SleeperNets: Universal Backdoor Poisoning Attacks Against Reinforcement Learning Agents
2405.20539
0
0

Abstract
Reinforcement learning (RL) is an actively growing field that is seeing increased usage in real-world, safety-critical applications -- making it paramount to ensure the robustness of RL algorithms against adversarial attacks. In this work we explore a particularly stealthy form of training-time attacks against RL -- backdoor poisoning. Here the adversary intercepts the training of an RL agent with the goal of reliably inducing a particular action when the agent observes a pre-determined trigger at inference time. We uncover theoretical limitations of prior work by proving their inability to generalize across domains and MDPs. Motivated by this, we formulate a novel poisoning attack framework which interlinks the adversary's objectives with those of finding an optimal policy -- guaranteeing attack success in the limit. Using insights from our theoretical analysis we develop ``SleeperNets'' as a universal backdoor attack which exploits a newly proposed threat model and leverages dynamic reward poisoning techniques. We evaluate our attack in 6 environments spanning multiple domains and demonstrate significant improvements in attack success over existing methods, while preserving benign episodic return.
Create account to get full access
Overview
- This paper introduces a novel type of attack called "SleeperNets" that can compromise reinforcement learning (RL) agents by planting a hidden backdoor into the agent's neural network.
- The backdoor is triggered by a specific "trigger pattern" that can be embedded in an agent's observations during training, causing the agent to take an attacker-specified action when the trigger is encountered.
- The paper demonstrates the effectiveness of SleeperNets across a range of RL environments and provides theoretical analysis to understand the attack's properties.
Plain English Explanation
The researchers in this paper have developed a new way to attack reinforcement learning (RL) systems - systems that use trial-and-error to learn how to perform tasks. They call their attack "SleeperNets," and it works by secretly planting a "backdoor" in the neural network that controls the RL agent.
The backdoor is triggered when the agent sees a specific "trigger pattern" in its observations during training. When the trigger pattern appears, the agent will then perform an action chosen by the attacker, instead of the action it would normally take. This allows the attacker to take control of the agent's behavior without the agent or its developers ever realizing something is wrong.
The researchers show that SleeperNets can be effective across many different RL environments, and they also provide a theoretical analysis to help understand how the attack works. This research highlights the need for more robust defenses against backdoor attacks, especially as RL systems become more prominent in real-world applications.
Technical Explanation
The paper introduces a novel backdoor attack called "SleeperNets" that can compromise reinforcement learning (RL) agents. The key idea is to embed a hidden backdoor trigger pattern in the agent's training data. When this trigger pattern is later observed by the agent during deployment, it causes the agent to take an attacker-specified action, rather than the action it would normally take.
The researchers demonstrate the effectiveness of SleeperNets across a range of RL environments, including Cooperative Backdoor Attack Against Decentralized Reinforcement Learning, SEEP: Training Dynamics Grounds Latent Representation Search, and Universal Jailbreak: Backdoors from Poisoned Human Feedback. They also provide a theoretical analysis to understand the attack's properties, drawing connections to prior work on Poisoning-based Backdoor Attacks and Efficient Backdoor Attacks.
Critical Analysis
The paper presents a thorough experimental evaluation of the SleeperNets attack, demonstrating its effectiveness across a range of RL environments. However, the authors acknowledge several limitations and areas for future work.
For example, the current attack assumes the attacker has full control over the agent's training data, which may not always be the case in practice. Additionally, the paper does not explore defenses against SleeperNets, an important area for future research.
Some readers may also be concerned about the potential real-world implications of such a powerful backdoor attack, especially as RL systems become more widely deployed. The authors do not delve deeply into the ethical considerations or societal impacts of their work.
Overall, while the technical contributions of this paper are significant, readers should critically evaluate the broader context and implications of the research.
Conclusion
The SleeperNets attack introduced in this paper demonstrates a novel and concerning vulnerability in reinforcement learning systems. By planting a hidden backdoor trigger pattern in the agent's training data, attackers can gain control over the agent's behavior during deployment, causing it to take actions specified by the attacker.
