OccamNets: Mitigating Dataset Bias by Favoring Simpler Hypotheses
2204.02426
0
0
👨🏫
Abstract
Dataset bias and spurious correlations can significantly impair generalization in deep neural networks. Many prior efforts have addressed this problem using either alternative loss functions or sampling strategies that focus on rare patterns. We propose a new direction: modifying the network architecture to impose inductive biases that make the network robust to dataset bias. Specifically, we propose OccamNets, which are biased to favor simpler solutions by design. OccamNets have two inductive biases. First, they are biased to use as little network depth as needed for an individual example. Second, they are biased toward using fewer image locations for prediction. While OccamNets are biased toward simpler hypotheses, they can learn more complex hypotheses if necessary. In experiments, OccamNets outperform or rival state-of-the-art methods run on architectures that do not incorporate these inductive biases. Furthermore, we demonstrate that when the state-of-the-art debiasing methods are combined with OccamNets results further improve.
Create account to get full access
Overview
- Dataset bias and spurious correlations can significantly impair the generalization of deep neural networks
- Prior efforts have focused on alternative loss functions or sampling strategies to address this issue
- This paper proposes a new approach: modifying the network architecture to impose inductive biases that make the network robust to dataset bias
Plain English Explanation
OccamNets: Network Architectures with Bias Towards Simpler Solutions for Improved Generalization
Deep learning models can struggle to generalize well when the training data contains biases or spurious correlations. Previous solutions have tried to fix this by changing the loss function or how the training data is sampled. This paper takes a different approach: modifying the network architecture itself to build in biases that make the model more robust to these issues.
The key idea is to create "OccamNets" - networks that are biased towards using simpler, more efficient solutions. Specifically, OccamNets have two main biases:
- They prefer to use the minimum network depth needed for each individual example, rather than a fixed deep architecture.
- They tend to use fewer image locations to make predictions, again favoring simpler solutions.
Despite these biases towards simplicity, OccamNets can still learn complex hypotheses if necessary. Experiments show that OccamNets outperform or match state-of-the-art methods on various benchmarks. The benefits are even greater when OccamNets are combined with other debiasing techniques, further improving generalization.
Technical Explanation
The authors propose a new approach called OccamNets to address dataset bias and spurious correlations in deep neural networks. OccamNets incorporate two key inductive biases:
-
Adaptive Network Depth: OccamNets are biased to use the minimum network depth needed for each individual example, rather than a fixed deep architecture. This encourages the model to find the simplest solution possible.
-
Sparse Activation Maps: OccamNets are biased towards using fewer image locations to make predictions. This also promotes simpler, more robust hypotheses.
Through these architectural biases, OccamNets favor simpler solutions over more complex ones, while still maintaining the flexibility to learn complex hypotheses when necessary. Experiments show that OccamNets outperform or rival state-of-the-art debiasing techniques on various benchmarks. Additionally, combining OccamNets with other bias mitigation methods leads to further improvements in generalization.
Critical Analysis
The paper provides a promising new direction for addressing dataset bias and spurious correlations in deep learning models. The authors' approach of incorporating architectural biases towards simplicity is an interesting alternative to prior work focusing on loss functions or data sampling.
However, the paper does not explore some potential limitations or areas for further research. For example, it's unclear how well OccamNets would scale to more complex datasets or tasks beyond image classification. The authors also don't investigate how the specific inductive biases interact with different types of dataset biases or how to best combine OccamNets with other debiasing techniques.
Additionally, while the experiments demonstrate the effectiveness of OccamNets, further analysis of the learned representations and decision-making processes could provide deeper insights into how the architectural biases influence model behavior and generalization.
Overall, the OccamNet approach is an intriguing contribution that merits further exploration and refinement. Researchers should consider building on this work to develop more robust, unbiased AI systems that can better generalize to real-world scenarios.
Conclusion
This paper introduces a new approach called OccamNets that aims to improve the generalization of deep neural networks by incorporating architectural biases towards simpler solutions. The key ideas are to allow the network depth to adapt to individual examples and to use fewer image locations for making predictions, both of which encourage the model to find more robust, generalizable hypotheses.
