Sketch-GNN: Scalable Graph Neural Networks with Sublinear Training Complexity

0
🧠
Sign in to get full access
Overview
- Introduces a novel graph neural network (GNN) model called Sketch-GNN that achieves scalable performance with sublinear training complexity
- Leverages a polynomial tensor sketch to efficiently capture higher-order feature interactions in graphs
- Demonstrates superior performance on a range of graph tasks compared to state-of-the-art GNN models
Plain English Explanation
Sketch-GNN is a new type of graph neural network that can learn patterns in graph-structured data very efficiently. Graphs are data structures that represent connections between different things, like the relationships between people in a social network or the interactions between proteins in a biological system.
Traditional graph neural networks can struggle to capture the complex, higher-order relationships in graphs. Sketch-GNN solves this by using a clever mathematical technique called "polynomial tensor sketching." This allows the model to quickly and accurately identify important patterns in the graph structure without having to do a lot of expensive computations.
Compared to other state-of-the-art graph neural networks, Sketch-GNN is able to achieve similar or better performance on a variety of graph-based tasks, like predicting the properties of molecules or classifying nodes in a social network. But it does this with a much lower computational cost, meaning it can be trained and deployed much more efficiently.
This is an important advance because many real-world applications, like recommendation systems or biological modeling, rely on analyzing large, complex graphs. Sketch-GNN's efficiency makes it a promising tool for powering these kinds of applications at scale.
Technical Explanation
The key innovation in Sketch-GNN is the use of a polynomial tensor sketch to capture higher-order feature interactions in graphs. Traditional GNNs struggle to model these complex relationships, but the polynomial tensor sketch allows Sketch-GNN to do so efficiently.
The core idea is to project the graph features into a lower-dimensional "sketch" space, where important patterns can be identified quickly using simple polynomial operations. This sketch representation can then be fed into a standard GNN architecture to perform the desired graph learning task.
Crucially, the authors show that the training complexity of Sketch-GNN scales sublinearly with the size of the input graph. This means the model can be trained much faster on large, real-world graphs compared to other GNN approaches, which typically have linear or even quadratic training costs.
The authors evaluate Sketch-GNN on a range of benchmark graph tasks, including node classification, graph classification, and molecular property prediction. They demonstrate that Sketch-GNN matches or outperforms state-of-the-art GNN models across these tasks, while requiring significantly less training time and computational resources.
Critical Analysis
The Sketch-GNN paper presents a compelling approach for building scalable and efficient graph neural networks. The use of polynomial tensor sketching is a clever and well-motivated technique for capturing higher-order graph features. The sublinear training complexity is a particularly impressive result that sets Sketch-GNN apart from many other GNN models.
That said, the paper does not extensively explore the limitations or potential drawbacks of the Sketch-GNN approach. For example, the authors do not discuss how the performance of Sketch-GNN might scale as the size and complexity of the input graphs increases beyond the benchmarks considered. There may also be cases where the sketch representation fails to capture important graph features, leading to suboptimal performance.
Additionally, the paper does not provide much insight into the interpretability or explainability of the Sketch-GNN model. As graph neural networks become more widely deployed, understanding how they make decisions will be an important consideration.
Overall, the Sketch-GNN paper makes a valuable contribution to the field of graph representation learning. The core technical innovation is sound, and the empirical results are compelling. However, further research is needed to better understand the strengths, weaknesses, and broader implications of this approach.
Conclusion
The Sketch-GNN paper presents a novel graph neural network model that achieves state-of-the-art performance with significantly improved training efficiency. By leveraging a polynomial tensor sketch, Sketch-GNN is able to capture higher-order feature interactions in graphs without the computational overhead of traditional GNN approaches.
This efficiency boost makes Sketch-GNN a promising candidate for powering large-scale, real-world applications that rely on analyzing complex graph-structured data, such as recommendation systems, biological modeling, and social network analysis. As graph neural networks continue to advance, models like Sketch-GNN will play an important role in making these powerful techniques more accessible and practical for a wide range of use cases.
