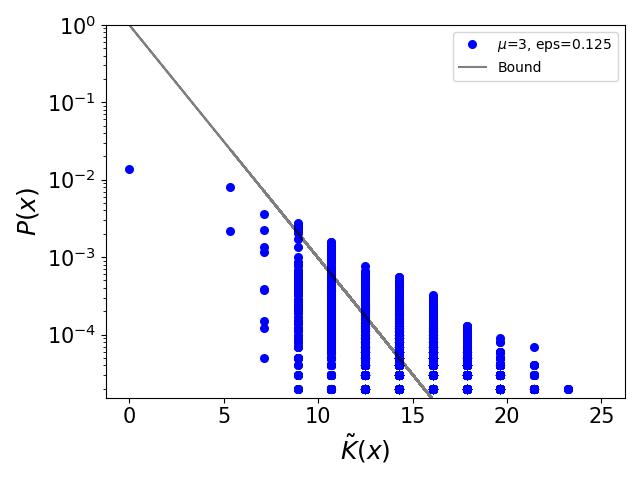
Simplicity bias is an intriguing phenomenon prevalent in various input-output maps, characterized by a preference for simpler, more regular, or symmetric outputs. Notably, these maps typically feature high-probability outputs with simple patterns, whereas complex patterns are exponentially less probable. This bias has been extensively examined and attributed to principles derived from algorithmic information theory and algorithmic probability. In a significant advancement, it has been demonstrated that the renowned logistic map and other one-dimensional maps exhibit simplicity bias when conceptualized as input-output systems. Building upon this work, our research delves into the manifestations of simplicity bias within the random logistic map, specifically focusing on scenarios involving additive noise. We discover that simplicity bias is observable in the random logistic map for specific ranges of $mu$ and noise magnitudes. Additionally, we find that this bias persists even with the introduction of small measurement noise, though it diminishes as noise levels increase. Our studies also revisit the phenomenon of noise-induced chaos, particularly when $mu=3.83$, revealing its characteristics through complexity-probability plots. Intriguingly, we employ the logistic map to illustrate a paradoxical aspect of data analysis: more data adhering to a consistent trend can occasionally lead to emph{reduced} confidence in extrapolation predictions, challenging conventional wisdom. We propose that adopting a probability-complexity perspective in analyzing dynamical systems could significantly enrich statistical learning theories related to series prediction and analysis. This approach not only facilitates a deeper understanding of simplicity bias and its implications but also paves the way for novel methodologies in forecasting complex systems behavior.
4/10/2024