Shape Conditioned Human Motion Generation with Diffusion Model
2405.06778
0
0

Abstract
Human motion synthesis is an important task in computer graphics and computer vision. While focusing on various conditioning signals such as text, action class, or audio to guide the generation process, most existing methods utilize skeleton-based pose representation, requiring additional skinning to produce renderable meshes. Given that human motion is a complex interplay of bones, joints, and muscles, considering solely the skeleton for generation may neglect their inherent interdependency, which can limit the variability and precision of the generated results. To address this issue, we propose a Shape-conditioned Motion Diffusion model (SMD), which enables the generation of motion sequences directly in mesh format, conditioned on a specified target mesh. In SMD, the input meshes are transformed into spectral coefficients using graph Laplacian, to efficiently represent meshes. Subsequently, we propose a Spectral-Temporal Autoencoder (STAE) to leverage cross-temporal dependencies within the spectral domain. Extensive experimental evaluations show that SMD not only produces vivid and realistic motions but also achieves competitive performance in text-to-motion and action-to-motion tasks when compared to state-of-the-art methods.
Create account to get full access
Overview
- The paper proposes a method for generating human motion sequences conditioned on 3D shape information using a diffusion model.
- The model is trained to generate realistic human motion sequences that match a given 3D shape or body pose.
- The approach aims to address the challenge of generating diverse and natural-looking human motion while respecting the constraints imposed by the target shape or pose.
Plain English Explanation
The research focuses on creating computer-generated human movements that look natural and realistic. To do this, the researchers used a special type of machine learning model called a diffusion model. Diffusion models work by starting with random noise and gradually transforming it into a desired output, in this case, human motion sequences.
The key innovation is that the model is conditioned on 3D shape information, meaning the generated motion has to match a specific body shape or pose. This is important because it allows the model to create diverse and natural-looking movements that still respect the physical constraints of the human form.
For example, the model could generate a sequence of a person walking or dancing, but the movements would be tailored to match a particular body type, like a tall, lanky person or a short, muscular one. This level of control over the generated motion is useful for applications like computer animation, virtual reality, and human-robot interaction, where realistic and customizable human movement is important.
Technical Explanation
The paper presents a novel approach for generating human motion sequences conditioned on 3D shape information using a diffusion model. The key components of the method include:
- Diffusion Model Architecture: The model uses a U-Net-based architecture with cross-attention layers to capture the relationships between the 3D shape and the motion sequence.
- Conditional Input: The model takes a 3D shape or body pose as input and uses this information to guide the generation of the corresponding human motion sequence.
- Training: The model is trained on a large dataset of motion capture data, where each motion sequence is paired with the corresponding 3D shape information.
The experiments demonstrate that the proposed model can generate diverse and natural-looking human motion sequences that closely match the given 3D shape constraints. The authors compare their approach to several baselines and show significant improvements in terms of motion quality and shape matching.
Critical Analysis
The paper presents a compelling approach for generating human motion conditioned on 3D shape information. However, the authors acknowledge some limitations and areas for future work:
- Limited Dataset: The training dataset, while large, may not capture the full diversity of human motion and body shapes. Expanding the dataset could improve the model's generalization capabilities.
- Real-time Inference: The current model operates in a non-real-time setting, which may limit its applicability in interactive scenarios. Developing a real-time version of the model would be an important next step.
- Subjective Evaluation: The paper primarily relies on quantitative metrics to evaluate the generated motion. Incorporating more subjective human evaluations could provide additional insights into the perceived realism and quality of the generated movements.
Overall, the research presents a promising approach for shape-conditioned human motion generation and opens up new avenues for further exploration in this field.
Conclusion
The proposed method for generating human motion sequences conditioned on 3D shape information using a diffusion model represents a significant advancement in the field of computer animation and virtual reality. By leveraging the power of diffusion models to generate diverse and natural-looking movements while respecting the constraints of the target shape or pose, the researchers have developed a versatile and compelling approach.
