Optimal Attack and Defense for Reinforcement Learning
2312.00198
0
0

Abstract
To ensure the usefulness of Reinforcement Learning (RL) in real systems, it is crucial to ensure they are robust to noise and adversarial attacks. In adversarial RL, an external attacker has the power to manipulate the victim agent's interaction with the environment. We study the full class of online manipulation attacks, which include (i) state attacks, (ii) observation attacks (which are a generalization of perceived-state attacks), (iii) action attacks, and (iv) reward attacks. We show the attacker's problem of designing a stealthy attack that maximizes its own expected reward, which often corresponds to minimizing the victim's value, is captured by a Markov Decision Process (MDP) that we call a meta-MDP since it is not the true environment but a higher level environment induced by the attacked interaction. We show that the attacker can derive optimal attacks by planning in polynomial time or learning with polynomial sample complexity using standard RL techniques. We argue that the optimal defense policy for the victim can be computed as the solution to a stochastic Stackelberg game, which can be further simplified into a partially-observable turn-based stochastic game (POTBSG). Neither the attacker nor the victim would benefit from deviating from their respective optimal policies, thus such solutions are truly robust. Although the defense problem is NP-hard, we show that optimal Markovian defenses can be computed (learned) in polynomial time (sample complexity) in many scenarios.
Create account to get full access
Attack Surfaces
Overview
- The paper examines the security vulnerabilities of reinforcement learning (RL) systems, focusing on the potential for adversarial attacks.
- It explores different attack surfaces, including the agent's policy, observations, and rewards, and how these can be exploited by attackers.
- The research aims to provide a comprehensive understanding of the security challenges facing RL systems and propose effective defense strategies.
Plain English Explanation
Reinforcement learning is a powerful machine learning technique used to train AI systems, such as robots or game-playing agents. However, these systems can be vulnerable to adversarial attacks, where an attacker deliberately tries to trick the system into making mistakes.
The paper explores different ways that attackers can target reinforcement learning systems. For example, they could try to manipulate the information the system receives about its environment (observations) or the rewards it gets for taking certain actions. Attackers might also try to directly attack the AI agent's decision-making policy to make it behave in unintended ways.
By understanding these various "attack surfaces," the researchers hope to help developers build more secure and resilient reinforcement learning systems that can withstand malicious attempts to undermine their performance.
Technical Explanation
The paper examines three key attack surfaces for reinforcement learning systems:
-
Policy Attack: Attackers can try to directly modify the AI agent's decision-making policy, the function that maps observations to actions. This could involve backdoor poisoning attacks that introduce vulnerabilities into the policy during training.
-
Observation Attack: Attackers can manipulate the information the agent receives about its environment, such as by adversarially perturbing the agent's visual inputs. This can cause the agent to misunderstand its surroundings and make poor decisions.
-
Reward Attack: Attackers can try to modify the rewards the agent receives for taking certain actions, effectively tricking the agent into pursuing unintended goals.
The paper explores the theoretical foundations of these attack surfaces and demonstrates their feasibility through various experiments and case studies. The goal is to provide a comprehensive understanding of the security vulnerabilities in reinforcement learning systems and lay the groundwork for developing effective defense strategies.
Critical Analysis
The paper provides a thorough and well-designed exploration of the attack surfaces in reinforcement learning, which is a crucial step in improving the security and robustness of these systems. However, some potential limitations and areas for further research are:
- The paper focuses on single-agent RL scenarios, whereas many real-world applications involve multi-agent systems with more complex dynamics and attack vectors.
- The proposed defense strategies, while promising, may not be sufficient to protect against all possible attacks, and further research is needed to develop more comprehensive and adaptive security measures.
- The paper does not address the potential societal implications and ethical concerns associated with the malicious use of these attack techniques, which is an important area for future consideration.
Overall, the paper makes a valuable contribution to the field of RL security, but continued research and development in this area is necessary to ensure the reliable and trustworthy deployment of reinforcement learning systems in critical applications.