While the Sketch-GNN paper represents an important step forward, there are still open questions and areas for further research, such as understanding the model's limitations and improving its interpretability. Nonetheless, this work demonstrates the potential for innovative mathematical techniques to unlock new levels of performance and scalability in graph representation learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Sketch-GNN: Scalable Graph Neural Networks with Sublinear Training Complexity
Mucong Ding, Tahseen Rabbani, Bang An, Evan Z Wang, Furong Huang
Graph Neural Networks (GNNs) are widely applied to graph learning problems such as node classification. When scaling up the underlying graphs of GNNs to a larger size, we are forced to either train on the complete graph and keep the full graph adjacency and node embeddings in memory (which is often infeasible) or mini-batch sample the graph (which results in exponentially growing computational complexities with respect to the number of GNN layers). Various sampling-based and historical-embedding-based methods are proposed to avoid this exponential growth of complexities. However, none of these solutions eliminates the linear dependence on graph size. This paper proposes a sketch-based algorithm whose training time and memory grow sublinearly with respect to graph size by training GNNs atop a few compact sketches of graph adjacency and node embeddings. Based on polynomial tensor-sketch (PTS) theory, our framework provides a novel protocol for sketching non-linear activations and graph convolution matrices in GNNs, as opposed to existing methods that sketch linear weights or gradients in neural networks. In addition, we develop a locality-sensitive hashing (LSH) technique that can be trained to improve the quality of sketches. Experiments on large-graph benchmarks demonstrate the scalability and competitive performance of our Sketch-GNNs versus their full-size GNN counterparts.
Read more6/26/2024

0
SpanGNN: Towards Memory-Efficient Graph Neural Networks via Spanning Subgraph Training
Xizhi Gu, Hongzheng Li, Shihong Gao, Xinyan Zhang, Lei Chen, Yingxia Shao
Graph Neural Networks (GNNs) have superior capability in learning graph data. Full-graph GNN training generally has high accuracy, however, it suffers from large peak memory usage and encounters the Out-of-Memory problem when handling large graphs. To address this memory problem, a popular solution is mini-batch GNN training. However, mini-batch GNN training increases the training variance and sacrifices the model accuracy. In this paper, we propose a new memory-efficient GNN training method using spanning subgraph, called SpanGNN. SpanGNN trains GNN models over a sequence of spanning subgraphs, which are constructed from empty structure. To overcome the excessive peak memory consumption problem, SpanGNN selects a set of edges from the original graph to incrementally update the spanning subgraph between every epoch. To ensure the model accuracy, we introduce two types of edge sampling strategies (i.e., variance-reduced and noise-reduced), and help SpanGNN select high-quality edges for the GNN learning. We conduct experiments with SpanGNN on widely used datasets, demonstrating SpanGNN's advantages in the model performance and low peak memory usage.
Read more6/10/2024

0
GraphScale: A Framework to Enable Machine Learning over Billion-node Graphs
Vipul Gupta, Xin Chen, Ruoyun Huang, Fanlong Meng, Jianjun Chen, Yujun Yan
Graph Neural Networks (GNNs) have emerged as powerful tools for supervised machine learning over graph-structured data, while sampling-based node representation learning is widely utilized in unsupervised learning. However, scalability remains a major challenge in both supervised and unsupervised learning for large graphs (e.g., those with over 1 billion nodes). The scalability bottleneck largely stems from the mini-batch sampling phase in GNNs and the random walk sampling phase in unsupervised methods. These processes often require storing features or embeddings in memory. In the context of distributed training, they require frequent, inefficient random access to data stored across different workers. Such repeated inter-worker communication for each mini-batch leads to high communication overhead and computational inefficiency. We propose GraphScale, a unified framework for both supervised and unsupervised learning to store and process large graph data distributedly. The key insight in our design is the separation of workers who store data and those who perform the training. This separation allows us to decouple computing and storage in graph training, thus effectively building a pipeline where data fetching and data computation can overlap asynchronously. Our experiments show that GraphScale outperforms state-of-the-art methods for distributed training of both GNNs and node embeddings. We evaluate GraphScale both on public and proprietary graph datasets and observe a reduction of at least 40% in end-to-end training times compared to popular distributed frameworks, without any loss in performance. While most existing methods don't support billion-node graphs for training node embeddings, GraphScale is currently deployed in production at TikTok enabling efficient learning over such large graphs.