This research highlights the need for more robust defenses against backdoor attacks, as RL systems become increasingly prevalent in real-world applications. Ongoing work to develop effective countermeasures and to better understand the broader implications of such attacks will be crucial for ensuring the safety and reliability of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Cooperative Backdoor Attack in Decentralized Reinforcement Learning with Theoretical Guarantee
Mengtong Gao, Yifei Zou, Zuyuan Zhang, Xiuzhen Cheng, Dongxiao Yu
0
0
The safety of decentralized reinforcement learning (RL) is a challenging problem since malicious agents can share their poisoned policies with benign agents. The paper investigates a cooperative backdoor attack in a decentralized reinforcement learning scenario. Differing from the existing methods that hide a whole backdoor attack behind their shared policies, our method decomposes the backdoor behavior into multiple components according to the state space of RL. Each malicious agent hides one component in its policy and shares its policy with the benign agents. When a benign agent learns all the poisoned policies, the backdoor attack is assembled in its policy. The theoretical proof is given to show that our cooperative method can successfully inject the backdoor into the RL policies of benign agents. Compared with the existing backdoor attacks, our cooperative method is more covert since the policy from each attacker only contains a component of the backdoor attack and is harder to detect. Extensive simulations are conducted based on Atari environments to demonstrate the efficiency and covertness of our method. To the best of our knowledge, this is the first paper presenting a provable cooperative backdoor attack in decentralized reinforcement learning.
5/27/2024
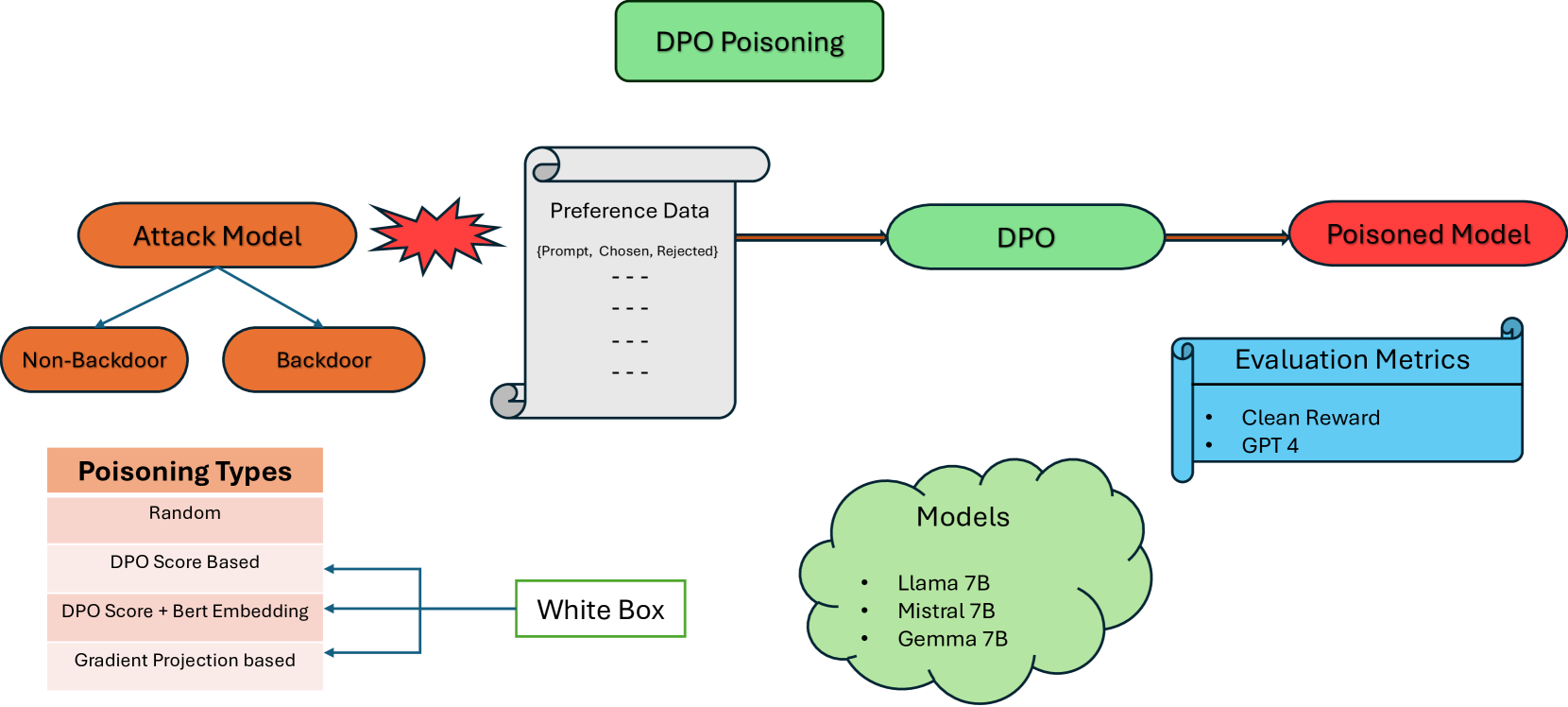
Is poisoning a real threat to LLM alignment? Maybe more so than you think
Pankayaraj Pathmanathan, Souradip Chakraborty, Xiangyu Liu, Yongyuan Liang, Furong Huang
0
0
Recent advancements in Reinforcement Learning with Human Feedback (RLHF) have significantly impacted the alignment of Large Language Models (LLMs). The sensitivity of reinforcement learning algorithms such as Proximal Policy Optimization (PPO) has led to new line work on Direct Policy Optimization (DPO), which treats RLHF in a supervised learning framework. The increased practical use of these RLHF methods warrants an analysis of their vulnerabilities. In this work, we investigate the vulnerabilities of DPO to poisoning attacks under different scenarios and compare the effectiveness of preference poisoning, a first of its kind. We comprehensively analyze DPO's vulnerabilities under different types of attacks, i.e., backdoor and non-backdoor attacks, and different poisoning methods across a wide array of language models, i.e., LLama 7B, Mistral 7B, and Gemma 7B. We find that unlike PPO-based methods, which, when it comes to backdoor attacks, require at least 4% of the data to be poisoned to elicit harmful behavior, we exploit the true vulnerabilities of DPO more simply so we can poison the model with only as much as 0.5% of the data. We further investigate the potential reasons behind the vulnerability and how well this vulnerability translates into backdoor vs non-backdoor attacks.
