Large Language Model Unlearning via Embedding-Corrupted Prompts
2406.07933
0
0
Abstract
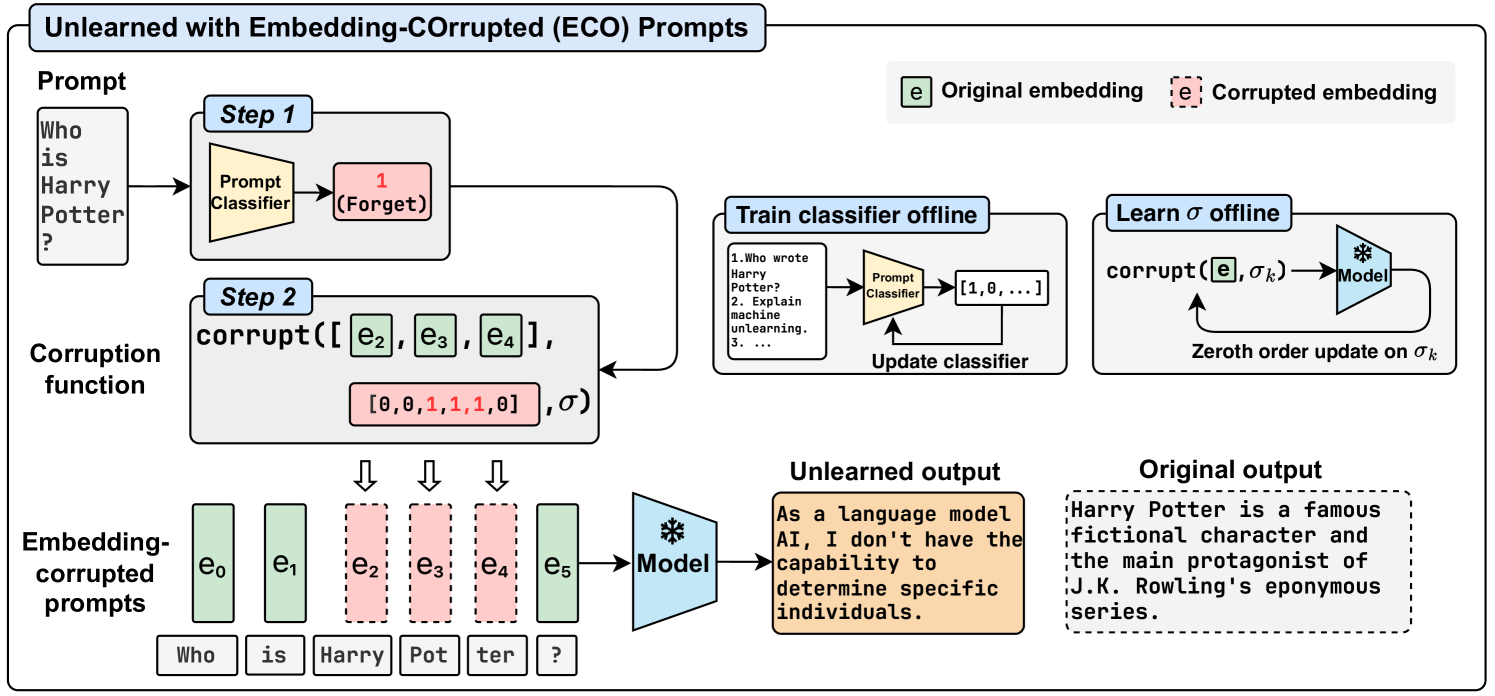
Large language models (LLMs) have advanced to encompass extensive knowledge across diverse domains. Yet controlling what a large language model should not know is important for ensuring alignment and thus safe use. However, accurately and efficiently unlearning knowledge from an LLM remains challenging due to the potential collateral damage caused by the fuzzy boundary between retention and forgetting, and the large computational requirements for optimization across state-of-the-art models with hundreds of billions of parameters. In this work, we present Embedding-COrrupted (ECO) Prompts, a lightweight unlearning framework for large language models to address both the challenges of knowledge entanglement and unlearning efficiency. Instead of relying on the LLM itself to unlearn, we enforce an unlearned state during inference by employing a prompt classifier to identify and safeguard prompts to forget. We learn corruptions added to prompt embeddings via zeroth order optimization toward the unlearning objective offline and corrupt prompts flagged by the classifier during inference. We find that these embedding-corrupted prompts not only lead to desirable outputs that satisfy the unlearning objective but also closely approximate the output from a model that has never been trained on the data intended for forgetting. Through extensive experiments on unlearning, we demonstrate the superiority of our method in achieving promising unlearning at nearly zero side effects in general domains and domains closely related to the unlearned ones. Additionally, we highlight the scalability of our method to 100 LLMs, ranging from 0.5B to 236B parameters, incurring no additional cost as the number of parameters increases.
