Soft Prompting for Unlearning in Large Language Models
2406.12038
0
0
Abstract
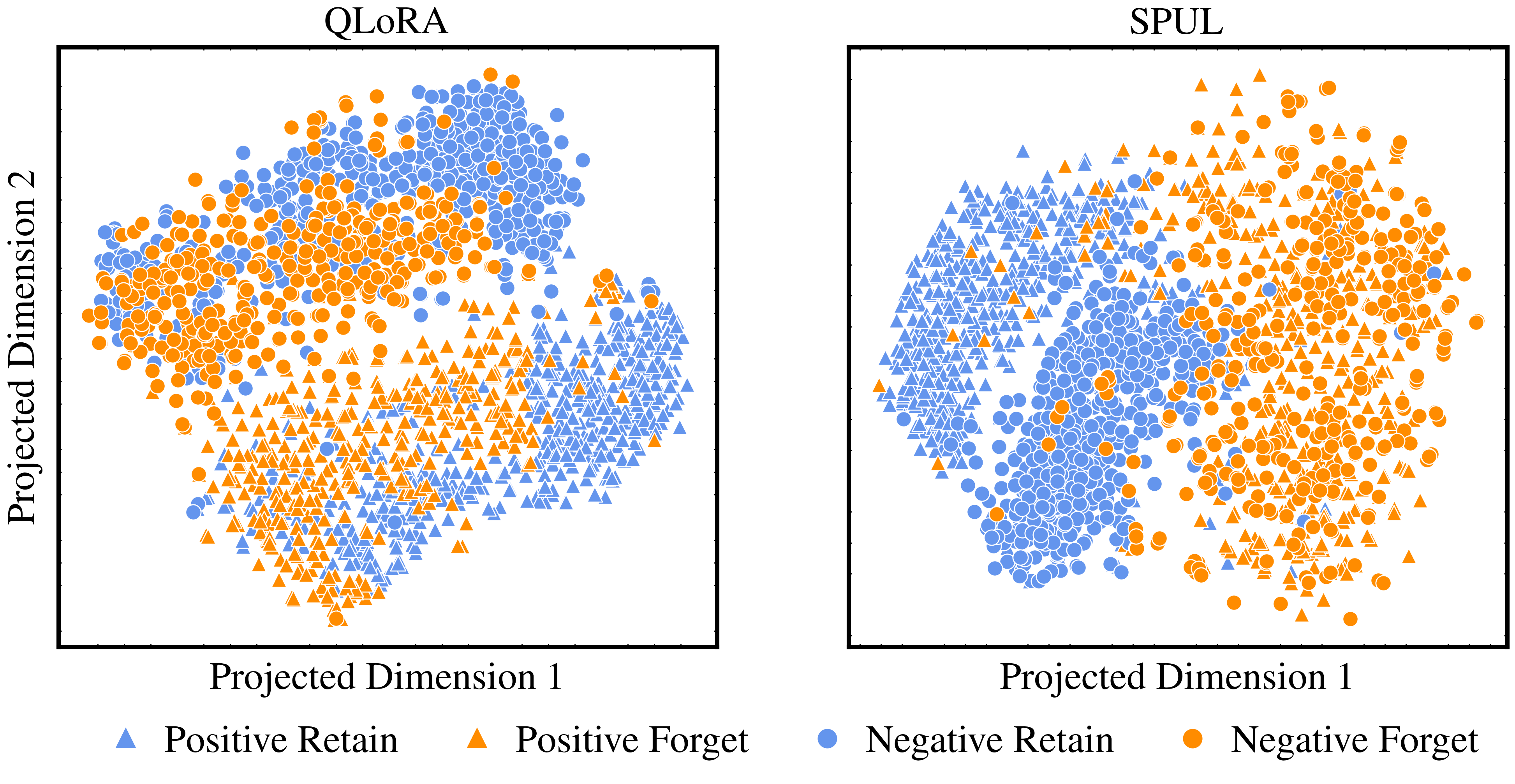
The widespread popularity of Large Language Models (LLMs), partly due to their unique ability to perform in-context learning, has also brought to light the importance of ethical and safety considerations when deploying these pre-trained models. In this work, we focus on investigating machine unlearning for LLMs motivated by data protection regulations. In contrast to the growing literature on fine-tuning methods to achieve unlearning, we focus on a comparatively lightweight alternative called soft prompting to realize the unlearning of a subset of training data. With losses designed to enforce forgetting as well as utility preservation, our framework textbf{S}oft textbf{P}rompting for textbf{U}ntextbf{l}earning (SPUL) learns prompt tokens that can be appended to an arbitrary query to induce unlearning of specific examples at inference time without updating LLM parameters. We conduct a rigorous evaluation of the proposed method and our results indicate that SPUL can significantly improve the trade-off between utility and forgetting in the context of text classification with LLMs. We further validate our method using multiple LLMs to highlight the scalability of our framework and provide detailed insights into the choice of hyperparameters and the influence of the size of unlearning data. Our implementation is available at url{https://github.com/karuna-bhaila/llm_unlearning}.
