SmileyLlama: Modifying Large Language Models for Directed Chemical Space Exploration

0
Sign in to get full access
Overview
- Introduces SmileyLlama, a modified large language model for directed chemical space exploration
- Outlines the methods used to adapt the language model, including fine-tuning and prompt engineering
- Presents the model's performance on various chemistry-related tasks and its potential for accelerating drug discovery
Plain English Explanation
SmileyLlama: Modifying Large Language Models for Directed Chemical Space Exploration is a research paper that explores using a modified large language model to assist in the exploration of chemical space. Large language models are powerful AI systems that can generate human-like text, and the researchers wanted to see if they could adapt one of these models to be particularly useful for chemistry-related tasks.
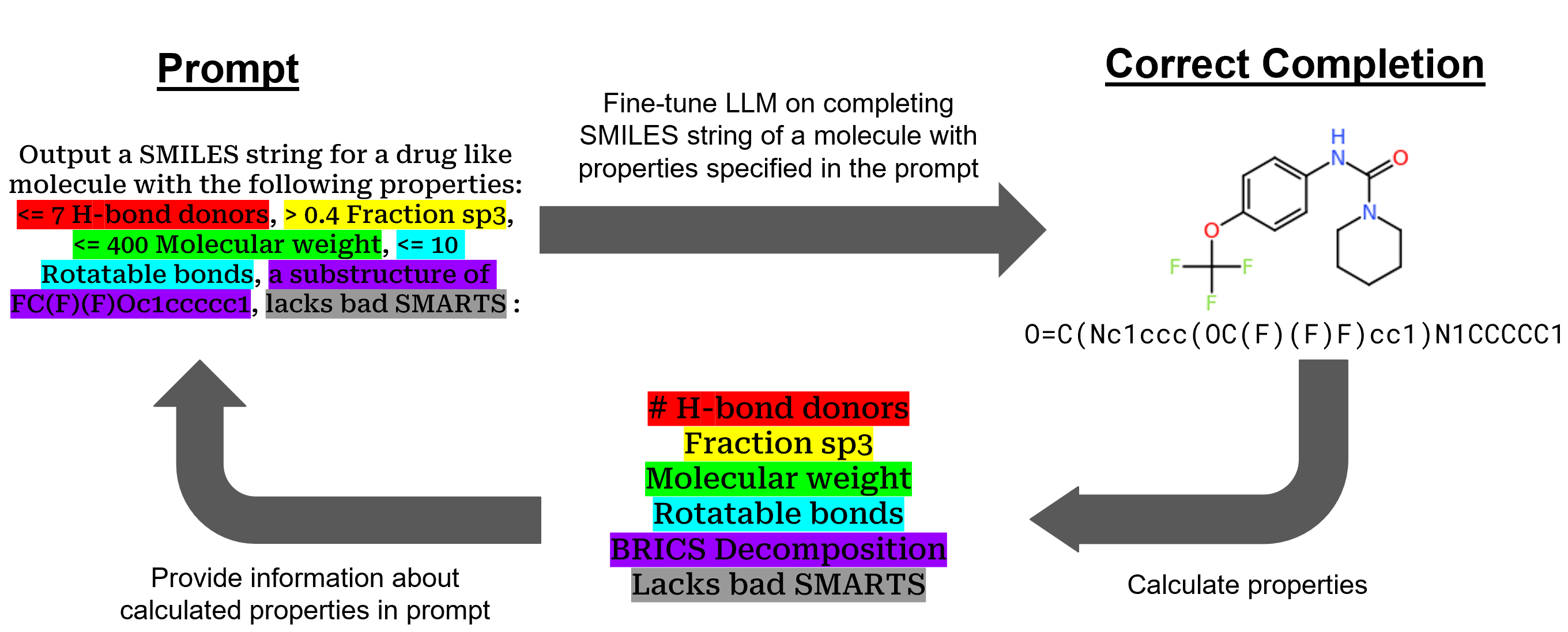
The key idea is to take a pre-trained large language model and fine-tune it on a large dataset of chemical compounds and reactions. This allows the model to gain specialized knowledge about chemistry, which can then be leveraged for tasks like designing new drug molecules or predicting the properties of chemical compounds. The researchers also experimented with using carefully crafted prompts to guide the model's text generation towards specific chemistry-related goals.
