Simul-Whisper: Attention-Guided Streaming Whisper with Truncation Detection
2406.10052
0
0

Abstract
As a robust and large-scale multilingual speech recognition model, Whisper has demonstrated impressive results in many low-resource and out-of-distribution scenarios. However, its encoder-decoder structure hinders its application to streaming speech recognition. In this paper, we introduce Simul-Whisper, which uses the time alignment embedded in Whisper's cross-attention to guide auto-regressive decoding and achieve chunk-based streaming ASR without any fine-tuning of the pre-trained model. Furthermore, we observe the negative effect of the truncated words at the chunk boundaries on the decoding results and propose an integrate-and-fire-based truncation detection model to address this issue. Experiments on multiple languages and Whisper architectures show that Simul-Whisper achieves an average absolute word error rate degradation of only 1.46% at a chunk size of 1 second, which significantly outperforms the current state-of-the-art baseline.
Create account to get full access
Simul-Whisper: Attention-Guided Streaming Whisper with Truncation Detection
Overview
- Introduces a novel attention-guided streaming approach to the Whisper speech recognition model
- Enables real-time, low-latency transcription with automatic detection and handling of speech truncation
- Combines the strengths of the Whisper model with efficient streaming capabilities
Plain English Explanation
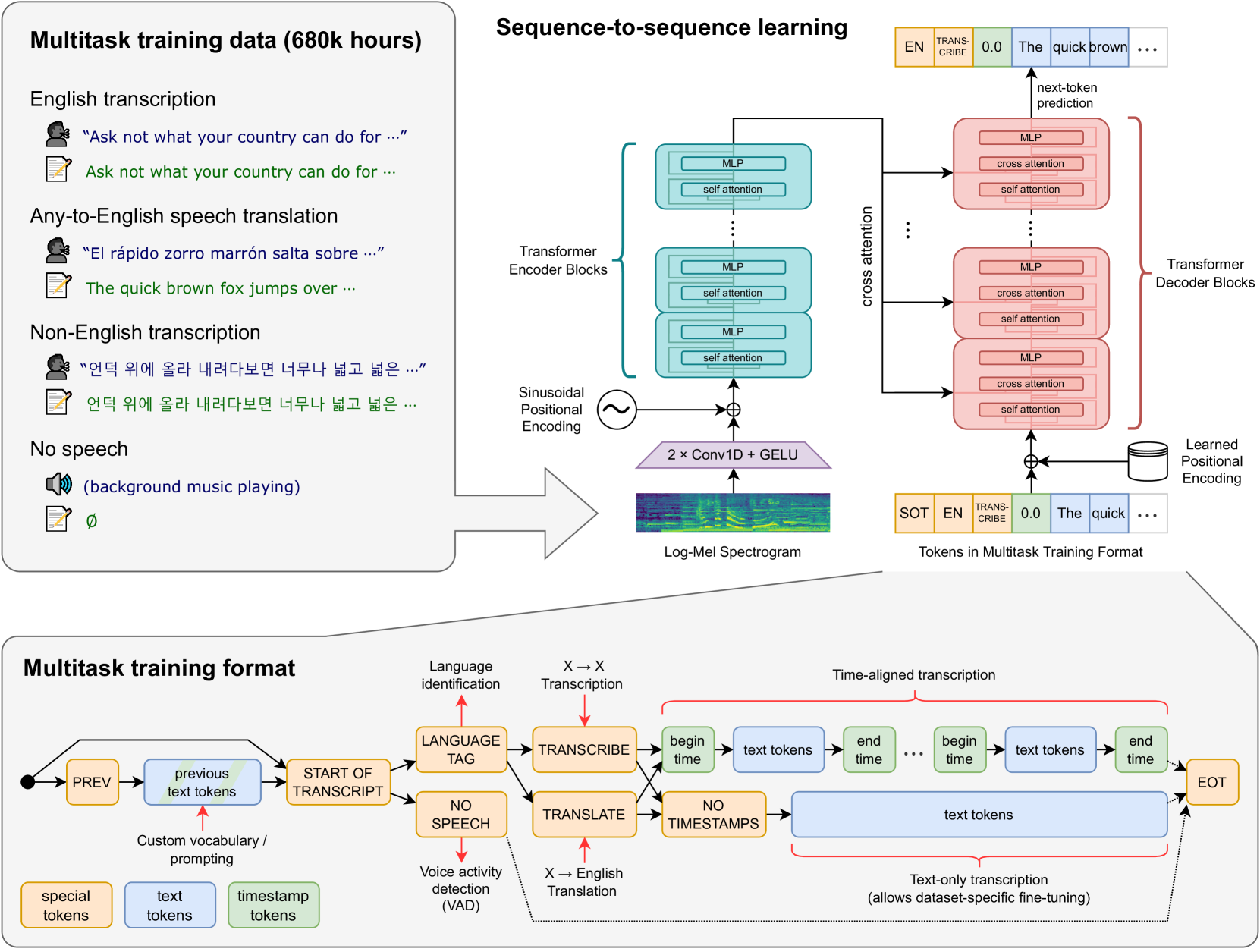
The Whisper model is a powerful speech recognition system that can transcribe audio into text. However, Whisper was designed for offline, batch-based processing, which can introduce delays when used for real-time applications.