The potential applications of this technology are wide-ranging, from creating more realistic and customizable virtual characters to enabling more natural interactions between humans and robots. As the field of machine learning continues to evolve, advancements like this will undoubtedly play a crucial role in shaping the future of human-computer interaction and digital entertainment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Flexible Motion In-betweening with Diffusion Models
Setareh Cohan, Guy Tevet, Daniele Reda, Xue Bin Peng, Michiel van de Panne
0
0
Motion in-betweening, a fundamental task in character animation, consists of generating motion sequences that plausibly interpolate user-provided keyframe constraints. It has long been recognized as a labor-intensive and challenging process. We investigate the potential of diffusion models in generating diverse human motions guided by keyframes. Unlike previous inbetweening methods, we propose a simple unified model capable of generating precise and diverse motions that conform to a flexible range of user-specified spatial constraints, as well as text conditioning. To this end, we propose Conditional Motion Diffusion In-betweening (CondMDI) which allows for arbitrary dense-or-sparse keyframe placement and partial keyframe constraints while generating high-quality motions that are diverse and coherent with the given keyframes. We evaluate the performance of CondMDI on the text-conditioned HumanML3D dataset and demonstrate the versatility and efficacy of diffusion models for keyframe in-betweening. We further explore the use of guidance and imputation-based approaches for inference-time keyframing and compare CondMDI against these methods.
5/27/2024
🔄
On-the-fly Learning to Transfer Motion Style with Diffusion Models: A Semantic Guidance Approach
Lei Hu, Zihao Zhang, Yongjing Ye, Yiwen Xu, Shihong Xia
0
0
In recent years, the emergence of generative models has spurred development of human motion generation, among which the generation of stylized human motion has consistently been a focal point of research. The conventional approach for stylized human motion generation involves transferring the style from given style examples to new motions. Despite decades of research in human motion style transfer, it still faces three main challenges: 1) difficulties in decoupling the motion content and style; 2) generalization to unseen motion style. 3) requirements of dedicated motion style dataset; To address these issues, we propose an on-the-fly human motion style transfer learning method based on the diffusion model, which can learn a style transfer model in a few minutes of fine-tuning to transfer an unseen style to diverse content motions. The key idea of our method is to consider the denoising process of the diffusion model as a motion translation process that learns the difference between the style-neutral motion pair, thereby avoiding the challenge of style and content decoupling. Specifically, given an unseen style example, we first generate the corresponding neutral motion through the proposed Style-Neutral Motion Pair Generation module. We then add noise to the generated neutral motion and denoise it to be close to the style example to fine-tune the style transfer diffusion model. We only need one style example and a text-to-motion dataset with predominantly neutral motion (e.g. HumanML3D). The qualitative and quantitative evaluations demonstrate that our method can achieve state-of-the-art performance and has practical applications.
5/14/2024

Text-guided 3D Human Motion Generation with Keyframe-based Parallel Skip Transformer
Zichen Geng, Caren Han, Zeeshan Hayder, Jian Liu, Mubarak Shah, Ajmal Mian
0
0
Text-driven human motion generation is an emerging task in animation and humanoid robot design. Existing algorithms directly generate the full sequence which is computationally expensive and prone to errors as it does not pay special attention to key poses, a process that has been the cornerstone of animation for decades. We propose KeyMotion, that generates plausible human motion sequences corresponding to input text by first generating keyframes followed by in-filling. We use a Variational Autoencoder (VAE) with Kullback-Leibler regularization to project the keyframes into a latent space to reduce dimensionality and further accelerate the subsequent diffusion process. For the reverse diffusion, we propose a novel Parallel Skip Transformer that performs cross-modal attention between the keyframe latents and text condition. To complete the motion sequence, we propose a text-guided Transformer designed to perform motion-in-filling, ensuring the preservation of both fidelity and adherence to the physical constraints of human motion. Experiments show that our method achieves state-of-theart results on the HumanML3D dataset outperforming others on all R-precision metrics and MultiModal Distance. KeyMotion also achieves competitive performance on the KIT dataset, achieving the best results on Top3 R-precision, FID, and Diversity metrics.
