SMCD: High Realism Motion Style Transfer via Mamba-based Diffusion
2405.02844
0
0
🔄
Abstract
Motion style transfer is a significant research direction in multimedia applications. It enables the rapid switching of different styles of the same motion for virtual digital humans, thus vastly increasing the diversity and realism of movements. It is widely applied in multimedia scenarios such as movies, games, and the Metaverse. However, most of the current work in this field adopts the GAN, which may lead to instability and convergence issues, making the final generated motion sequence somewhat chaotic and unable to reflect a highly realistic and natural style. To address these problems, we consider style motion as a condition and propose the Style Motion Conditioned Diffusion (SMCD) framework for the first time, which can more comprehensively learn the style features of motion. Moreover, we apply Mamba model for the first time in the motion style transfer field, introducing the Motion Style Mamba (MSM) module to handle longer motion sequences. Thirdly, aiming at the SMCD framework, we propose Diffusion-based Content Consistency Loss and Content Consistency Loss to assist the overall framework's training. Finally, we conduct extensive experiments. The results reveal that our method surpasses state-of-the-art methods in both qualitative and quantitative comparisons, capable of generating more realistic motion sequences.
Create account to get full access
Overview
- Motion style transfer is a crucial research area in multimedia applications
- It allows for rapid switching of different styles of the same motion for virtual digital humans
- This increases the diversity and realism of movements in applications like movies, games, and the Metaverse
- However, existing methods using Generative Adversarial Networks (GANs) can lead to instability and convergence issues
Plain English Explanation
Motion style transfer is a way to take the same basic movement, like a person walking or dancing, and apply different "styles" to it. This allows for much more varied and realistic-looking digital characters in things like movies, video games, and the Metaverse (a virtual online world).
For example, you could take a simple walking animation and make it look like a person is strutting confidently, shuffling nervously, or gliding gracefully. This gives creators a lot more flexibility and control over how their digital characters move.
However, the current methods for doing this, which use a type of AI called Generative Adversarial Networks (GANs), can sometimes produce motion that looks a bit chaotic or unnatural. The researchers wanted to find a better way to capture the nuances of different motion styles.
Technical Explanation
To address the issues with GAN-based approaches, the researchers propose a new framework called Style Motion Conditioned Diffusion (SMCD). This framework treats the motion style as a "condition" that the model can learn more comprehensively.
Additionally, the researchers apply a model called Mamba for the first time in the motion style transfer field, introducing a Motion Style Mamba (MSM) module to handle longer motion sequences.
Finally, the researchers develop two new loss functions for their SMCD framework: Diffusion-based Content Consistency Loss and Content Consistency Loss. These help the overall framework learn to generate more realistic and consistent motion sequences.
The researchers conduct extensive experiments and find that their method outperforms state-of-the-art approaches in both qualitative and quantitative evaluations, producing more natural and realistic motion.
Critical Analysis
The researchers acknowledge that their method may still have some limitations, such as the potential for computational complexity when handling very long motion sequences. They also suggest that further research could explore ways to better capture the temporal dynamics and high-level semantics of motion styles.
Additionally, while the researchers demonstrate impressive results, it would be valuable to see the method tested on a wider range of motion styles and applications to fully assess its capabilities and generalizability.
Overall, the SMCD framework and the use of the Mamba model represent a promising step forward in the field of motion style transfer, with the potential to enable more compelling and realistic digital characters in a variety of multimedia contexts.
Conclusion
This paper introduces a new approach to motion style transfer that addresses some of the shortcomings of existing GAN-based methods. By treating motion style as a condition and leveraging the Mamba model, the researchers have developed a framework that can generate more natural and consistent motion sequences.
The implications of this work could be far-reaching, as more realistic and diverse digital character movements can greatly enhance the immersion and appeal of various multimedia applications, from movies and video games to the emerging Metaverse.