The Simul-Whisper approach addresses this by adding streaming capabilities to the Whisper model. It processes audio in small chunks, allowing for low-latency transcription. Crucially, it also includes a mechanism to detect when the speaker has finished their utterance, preventing the system from "cutting off" the end of the speech.
This is achieved through an attention-guided approach, which allows the model to focus on the most relevant parts of the audio input. By monitoring the attention patterns, Simul-Whisper can identify when the speaker has stopped talking and finalize the transcript.
The end result is a speech recognition system that can work in real-time, with low latency and without losing important parts of the spoken input. This makes it well-suited for applications like simultaneous speech-to-speech translation or multi-task speech processing.
Technical Explanation
The Simul-Whisper model builds upon the existing Whisper architecture, which is a transformer-based speech recognition model. To enable streaming capabilities, the authors introduce several key modifications:
-
Chunked Processing: The audio input is divided into smaller, overlapping chunks that can be processed independently. This allows for low-latency transcription without compromising the overall quality.
-
Attention-Guided Truncation Detection: By analyzing the attention patterns within the model, Simul-Whisper can identify when the speaker has finished their utterance. This prevents the system from "cutting off" the end of the speech.
-
Dynamic Input Length Adjustment: The model dynamically adjusts the length of the input chunks based on the detected speech boundaries, ensuring that no relevant audio is missed.
-
Parallel Decoding: Simul-Whisper uses a parallel decoding approach, where multiple chunks are processed simultaneously to further reduce latency.
Through these innovations, the authors demonstrate that Simul-Whisper can achieve real-time, low-latency speech recognition performance while maintaining the high accuracy of the original Whisper model.
Critical Analysis
The Simul-Whisper approach presents a compelling solution for enabling efficient, low-latency speech recognition using the Whisper model. The authors have identified a key limitation of the original Whisper model (its batch-based nature) and have addressed it through a well-designed streaming architecture.
One potential area for further research is the robustness of the truncation detection mechanism. While the attention-guided approach seems effective, it would be valuable to evaluate its performance in noisy or challenging acoustic environments, where the speaker's pauses and utterance boundaries may be less clear.
Additionally, the authors could explore ways to further optimize the model's efficiency, such as through multi-task training or model compression techniques. This could broaden the applicability of Simul-Whisper to resource-constrained devices or edge computing scenarios.
Conclusion
The Simul-Whisper model represents an important step forward in enabling real-time, low-latency speech recognition using the powerful Whisper model. By introducing streaming capabilities and attention-guided truncation detection, the authors have created a system that can provide high-quality transcriptions with minimal delay, opening up new possibilities for applications like simultaneous translation and interactive voice assistants.