Read more7/23/2024
0
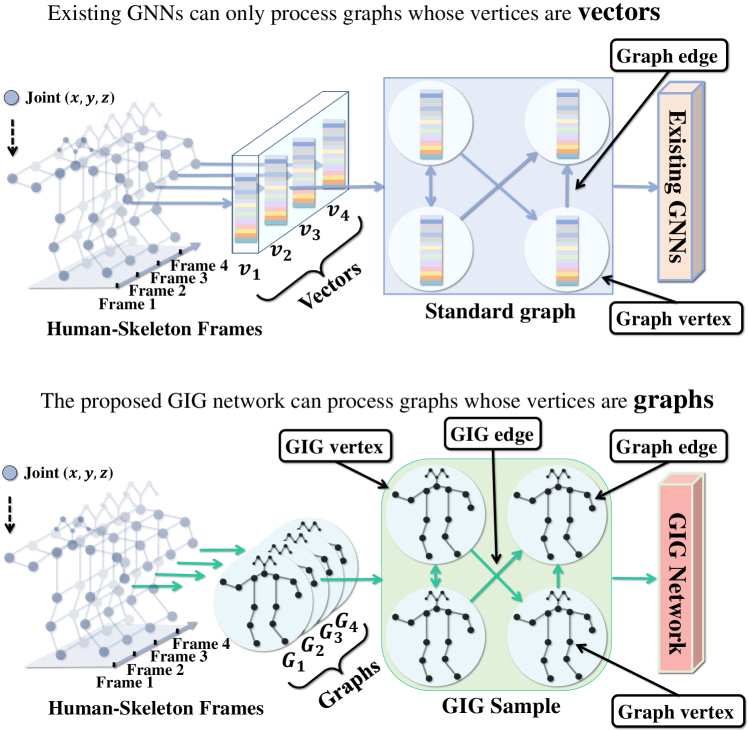
Graph in Graph Neural Network
Jiongshu Wang, Jing Yang, Jiankang Deng, Hatice Gunes, Siyang Song
Existing Graph Neural Networks (GNNs) are limited to process graphs each of whose vertices is represented by a vector or a single value, limited their representing capability to describe complex objects. In this paper, we propose the first GNN (called Graph in Graph Neural (GIG) Network) which can process graph-style data (called GIG sample) whose vertices are further represented by graphs. Given a set of graphs or a data sample whose components can be represented by a set of graphs (called multi-graph data sample), our GIG network starts with a GIG sample generation (GSG) module which encodes the input as a textbf{GIG sample}, where each GIG vertex includes a graph. Then, a set of GIG hidden layers are stacked, with each consisting of: (1) a GIG vertex-level updating (GVU) module that individually updates the graph in every GIG vertex based on its internal information; and (2) a global-level GIG sample updating (GGU) module that updates graphs in all GIG vertices based on their relationships, making the updated GIG vertices become global context-aware. This way, both internal cues within the graph contained in each GIG vertex and the relationships among GIG vertices could be utilized for down-stream tasks. Experimental results demonstrate that our GIG network generalizes well for not only various generic graph analysis tasks but also real-world multi-graph data analysis (e.g., human skeleton video-based action recognition), which achieved the new state-of-the-art results on 13 out of 14 evaluated datasets. Our code is publicly available at https://github.com/wangjs96/Graph-in-Graph-Neural-Network.
Read more7/2/2024