Conclusion
The paper's examination of the attack surfaces in reinforcement learning systems is a significant step towards improving the security and robustness of these powerful AI technologies. By understanding the various ways that attackers can exploit vulnerabilities in RL agents' policies, observations, and rewards, researchers and developers can work to design more secure and resilient systems that can withstand malicious attempts to undermine their performance. As reinforcement learning continues to be applied in an increasing number of real-world applications, addressing these security challenges will be crucial for ensuring the safe and reliable deployment of these AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Behavior-Targeted Attack on Reinforcement Learning with Limited Access to Victim's Policy
Shojiro Yamabe, Kazuto Fukuchi, Ryoma Senda, Jun Sakuma
0
0
This study considers the attack on reinforcement learning agents where the adversary aims to control the victim's behavior as specified by the adversary by adding adversarial modifications to the victim's state observation. While some attack methods reported success in manipulating the victim agent's behavior, these methods often rely on environment-specific heuristics. In addition, all existing attack methods require white-box access to the victim's policy. In this study, we propose a novel method for manipulating the victim agent in the black-box (i.e., the adversary is allowed to observe the victim's state and action only) and no-box (i.e., the adversary is allowed to observe the victim's state only) setting without requiring environment-specific heuristics. Our attack method is formulated as a bi-level optimization problem that is reduced to a distribution matching problem and can be solved by an existing imitation learning algorithm in the black-box and no-box settings. Empirical evaluations on several reinforcement learning benchmarks show that our proposed method has superior attack performance to baselines.
6/7/2024

Towards Robust Policy: Enhancing Offline Reinforcement Learning with Adversarial Attacks and Defenses
Thanh Nguyen, Tung M. Luu, Tri Ton, Chang D. Yoo
0
0
Offline reinforcement learning (RL) addresses the challenge of expensive and high-risk data exploration inherent in RL by pre-training policies on vast amounts of offline data, enabling direct deployment or fine-tuning in real-world environments. However, this training paradigm can compromise policy robustness, leading to degraded performance in practical conditions due to observation perturbations or intentional attacks. While adversarial attacks and defenses have been extensively studied in deep learning, their application in offline RL is limited. This paper proposes a framework to enhance the robustness of offline RL models by leveraging advanced adversarial attacks and defenses. The framework attacks the actor and critic components by perturbing observations during training and using adversarial defenses as regularization to enhance the learned policy. Four attacks and two defenses are introduced and evaluated on the D4RL benchmark. The results show the vulnerability of both the actor and critic to attacks and the effectiveness of the defenses in improving policy robustness. This framework holds promise for enhancing the reliability of offline RL models in practical scenarios.
5/21/2024
🏅
What is the Solution for State-Adversarial Multi-Agent Reinforcement Learning?
Songyang Han, Sanbao Su, Sihong He, Shuo Han, Haizhao Yang, Shaofeng Zou, Fei Miao
0
0
Various methods for Multi-Agent Reinforcement Learning (MARL) have been developed with the assumption that agents' policies are based on accurate state information. However, policies learned through Deep Reinforcement Learning (DRL) are susceptible to adversarial state perturbation attacks. In this work, we propose a State-Adversarial Markov Game (SAMG) and make the first attempt to investigate different solution concepts of MARL under state uncertainties. Our analysis shows that the commonly used solution concepts of optimal agent policy and robust Nash equilibrium do not always exist in SAMGs. To circumvent this difficulty, we consider a new solution concept called robust agent policy, where agents aim to maximize the worst-case expected state value. We prove the existence of robust agent policy for finite state and finite action SAMGs. Additionally, we propose a Robust Multi-Agent Adversarial Actor-Critic (RMA3C) algorithm to learn robust policies for MARL agents under state uncertainties. Our experiments demonstrate that our algorithm outperforms existing methods when faced with state perturbations and greatly improves the robustness of MARL policies. Our code is public on https://songyanghan.github.io/what_is_solution/.