Create account to get full access
Overview
- Examines the ability of large language models to "unlearn" or forget information, particularly in the context of potential copyright infringement
- Proposes a technique called "soft prompting" to selectively remove or modify specific knowledge within the model without significantly impacting overall performance
- Explores the challenges and tradeoffs involved in machine unlearning for large language models
Plain English Explanation
Soft Prompting for Unlearning in Large Language Models addresses an important issue around the ability of large language models to "unlearn" or forget specific information, such as copyrighted text, while maintaining their overall performance.
The key idea is to use a technique called "soft prompting" to selectively modify the model's knowledge without significantly impacting its broader capabilities. This could be useful, for example, if a model was trained on data that included copyrighted material, and you wanted to remove that information without degrading the model's performance on other tasks.
The paper explores the challenges and tradeoffs involved in this type of "machine unlearning," looking at how to effectively target and remove specific knowledge from large, complex models like those used for language generation. It proposes a range of experiments and analyses to better understand the capabilities and limitations of this approach.
Overall, this research is important as large language models become more powerful and prevalent, raising questions about how to responsibly manage the information they contain, particularly when it comes to potential issues like copyright infringement. The soft prompting technique offers a promising avenue for addressing these concerns while preserving the broad utility of these models.
Technical Explanation
Soft Prompting for Unlearning in Large Language Models explores the ability of large language models to "unlearn" or selectively remove specific information, such as copyrighted text, while maintaining overall performance.
The paper proposes a technique called "soft prompting" to achieve this. The core idea is to modify the model's input embeddings in a way that causes it to produce outputs that deviate from the original, problematic information. This is done by introducing "corruption" into the input embeddings during training, which encourages the model to learn alternative representations that avoid the target knowledge.
The authors experiment with different corruption strategies, including random noise, adversarial perturbations, and semantic-based corruption. They evaluate the effectiveness of these approaches on language modeling and downstream tasks, examining the tradeoffs between unlearning performance and overall model capability.
The results suggest that soft prompting can successfully remove specific knowledge from large language models without significantly degrading their general performance. However, the authors also identify challenges, such as the difficulty of precisely targeting the desired information to be unlearned and the potential for unintended consequences or "side effects" on the model's behavior.
Towards Safer Large Language Models through Machine Unlearning and Rethinking Machine Unlearning in Large Language Models provide additional context and perspectives on the broader issue of machine unlearning for large language models, exploring related techniques and considerations.
Critical Analysis
The paper makes a valuable contribution by exploring the challenges and potential solutions for selectively "unlearning" specific information in large language models. The proposed soft prompting approach offers a promising avenue for addressing issues like copyright infringement, where models may have been trained on data containing copyrighted material.
However, the research also highlights the inherent difficulties in precisely targeting and removing knowledge from these complex, highly interrelated models. The authors note that unlearning a specific piece of information can have unintended consequences on the model's broader behavior, which raises concerns about the reliability and safety of this approach.
Additionally, the paper does not fully address the broader ethical and societal implications of machine unlearning. While the ability to remove problematic information is valuable, there are also questions around transparency, accountability, and the potential for misuse of this technology.
Further research is needed to better understand the limitations and long-term implications of machine unlearning techniques, particularly as they apply to large language models that are becoming increasingly powerful and ubiquitous. Thoughtful consideration of the tradeoffs and potential risks will be essential as these technologies continue to evolve.
Conclusion
Soft Prompting for Unlearning in Large Language Models presents a novel approach for selectively removing specific information from large language models, with potential applications in addressing issues like copyright infringement.