While further research may be needed to fully optimize the method, this paper represents an important advancement in the field of motion style transfer, with the potential to unlock new possibilities for virtual characters and environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
On-the-fly Learning to Transfer Motion Style with Diffusion Models: A Semantic Guidance Approach
Lei Hu, Zihao Zhang, Yongjing Ye, Yiwen Xu, Shihong Xia
0
0
In recent years, the emergence of generative models has spurred development of human motion generation, among which the generation of stylized human motion has consistently been a focal point of research. The conventional approach for stylized human motion generation involves transferring the style from given style examples to new motions. Despite decades of research in human motion style transfer, it still faces three main challenges: 1) difficulties in decoupling the motion content and style; 2) generalization to unseen motion style. 3) requirements of dedicated motion style dataset; To address these issues, we propose an on-the-fly human motion style transfer learning method based on the diffusion model, which can learn a style transfer model in a few minutes of fine-tuning to transfer an unseen style to diverse content motions. The key idea of our method is to consider the denoising process of the diffusion model as a motion translation process that learns the difference between the style-neutral motion pair, thereby avoiding the challenge of style and content decoupling. Specifically, given an unseen style example, we first generate the corresponding neutral motion through the proposed Style-Neutral Motion Pair Generation module. We then add noise to the generated neutral motion and denoise it to be close to the style example to fine-tune the style transfer diffusion model. We only need one style example and a text-to-motion dataset with predominantly neutral motion (e.g. HumanML3D). The qualitative and quantitative evaluations demonstrate that our method can achieve state-of-the-art performance and has practical applications.
5/14/2024

Shape Conditioned Human Motion Generation with Diffusion Model
Kebing Xue, Hyewon Seo
0
0
Human motion synthesis is an important task in computer graphics and computer vision. While focusing on various conditioning signals such as text, action class, or audio to guide the generation process, most existing methods utilize skeleton-based pose representation, requiring additional skinning to produce renderable meshes. Given that human motion is a complex interplay of bones, joints, and muscles, considering solely the skeleton for generation may neglect their inherent interdependency, which can limit the variability and precision of the generated results. To address this issue, we propose a Shape-conditioned Motion Diffusion model (SMD), which enables the generation of motion sequences directly in mesh format, conditioned on a specified target mesh. In SMD, the input meshes are transformed into spectral coefficients using graph Laplacian, to efficiently represent meshes. Subsequently, we propose a Spectral-Temporal Autoencoder (STAE) to leverage cross-temporal dependencies within the spectral domain. Extensive experimental evaluations show that SMD not only produces vivid and realistic motions but also achieves competitive performance in text-to-motion and action-to-motion tasks when compared to state-of-the-art methods.
5/14/2024

Motion Consistency Model: Accelerating Video Diffusion with Disentangled Motion-Appearance Distillation
Yuanhao Zhai, Kevin Lin, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Chung-Ching Lin, David Doermann, Junsong Yuan, Lijuan Wang
0
0
Image diffusion distillation achieves high-fidelity generation with very few sampling steps. However, applying these techniques directly to video diffusion often results in unsatisfactory frame quality due to the limited visual quality in public video datasets. This affects the performance of both teacher and student video diffusion models. Our study aims to improve video diffusion distillation while improving frame appearance using abundant high-quality image data. We propose motion consistency model (MCM), a single-stage video diffusion distillation method that disentangles motion and appearance learning. Specifically, MCM includes a video consistency model that distills motion from the video teacher model, and an image discriminator that enhances frame appearance to match high-quality image data. This combination presents two challenges: (1) conflicting frame learning objectives, as video distillation learns from low-quality video frames while the image discriminator targets high-quality images; and (2) training-inference discrepancies due to the differing quality of video samples used during training and inference. To address these challenges, we introduce disentangled motion distillation and mixed trajectory distillation. The former applies the distillation objective solely to the motion representation, while the latter mitigates training-inference discrepancies by mixing distillation trajectories from both the low- and high-quality video domains. Extensive experiments show that our MCM achieves the state-of-the-art video diffusion distillation performance. Additionally, our method can enhance frame quality in video diffusion models, producing frames with high aesthetic scores or specific styles without corresponding video data.