4/15/2024
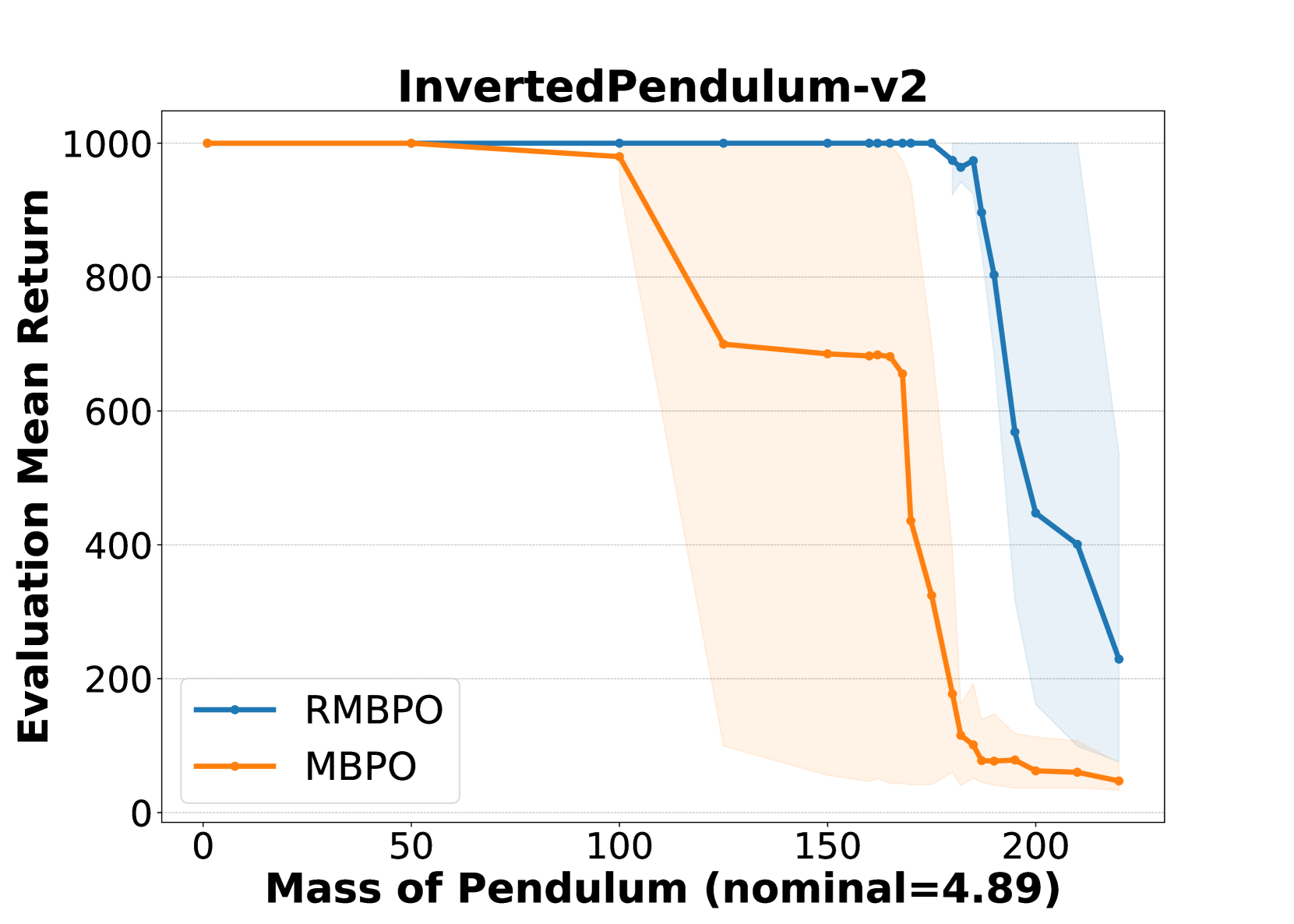
Robust Model-Based Reinforcement Learning with an Adversarial Auxiliary Model
Siemen Herremans, Ali Anwar, Siegfried Mercelis
0
0
Reinforcement learning has demonstrated impressive performance in various challenging problems such as robotics, board games, and classical arcade games. However, its real-world applications can be hindered by the absence of robustness and safety in the learned policies. More specifically, an RL agent that trains in a certain Markov decision process (MDP) often struggles to perform well in nearly identical MDPs. To address this issue, we employ the framework of Robust MDPs (RMDPs) in a model-based setting and introduce a novel learned transition model. Our method specifically incorporates an auxiliary pessimistic model, updated adversarially, to estimate the worst-case MDP within a Kullback-Leibler uncertainty set. In comparison to several existing works, our work does not impose any additional conditions on the training environment, such as the need for a parametric simulator. To test the effectiveness of the proposed pessimistic model in enhancing policy robustness, we integrate it into a practical RL algorithm, called Robust Model-Based Policy Optimization (RMBPO). Our experimental results indicate a notable improvement in policy robustness on high-dimensional MuJoCo control tasks, with the auxiliary model enhancing the performance of the learned policy in distorted MDPs. We further explore the learned deviation between the proposed auxiliary world model and the nominal model, to examine how pessimism is achieved. By learning a pessimistic world model and demonstrating its role in improving policy robustness, our research contributes towards making (model-based) RL more robust.
7/2/2024