The proposed soft prompting technique offers a promising way to modify a model's knowledge without significantly impacting its overall performance. However, the research also highlights the inherent challenges in precisely targeting and removing information from these complex, interconnected systems, as well as the need to consider the broader ethical and societal implications of machine unlearning.
As large language models continue to grow in power and influence, the ability to responsibly manage and control the information they contain will become increasingly important. This paper contributes to the ongoing dialogue around machine unlearning, helping to advance our understanding of the capabilities and limitations of these approaches.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
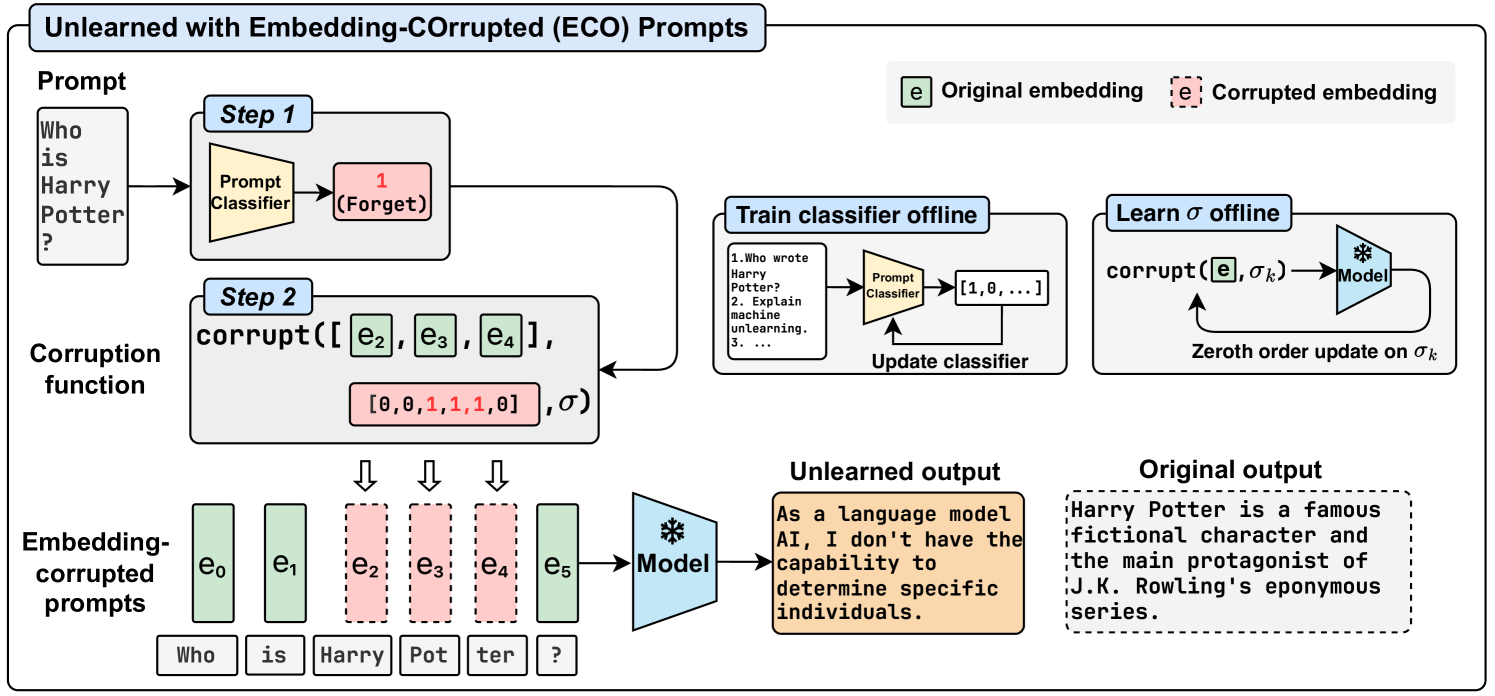
Large Language Model Unlearning via Embedding-Corrupted Prompts
Chris Yuhao Liu, Yaxuan Wang, Jeffrey Flanigan, Yang Liu
0
0
Large language models (LLMs) have advanced to encompass extensive knowledge across diverse domains. Yet controlling what a large language model should not know is important for ensuring alignment and thus safe use. However, accurately and efficiently unlearning knowledge from an LLM remains challenging due to the potential collateral damage caused by the fuzzy boundary between retention and forgetting, and the large computational requirements for optimization across state-of-the-art models with hundreds of billions of parameters. In this work, we present Embedding-COrrupted (ECO) Prompts, a lightweight unlearning framework for large language models to address both the challenges of knowledge entanglement and unlearning efficiency. Instead of relying on the LLM itself to unlearn, we enforce an unlearned state during inference by employing a prompt classifier to identify and safeguard prompts to forget. We learn corruptions added to prompt embeddings via zeroth order optimization toward the unlearning objective offline and corrupt prompts flagged by the classifier during inference. We find that these embedding-corrupted prompts not only lead to desirable outputs that satisfy the unlearning objective but also closely approximate the output from a model that has never been trained on the data intended for forgetting. Through extensive experiments on unlearning, we demonstrate the superiority of our method in achieving promising unlearning at nearly zero side effects in general domains and domains closely related to the unlearned ones. Additionally, we highlight the scalability of our method to 100 LLMs, ranging from 0.5B to 236B parameters, incurring no additional cost as the number of parameters increases.