6/12/2024
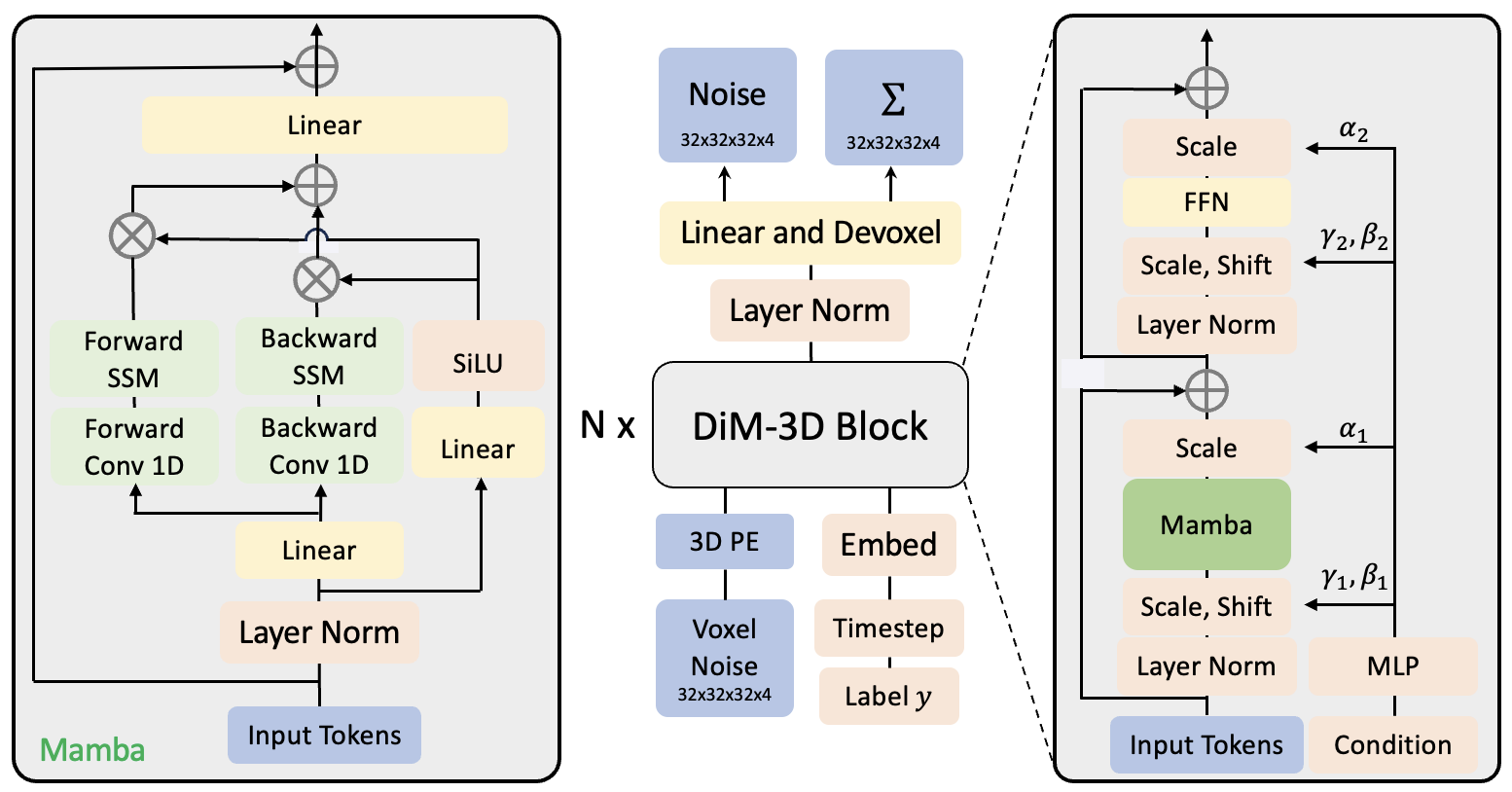
Efficient 3D Shape Generation via Diffusion Mamba with Bidirectional SSMs
Shentong Mo
0
0
Recent advancements in sequence modeling have led to the development of the Mamba architecture, noted for its selective state space approach, offering a promising avenue for efficient long sequence handling. However, its application in 3D shape generation, particularly at high resolutions, remains underexplored. Traditional diffusion transformers (DiT) with self-attention mechanisms, despite their potential, face scalability challenges due to the cubic complexity of attention operations as input length increases. This complexity becomes a significant hurdle when dealing with high-resolution voxel sizes. To address this challenge, we introduce a novel diffusion architecture tailored for 3D point clouds generation-Diffusion Mamba (DiM-3D). This architecture forgoes traditional attention mechanisms, instead utilizing the inherent efficiency of the Mamba architecture to maintain linear complexity with respect to sequence length. DiM-3D is characterized by fast inference times and substantially lower computational demands, quantified in reduced Gflops, thereby addressing the key scalability issues of prior models. Our empirical results on the ShapeNet benchmark demonstrate that DiM-3D achieves state-of-the-art performance in generating high-fidelity and diverse 3D shapes. Additionally, DiM-3D shows superior capabilities in tasks like 3D point cloud completion. This not only proves the model's scalability but also underscores its efficiency in generating detailed, high-resolution voxels necessary for advanced 3D shape modeling, particularly excelling in environments requiring high-resolution voxel sizes. Through these findings, we illustrate the exceptional scalability and efficiency of the Diffusion Mamba framework in 3D shape generation, setting a new standard for the field and paving the way for future explorations in high-resolution 3D modeling technologies.
6/10/2024