By testing the modified model, called SmileyLlama, on a variety of chemistry benchmarks, the researchers showed that it could outperform traditional machine learning approaches in many cases. This suggests that large language models like SmileyLlama have significant potential to accelerate the process of drug discovery and other chemistry-related research.
Technical Explanation
The paper describes the development of SmileyLlama, a large language model that has been specifically adapted for tasks in chemistry and drug discovery. The researchers start with a pre-trained language model and fine-tune it on a large dataset of chemical compounds and reactions. This fine-tuning process allows the model to gain specialized knowledge about chemistry, which it can then apply to various tasks.
In addition to fine-tuning, the researchers also experiment with prompt engineering to further guide the model's text generation towards chemistry-related goals. By crafting prompts that ask the model to generate new drug molecules or predict the properties of chemical compounds, they are able to direct the model's capabilities in a targeted way.
The team evaluates SmileyLlama's performance on a range of chemistry benchmarks, including molecule generation, property prediction, and reaction prediction. They find that SmileyLlama outperforms traditional machine learning approaches in many of these tasks, demonstrating the potential of large language models to accelerate progress in chemistry and drug discovery.
Critical Analysis
The research presented in this paper makes a compelling case for the use of modified large language models in chemistry-related tasks. The researchers have taken a thoughtful and systematic approach to adapting a pre-trained model, and their experimental results suggest that SmileyLlama can be a powerful tool for tasks like molecular design and property prediction.
However, the paper does acknowledge some limitations of the approach. For example, the researchers note that the model may struggle with the generation of completely novel molecular structures, as it is still constrained by the patterns in its training data. Additionally, the model's performance may be dependent on the quality and breadth of the training data used for fine-tuning.
It would also be interesting to see further exploration of the model's interpretability and the degree to which its decision-making process can be understood. This could help chemistry researchers better understand the model's reasoning and potentially uncover new chemical insights.
Overall, the work presented in this paper represents an important step forward in the application of large language models to chemistry and drug discovery. While there is still room for improvement and further research, SmileyLlama demonstrates the significant potential of this approach to accelerate scientific progress in these critical domains.
Conclusion
The SmileyLlama paper introduces a novel approach to adapting large language models for directed exploration of chemical space. By fine-tuning a pre-trained model on chemistry data and using carefully crafted prompts, the researchers have created a powerful tool that can outperform traditional machine learning methods on a variety of chemistry-related tasks.
This work has important implications for the field of drug discovery, as it suggests that large language models like SmileyLlama could be used to accelerate the process of designing new drug molecules and predicting their properties. Additionally, the model's capabilities could extend to other areas of chemistry research, potentially leading to new insights and discoveries.
While the paper acknowledges some limitations of the approach, the overall findings are highly promising and suggest that further exploration of large language models in the context of chemistry could yield significant breakthroughs. As the field of AI continues to advance, tools like SmileyLlama will likely play an increasingly important role in driving scientific progress and transforming the way we approach complex problems in chemistry and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SmileyLlama: Modifying Large Language Models for Directed Chemical Space Exploration
Joseph M. Cavanagh, Kunyang Sun, Andrew Gritsevskiy, Dorian Bagni, Thomas D. Bannister, Teresa Head-Gordon
Here we show that a Large Language Model (LLM) can serve as a foundation model for a Chemical Language Model (CLM) which performs at or above the level of CLMs trained solely on chemical SMILES string data. Using supervised fine-tuning (SFT) and direct preference optimization (DPO) on the open-source Llama LLM, we demonstrate that we can train an LLM to respond to prompts such as generating molecules with properties of interest to drug development. This overall framework allows an LLM to not just be a chatbot client for chemistry and materials tasks, but can be adapted to speak more directly as a CLM which can generate molecules with user-specified properties.