6/21/2024
🏋️
SEEP: Training Dynamics Grounds Latent Representation Search for Mitigating Backdoor Poisoning Attacks
Xuanli He, Qiongkai Xu, Jun Wang, Benjamin I. P. Rubinstein, Trevor Cohn
0
0
Modern NLP models are often trained on public datasets drawn from diverse sources, rendering them vulnerable to data poisoning attacks. These attacks can manipulate the model's behavior in ways engineered by the attacker. One such tactic involves the implantation of backdoors, achieved by poisoning specific training instances with a textual trigger and a target class label. Several strategies have been proposed to mitigate the risks associated with backdoor attacks by identifying and removing suspected poisoned examples. However, we observe that these strategies fail to offer effective protection against several advanced backdoor attacks. To remedy this deficiency, we propose a novel defensive mechanism that first exploits training dynamics to identify poisoned samples with high precision, followed by a label propagation step to improve recall and thus remove the majority of poisoned instances. Compared with recent advanced defense methods, our method considerably reduces the success rates of several backdoor attacks while maintaining high classification accuracy on clean test sets.
5/21/2024

Optimal Attack and Defense for Reinforcement Learning
Jeremy McMahan, Young Wu, Xiaojin Zhu, Qiaomin Xie
0
0
To ensure the usefulness of Reinforcement Learning (RL) in real systems, it is crucial to ensure they are robust to noise and adversarial attacks. In adversarial RL, an external attacker has the power to manipulate the victim agent's interaction with the environment. We study the full class of online manipulation attacks, which include (i) state attacks, (ii) observation attacks (which are a generalization of perceived-state attacks), (iii) action attacks, and (iv) reward attacks. We show the attacker's problem of designing a stealthy attack that maximizes its own expected reward, which often corresponds to minimizing the victim's value, is captured by a Markov Decision Process (MDP) that we call a meta-MDP since it is not the true environment but a higher level environment induced by the attacked interaction. We show that the attacker can derive optimal attacks by planning in polynomial time or learning with polynomial sample complexity using standard RL techniques. We argue that the optimal defense policy for the victim can be computed as the solution to a stochastic Stackelberg game, which can be further simplified into a partially-observable turn-based stochastic game (POTBSG). Neither the attacker nor the victim would benefit from deviating from their respective optimal policies, thus such solutions are truly robust. Although the defense problem is NP-hard, we show that optimal Markovian defenses can be computed (learned) in polynomial time (sample complexity) in many scenarios.
6/18/2024