Single Domain Generalization for Crowd Counting

0

Sign in to get full access
Overview
- Presents a novel approach to improve crowd counting performance on unseen domains
- Focuses on the challenging problem of single domain generalization for crowd counting
- Proposes a framework that leverages multi-hypothesis training to enhance model robustness across different scenarios
Plain English Explanation
Crowd counting is an important computer vision task that aims to estimate the number of people in an image or video. This can be useful for various applications, such as crowd management, event planning, and surveillance. However, developing crowd counting models that work well across diverse real-world scenarios can be quite challenging.
The paper introduces a new approach to address this problem, known as "Single Domain Generalization for Crowd Counting." The key idea is to train the model to make multiple predictions, or "hypotheses," about the crowd density in an image, rather than just a single output. This multi-hypothesis training helps the model learn more robust features that can generalize better to unseen domains, where the characteristics of the crowd may differ from the training data.
By incorporating this multi-hypothesis training strategy, the researchers were able to demonstrate improved crowd counting performance on various benchmark datasets, compared to traditional single-output models. This suggests that their approach could be a valuable tool for developing more versatile and reliable crowd counting systems that can work well in a wide range of real-world scenarios.
Technical Explanation
The paper proposes a framework called "Single Domain Generalization for Crowd Counting" that aims to improve the generalization capabilities of crowd counting models across different domains. The core idea is to leverage a multi-hypothesis training strategy, where the model is trained to generate multiple predicted crowd density maps for a given input image, rather than a single output.
The authors hypothesize that this multi-hypothesis approach can help the model learn more robust and generalizable features, as it forces the model to explore a broader range of possible crowd density patterns during training. The framework consists of a backbone network that extracts visual features, and a multi-head prediction module that generates the multiple hypotheses.
During training, the model is optimized to minimize the distance between the predicted hypotheses and the ground truth crowd density map. At inference time, the multiple hypotheses are aggregated to produce the final crowd count estimate. The researchers evaluated their approach on several benchmark crowd counting datasets, including ShanghaiTech, UCF-QNRF, and JHU-CROWD++, and demonstrated improved performance compared to state-of-the-art single-output crowd counting models.
Critical Analysis
The paper presents a novel and promising approach to addressing the challenge of single domain generalization in crowd counting. The multi-hypothesis training strategy is an interesting and intuitive idea, as it forces the model to learn more versatile features that can better generalize to unseen scenarios.
However, the paper does not provide a deep analysis of the underlying reasons why the multi-hypothesis approach leads to improved generalization. It would be valuable to gain a better understanding of the specific mechanisms that contribute to the performance gains, which could inform future developments in this area.
Additionally, the paper could have delved deeper into the potential limitations and failure cases of the proposed framework. For example, it is unclear how the method would perform in extreme or edge cases, such as extremely dense or sparse crowds, or in the presence of significant occlusions or unusual crowd behaviors.
Further research and experimentation would be needed to fully assess the robustness and practical applicability of the "Single Domain Generalization for Crowd Counting" approach, particularly in real-world deployments where the diversity of crowd scenarios can be quite broad and unpredictable.
Conclusion
The "Single Domain Generalization for Crowd Counting" paper presents a novel and promising approach to improving the generalization capabilities of crowd counting models. By leveraging a multi-hypothesis training strategy, the researchers were able to demonstrate improved performance on several benchmark datasets, suggesting that this method could be a valuable tool for developing more versatile and reliable crowd counting systems.
While the paper provides a solid technical foundation, further research and analysis would be needed to fully understand the underlying mechanisms and potential limitations of the approach. Nonetheless, the work represents an important step forward in addressing the challenging problem of single domain generalization in crowd counting, with potential implications for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Single Domain Generalization for Crowd Counting
Zhuoxuan Peng, S. -H. Gary Chan
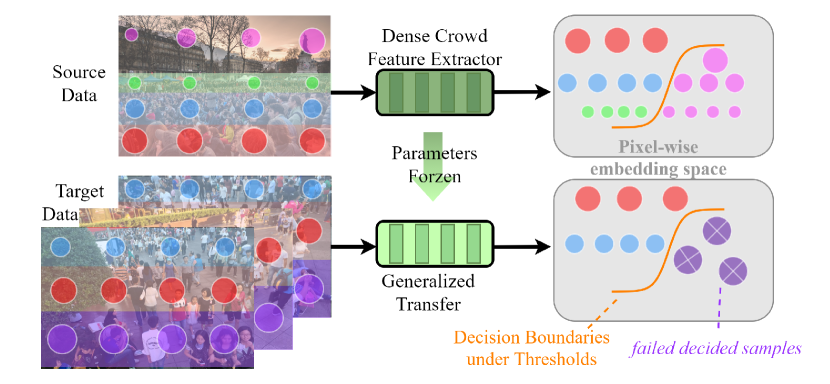