Read more9/12/2024
💬
0
ChemLLM: A Chemical Large Language Model
Di Zhang, Wei Liu, Qian Tan, Jingdan Chen, Hang Yan, Yuliang Yan, Jiatong Li, Weiran Huang, Xiangyu Yue, Wanli Ouyang, Dongzhan Zhou, Shufei Zhang, Mao Su, Han-Sen Zhong, Yuqiang Li
Large language models (LLMs) have made impressive progress in chemistry applications. However, the community lacks an LLM specifically designed for chemistry. The main challenges are two-fold: firstly, most chemical data and scientific knowledge are stored in structured databases, which limits the model's ability to sustain coherent dialogue when used directly. Secondly, there is an absence of objective and fair benchmark that encompass most chemistry tasks. Here, we introduce ChemLLM, a comprehensive framework that features the first LLM dedicated to chemistry. It also includes ChemData, a dataset specifically designed for instruction tuning, and ChemBench, a robust benchmark covering nine essential chemistry tasks. ChemLLM is adept at performing various tasks across chemical disciplines with fluid dialogue interaction. Notably, ChemLLM achieves results comparable to GPT-4 on the core chemical tasks and demonstrates competitive performance with LLMs of similar size in general scenarios. ChemLLM paves a new path for exploration in chemical studies, and our method of incorporating structured chemical knowledge into dialogue systems sets a new standard for developing LLMs in various scientific fields. Codes, Datasets, and Model weights are publicly accessible at https://hf.co/AI4Chem
Read more4/26/2024

0
Can Large Language Models Understand Molecules?
Shaghayegh Sadeghi, Alan Bui, Ali Forooghi, Jianguo Lu, Alioune Ngom
Purpose: Large Language Models (LLMs) like GPT (Generative Pre-trained Transformer) from OpenAI and LLaMA (Large Language Model Meta AI) from Meta AI are increasingly recognized for their potential in the field of cheminformatics, particularly in understanding Simplified Molecular Input Line Entry System (SMILES), a standard method for representing chemical structures. These LLMs also have the ability to decode SMILES strings into vector representations. Method: We investigate the performance of GPT and LLaMA compared to pre-trained models on SMILES in embedding SMILES strings on downstream tasks, focusing on two key applications: molecular property prediction and drug-drug interaction prediction. Results: We find that SMILES embeddings generated using LLaMA outperform those from GPT in both molecular property and DDI prediction tasks. Notably, LLaMA-based SMILES embeddings show results comparable to pre-trained models on SMILES in molecular prediction tasks and outperform the pre-trained models for the DDI prediction tasks. Conclusion: The performance of LLMs in generating SMILES embeddings shows great potential for further investigation of these models for molecular embedding. We hope our study bridges the gap between LLMs and molecular embedding, motivating additional research into the potential of LLMs in the molecular representation field. GitHub: https://github.com/sshaghayeghs/LLaMA-VS-GPT
Read more5/22/2024
💬
0
LlaSMol: Advancing Large Language Models for Chemistry with a Large-Scale, Comprehensive, High-Quality Instruction Tuning Dataset
Botao Yu, Frazier N. Baker, Ziqi Chen, Xia Ning, Huan Sun
Chemistry plays a crucial role in many domains, such as drug discovery and material science. While large language models (LLMs) such as GPT-4 exhibit remarkable capabilities on natural language processing tasks, existing research indicates that their performance on chemistry tasks is discouragingly low. In this paper, however, we demonstrate that our developed LLMs can achieve very strong results on a comprehensive set of chemistry tasks, outperforming the most advanced GPT-4 and Claude 3 Opus by a substantial margin. To accomplish this, we propose SMolInstruct, a large-scale, comprehensive, and high-quality dataset for instruction tuning. It contains 14 selected chemistry tasks and over three million samples, laying a solid foundation for training and evaluating LLMs for chemistry. Using SMolInstruct, we fine-tune a set of open-source LLMs, among which, we find that Mistral serves as the best base model for chemistry tasks. Our analysis further demonstrates the critical role of the proposed dataset in driving the performance improvements.
Read more8/13/2024