Experimental results show that OccamNets outperform or match state-of-the-art debiasing methods, and their benefits are amplified when combined with other bias mitigation techniques. This work provides a promising new direction for building more reliable and unbiased deep learning systems that can better handle dataset biases and spurious correlations. Further research is needed to fully explore the potential of this approach and address any limitations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Towards Exact Computation of Inductive Bias
Akhilan Boopathy, William Yue, Jaedong Hwang, Abhiram Iyer, Ila Fiete
0
0
Much research in machine learning involves finding appropriate inductive biases (e.g. convolutional neural networks, momentum-based optimizers, transformers) to promote generalization on tasks. However, quantification of the amount of inductive bias associated with these architectures and hyperparameters has been limited. We propose a novel method for efficiently computing the inductive bias required for generalization on a task with a fixed training data budget; formally, this corresponds to the amount of information required to specify well-generalizing models within a specific hypothesis space of models. Our approach involves modeling the loss distribution of random hypotheses drawn from a hypothesis space to estimate the required inductive bias for a task relative to these hypotheses. Unlike prior work, our method provides a direct estimate of inductive bias without using bounds and is applicable to diverse hypothesis spaces. Moreover, we derive approximation error bounds for our estimation approach in terms of the number of sampled hypotheses. Consistent with prior results, our empirical results demonstrate that higher dimensional tasks require greater inductive bias. We show that relative to other expressive model classes, neural networks as a model class encode large amounts of inductive bias. Furthermore, our measure quantifies the relative difference in inductive bias between different neural network architectures. Our proposed inductive bias metric provides an information-theoretic interpretation of the benefits of specific model architectures for certain tasks and provides a quantitative guide to developing tasks requiring greater inductive bias, thereby encouraging the development of more powerful inductive biases.
6/26/2024
📊
Simplicity Bias of Two-Layer Networks beyond Linearly Separable Data
Nikita Tsoy, Nikola Konstantinov
0
0
Simplicity bias, the propensity of deep models to over-rely on simple features, has been identified as a potential reason for limited out-of-distribution generalization of neural networks (Shah et al., 2020). Despite the important implications, this phenomenon has been theoretically confirmed and characterized only under strong dataset assumptions, such as linear separability (Lyu et al., 2021). In this work, we characterize simplicity bias for general datasets in the context of two-layer neural networks initialized with small weights and trained with gradient flow. Specifically, we prove that in the early training phases, network features cluster around a few directions that do not depend on the size of the hidden layer. Furthermore, for datasets with an XOR-like pattern, we precisely identify the learned features and demonstrate that simplicity bias intensifies during later training stages. These results indicate that features learned in the middle stages of training may be more useful for OOD transfer. We support this hypothesis with experiments on image data.
5/28/2024

DeNetDM: Debiasing by Network Depth Modulation
Silpa Vadakkeeveetil Sreelatha, Adarsh Kappiyath, Anjan Dutta
0
0
When neural networks are trained on biased datasets, they tend to inadvertently learn spurious correlations, leading to challenges in achieving strong generalization and robustness. Current approaches to address such biases typically involve utilizing bias annotations, reweighting based on pseudo-bias labels, or enhancing diversity within bias-conflicting data points through augmentation techniques. We introduce DeNetDM, a novel debiasing method based on the observation that shallow neural networks prioritize learning core attributes, while deeper ones emphasize biases when tasked with acquiring distinct information. Using a training paradigm derived from Product of Experts, we create both biased and debiased branches with deep and shallow architectures and then distill knowledge to produce the target debiased model. Extensive experiments and analyses demonstrate that our approach outperforms current debiasing techniques, achieving a notable improvement of around 5% in three datasets, encompassing both synthetic and real-world data. Remarkably, DeNetDM accomplishes this without requiring annotations pertaining to bias labels or bias types, while still delivering performance on par with supervised counterparts. Furthermore, our approach effectively harnesses the diversity of bias-conflicting points within the data, surpassing previous methods and obviating the need for explicit augmentation-based methods to enhance the diversity of such bias-conflicting points. The source code will be available upon acceptance.