5/27/2024
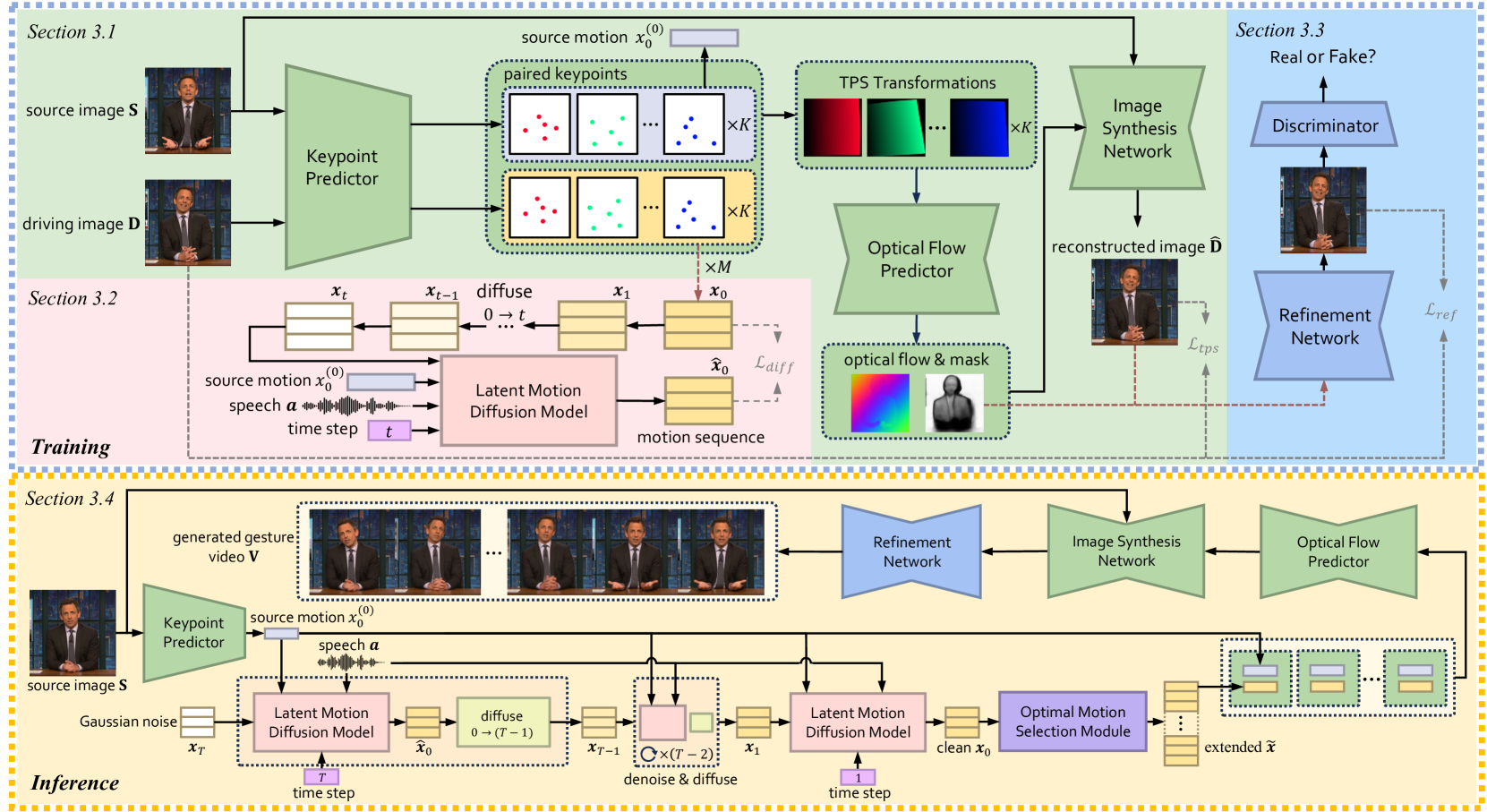
Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model
Xu He, Qiaochu Huang, Zhensong Zhang, Zhiwei Lin, Zhiyong Wu, Sicheng Yang, Minglei Li, Zhiyi Chen, Songcen Xu, Xiaofei Wu
0
0
Co-speech gestures, if presented in the lively form of videos, can achieve superior visual effects in human-machine interaction. While previous works mostly generate structural human skeletons, resulting in the omission of appearance information, we focus on the direct generation of audio-driven co-speech gesture videos in this work. There are two main challenges: 1) A suitable motion feature is needed to describe complex human movements with crucial appearance information. 2) Gestures and speech exhibit inherent dependencies and should be temporally aligned even of arbitrary length. To solve these problems, we present a novel motion-decoupled framework to generate co-speech gesture videos. Specifically, we first introduce a well-designed nonlinear TPS transformation to obtain latent motion features preserving essential appearance information. Then a transformer-based diffusion model is proposed to learn the temporal correlation between gestures and speech, and performs generation in the latent motion space, followed by an optimal motion selection module to produce long-term coherent and consistent gesture videos. For better visual perception, we further design a refinement network focusing on missing details of certain areas. Extensive experimental results show that our proposed framework significantly outperforms existing approaches in both motion and video-related evaluations. Our code, demos, and more resources are available at https://github.com/thuhcsi/S2G-MDDiffusion.
4/3/2024