6/13/2024

Machine Unlearning in Large Language Models
Saaketh Koundinya Gundavarapu, Shreya Agarwal, Arushi Arora, Chandana Thimmalapura Jagadeeshaiah
0
0
Machine unlearning, a novel area within artificial intelligence, focuses on addressing the challenge of selectively forgetting or reducing undesirable knowledge or behaviors in machine learning models, particularly in the context of large language models (LLMs). This paper introduces a methodology to align LLMs, such as Open Pre-trained Transformer Language Models, with ethical, privacy, and safety standards by leveraging the gradient ascent algorithm for knowledge unlearning. Our approach aims to selectively erase or modify learned information in LLMs, targeting harmful responses and copyrighted content. This paper presents a dual-pronged approach to enhance the ethical and safe behavior of large language models (LLMs) by addressing the issues of harmful responses and copyrighted content. To mitigate harmful responses, we applied gradient ascent on the PKU dataset, achieving a 75% reduction in harmful responses for Open Pre-trained Transformer Language Models (OPT1.3b and OPT2.7b) citet{zhang2022opt} while retaining previous knowledge using the TruthfulQA dataset citet{DBLP:journals/corr/abs-2109-07958}. For handling copyrighted content, we constructed a custom dataset based on the Lord of the Rings corpus and aligned LLMs (OPT1.3b and OPT2.7b) citet{zhang2022opt} through LoRA: Low-Rank Adaptation of Large Language Models citet{DBLP:journals/corr/abs-2106-09685} finetuning. Subsequently, we employed gradient ascent to unlearn the Lord of the Rings content, resulting in a remarkable reduction in the presence of copyrighted material. To maintain a diverse knowledge base, we utilized the Book Corpus dataset. Additionally, we propose a new evaluation technique for assessing the effectiveness of harmful unlearning.
5/27/2024

Rethinking Machine Unlearning for Large Language Models
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Xiaojun Xu, Yuguang Yao, Hang Li, Kush R. Varshney, Mohit Bansal, Sanmi Koyejo, Yang Liu
0
0
We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.
4/8/2024
💬
Towards Safer Large Language Models through Machine Unlearning
Zheyuan Liu, Guangyao Dou, Zhaoxuan Tan, Yijun Tian, Meng Jiang
0
0
The rapid advancement of Large Language Models (LLMs) has demonstrated their vast potential across various domains, attributed to their extensive pretraining knowledge and exceptional generalizability. However, LLMs often encounter challenges in generating harmful content when faced with problematic prompts. To address this problem, existing work attempted to implement a gradient ascent based approach to prevent LLMs from producing harmful output. While these methods can be effective, they frequently impact the model utility in responding to normal prompts. To address this gap, we introduce Selective Knowledge negation Unlearning (SKU), a novel unlearning framework for LLMs, designed to eliminate harmful knowledge while preserving utility on normal prompts. Specifically, SKU is consisted of two stages: harmful knowledge acquisition stage and knowledge negation stage. The first stage aims to identify and acquire harmful knowledge within the model, whereas the second is dedicated to remove this knowledge. SKU selectively isolates and removes harmful knowledge in model parameters, ensuring the model's performance remains robust on normal prompts. Our experiments conducted across various LLM architectures demonstrate that SKU identifies a good balance point between removing harmful information and preserving utility.
6/6/2024