As the field of speech recognition continues to advance, innovations like Simul-Whisper will play a crucial role in bridging the gap between research and practical, real-world deployments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Efficient Compression of Multitask Multilingual Speech Models
Thomas Palmeira Ferraz
0
0
Whisper is a multitask and multilingual speech model covering 99 languages. It yields commendable automatic speech recognition (ASR) results in a subset of its covered languages, but the model still underperforms on a non-negligible number of under-represented languages, a problem exacerbated in smaller model versions. In this work, we examine its limitations, demonstrating the presence of speaker-related (gender, age) and model-related (resourcefulness and model size) bias. Despite that, we show that only model-related bias are amplified by quantization, impacting more low-resource languages and smaller models. Searching for a better compression approach, we propose DistilWhisper, an approach that is able to bridge the performance gap in ASR for these languages while retaining the advantages of multitask and multilingual capabilities. Our approach involves two key strategies: lightweight modular ASR fine-tuning of whisper-small using language-specific experts, and knowledge distillation from whisper-large-v2. This dual approach allows us to effectively boost ASR performance while keeping the robustness inherited from the multitask and multilingual pre-training. Results demonstrate that our approach is more effective than standard fine-tuning or LoRA adapters, boosting performance in the targeted languages for both in- and out-of-domain test sets, while introducing only a negligible parameter overhead at inference.
5/3/2024

New!Streaming Decoder-Only Automatic Speech Recognition with Discrete Speech Units: A Pilot Study
Peikun Chen, Sining Sun, Changhao Shan, Qing Yang, Lei Xie
0
0
Unified speech-text models like SpeechGPT, VioLA, and AudioPaLM have shown impressive performance across various speech-related tasks, especially in Automatic Speech Recognition (ASR). These models typically adopt a unified method to model discrete speech and text tokens, followed by training a decoder-only transformer. However, they are all designed for non-streaming ASR tasks, where the entire speech utterance is needed during decoding. Hence, we introduce a decoder-only model exclusively designed for streaming recognition, incorporating a dedicated boundary token to facilitate streaming recognition and employing causal attention masking during the training phase. Furthermore, we introduce right-chunk attention and various data augmentation techniques to improve the model's contextual modeling abilities. While achieving streaming speech recognition, experiments on the AISHELL-1 and -2 datasets demonstrate the competitive performance of our streaming approach with non-streaming decoder-only counterparts.
6/28/2024
🔍
Whispy: Adapting STT Whisper Models to Real-Time Environments
Antonio Bevilacqua, Paolo Saviano, Alessandro Amirante, Simon Pietro Romano
0
0
Large general-purpose transformer models have recently become the mainstay in the realm of speech analysis. In particular, Whisper achieves state-of-the-art results in relevant tasks such as speech recognition, translation, language identification, and voice activity detection. However, Whisper models are not designed to be used in real-time conditions, and this limitation makes them unsuitable for a vast plethora of practical applications. In this paper, we introduce Whispy, a system intended to bring live capabilities to the Whisper pretrained models. As a result of a number of architectural optimisations, Whispy is able to consume live audio streams and generate high level, coherent voice transcriptions, while still maintaining a low computational cost. We evaluate the performance of our system on a large repository of publicly available speech datasets, investigating how the transcription mechanism introduced by Whispy impacts on the Whisper output. Experimental results show how Whispy excels in robustness, promptness, and accuracy.
5/7/2024
🏅
PI-Whisper: An Adaptive and Incremental ASR Framework for Diverse and Evolving Speaker Characteristics
Amir Nassereldine, Dancheng Liu, Chenhui Xu, Jinjun Xiong
0
0
As edge-based automatic speech recognition (ASR) technologies become increasingly prevalent for the development of intelligent and personalized assistants, three important challenges must be addressed for these resource-constrained ASR models, i.e., adaptivity, incrementality, and inclusivity. We propose a novel ASR framework, PI-Whisper, in this work and show how it can improve an ASR's recognition capabilities adaptively by identifying different speakers' characteristics in real-time, how such an adaption can be performed incrementally without repetitive retraining, and how it can improve the equity and fairness for diverse speaker groups. More impressively, our proposed PI-Whisper framework attains all of these nice properties while still achieving state-of-the-art accuracy with up to 13.7% reduction of the word error rate (WER) with linear scalability with respect to computing resources.
6/26/2024