4/1/2024
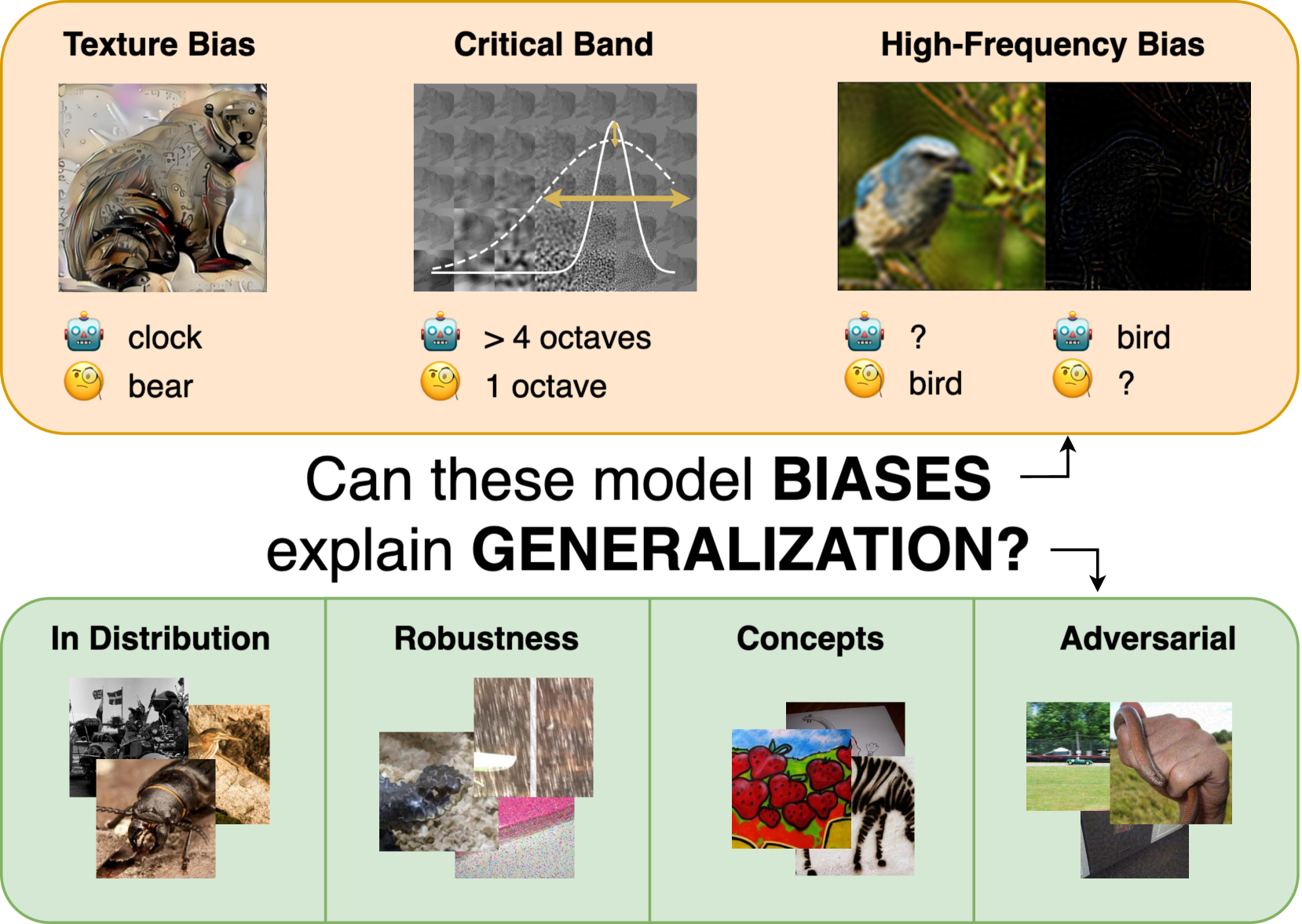
Can Biases in ImageNet Models Explain Generalization?
Paul Gavrikov, Janis Keuper
0
0
The robust generalization of models to rare, in-distribution (ID) samples drawn from the long tail of the training distribution and to out-of-training-distribution (OOD) samples is one of the major challenges of current deep learning methods. For image classification, this manifests in the existence of adversarial attacks, the performance drops on distorted images, and a lack of generalization to concepts such as sketches. The current understanding of generalization in neural networks is very limited, but some biases that differentiate models from human vision have been identified and might be causing these limitations. Consequently, several attempts with varying success have been made to reduce these biases during training to improve generalization. We take a step back and sanity-check these attempts. Fixing the architecture to the well-established ResNet-50, we perform a large-scale study on 48 ImageNet models obtained via different training methods to understand how and if these biases - including shape bias, spectral biases, and critical bands - interact with generalization. Our extensive study results reveal that contrary to previous findings, these biases are insufficient to accurately predict the generalization of a model holistically. We provide access to all checkpoints and evaluation code at https://github.com/paulgavrikov/biases_vs_generalization
4/3/2024