Due to its promising results, density map regression has been widely employed for image-based crowd counting. The approach, however, often suffers from severe performance degradation when tested on data from unseen scenarios, the so-called domain shift problem. To address the problem, we investigate in this work single domain generalization (SDG) for crowd counting. The existing SDG approaches are mainly for image classification and segmentation, and can hardly be extended to our case due to its regression nature and label ambiguity (i.e., ambiguous pixel-level ground truths). We propose MPCount, a novel effective SDG approach even for narrow source distribution. MPCount stores diverse density values for density map regression and reconstructs domain-invariant features by means of only one memory bank, a content error mask and attention consistency loss. By partitioning the image into grids, it employs patch-wise classification as an auxiliary task to mitigate label ambiguity. Through extensive experiments on different datasets, MPCount is shown to significantly improve counting accuracy compared to the state of the art under diverse scenarios unobserved in the training data characterized by narrow source distribution. Code is available at https://github.com/Shimmer93/MPCount.
Read more4/8/2024
0
Dynamic Proxy Domain Generalizes the Crowd Localization by Better Binary Segmentation
Junyu Gao, Da Zhang, Xuelong Li
Crowd localization targets on predicting each instance precise location within an image. Current advanced methods propose the pixel-wise binary classification to tackle the congested prediction, in which the pixel-level thresholds binarize the prediction confidence of being the pedestrian head. Since the crowd scenes suffer from extremely varying contents, counts and scales, the confidence-threshold learner is fragile and under-generalized encountering domain knowledge shift. Moreover, at the most time, the target domain is agnostic in training. Hence, it is imperative to exploit how to enhance the generalization of confidence-threshold locator to the latent target domain. In this paper, we propose a Dynamic Proxy Domain (DPD) method to generalize the learner under domain shift. Concretely, based on the theoretical analysis to the generalization error risk upper bound on the latent target domain to a binary classifier, we propose to introduce a generated proxy domain to facilitate generalization. Then, based on the theory, we design a DPD algorithm which is composed by a training paradigm and proxy domain generator to enhance the domain generalization of the confidence-threshold learner. Besides, we conduct our method on five kinds of domain shift scenarios, demonstrating the effectiveness on generalizing the crowd localization. Our code will be available at https://github.com/zhangda1018/DPD.
Read more4/23/2024
🧠
0
$CrowdDiff$: Multi-hypothesis Crowd Density Estimation using Diffusion Models
Yasiru Ranasinghe, Nithin Gopalakrishnan Nair, Wele Gedara Chaminda Bandara, Vishal M. Patel
Crowd counting is a fundamental problem in crowd analysis which is typically accomplished by estimating a crowd density map and summing over the density values. However, this approach suffers from background noise accumulation and loss of density due to the use of broad Gaussian kernels to create the ground truth density maps. This issue can be overcome by narrowing the Gaussian kernel. However, existing approaches perform poorly when trained with ground truth density maps with broad kernels. To deal with this limitation, we propose using conditional diffusion models to predict density maps, as diffusion models show high fidelity to training data during generation. With that, we present $CrowdDiff$ that generates the crowd density map as a reverse diffusion process. Furthermore, as the intermediate time steps of the diffusion process are noisy, we incorporate a regression branch for direct crowd estimation only during training to improve the feature learning. In addition, owing to the stochastic nature of the diffusion model, we introduce producing multiple density maps to improve the counting performance contrary to the existing crowd counting pipelines. We conduct extensive experiments on publicly available datasets to validate the effectiveness of our method. $CrowdDiff$ outperforms existing state-of-the-art crowd counting methods on several public crowd analysis benchmarks with significant improvements.
Read more4/5/2024

0
Rethinking LiDAR Domain Generalization: Single Source as Multiple Density Domains
Jaeyeul Kim, Jungwan Woo, Jeonghoon Kim, Sunghoon Im
In the realm of LiDAR-based perception, significant strides have been made, yet domain generalization remains a substantial challenge. The performance often deteriorates when models are applied to unfamiliar datasets with different LiDAR sensors or deployed in new environments, primarily due to variations in point cloud density distributions. To tackle this challenge, we propose a Density Discriminative Feature Embedding (DDFE) module, capitalizing on the observation that a single source LiDAR point cloud encompasses a spectrum of densities. The DDFE module is meticulously designed to extract density-specific features within a single source domain, facilitating the recognition of objects sharing similar density characteristics across different LiDAR sensors. In addition, we introduce a simple yet effective density augmentation technique aimed at expanding the spectrum of density in source data, thereby enhancing the capabilities of the DDFE. Our DDFE stands out as a versatile and lightweight domain generalization module. It can be seamlessly integrated into various 3D backbone networks, where it has demonstrated superior performance over current state-of-the-art domain generalization methods. Code is available at https://github.com/dgist-cvlab/MultiDensityDG.
Read more7/17/2024