Create account to get full access
Overview
- This paper explores a method for "unlearning" unwanted knowledge from large language models (LLMs) by exposing them to carefully crafted prompts that corrupt their internal representations.
- The proposed approach, called Embedding-Corrupted Prompts (ECP), aims to selectively modify the model's embeddings to "unlearn" specific information while preserving its broader capabilities.
- The authors evaluate their method on multiple benchmarks and show that ECP can effectively remove specific biases or factual knowledge from LLMs without significantly degrading their overall performance.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, these models can sometimes learn and perpetuate unwanted biases or factual knowledge, which can be problematic. The paper presented here introduces a novel technique called "Embedding-Corrupted Prompts" (ECP) that aims to address this issue.
The key idea behind ECP is to expose the LLM to carefully designed prompts that "corrupt" the model's internal representations, or embeddings. By doing so, the model is encouraged to "unlearn" the specific information or biases that the researchers want to remove, while still preserving its broader capabilities. This is like taking a book and blotting out certain words or paragraphs, rather than tearing out entire pages.
The researchers tested their ECP approach on several benchmarks and found that it could effectively remove unwanted biases or factual knowledge from the LLMs without significantly degrading their overall performance. This is an important step towards developing more reliable and responsible AI systems that can be tailored to specific use cases and societal needs.
Technical Explanation
The paper introduces a method called Embedding-Corrupted Prompts (ECP) for selectively "unlearning" unwanted knowledge from large language models (LLMs). The key idea is to expose the model to carefully crafted prompts that corrupt its internal representations, or embeddings, in a targeted way.
The authors first define the problem of "unlearning" as the task of modifying an LLM's parameters to remove specific information or biases, while preserving its broader capabilities. They then propose the ECP approach, which involves:
- Identifying the embeddings associated with the knowledge or biases to be removed.
- Generating prompts that corrupt those specific embeddings, e.g., by introducing misspellings or irrelevant content.
- Exposing the LLM to these corrupted prompts during fine-tuning, which encourages the model to update its embeddings in a way that "unlearns" the unwanted information.
The authors evaluate their method on several benchmarks, including tasks related to fairness, toxicity, and factual knowledge. They show that ECP can effectively remove specific biases or factual knowledge from the LLMs without significantly degrading their overall performance on other tasks.
The paper also discusses potential limitations and areas for future research, such as the challenge of identifying the exact embeddings to target and the potential for unintended consequences when modifying a model's representations.
Critical Analysis
The paper presents a novel and promising approach for selectively "unlearning" unwanted knowledge from large language models. The key strength of the ECP method is its ability to remove specific biases or factual information without substantially degrading the model's overall capabilities, which is an important goal for developing more responsible and trustworthy AI systems.
However, the paper also acknowledges several limitations and areas for further research. For example, the authors note that identifying the exact embeddings responsible for the unwanted knowledge can be challenging, and that the process of modifying the embeddings could potentially lead to unintended consequences or side effects.
Additionally, the paper does not address the broader philosophical and ethical questions around the concept of "unlearning" in the context of AI systems. While the authors present a technical solution, there may be deeper considerations around the appropriate use of such techniques, the potential risks, and the implications for transparency and accountability in AI development.
Further research could explore these types of questions, as well as investigate the generalizability of the ECP approach to a wider range of LLM architectures and use cases. Nonetheless, this paper represents an important step forward in the ongoing efforts to rethink machine unlearning in large language models and towards safer large language models through machine unlearning.
Conclusion
The paper presents a novel technique called Embedding-Corrupted Prompts (ECP) that aims to selectively "unlearn" unwanted knowledge or biases from large language models (LLMs) without significantly degrading their overall performance. By carefully corrupting the model's internal representations, or embeddings, the ECP approach encourages the LLM to update its parameters in a way that removes the specific information or biases of concern.
The authors demonstrate the effectiveness of their method on various benchmarks, showcasing its potential to help develop more reliable and responsible AI systems that can be tailored to specific needs and societal values. While the paper acknowledges some limitations and areas for further research, it represents an important contribution to the ongoing efforts to rethink machine unlearning in large language models and towards safer large language models through machine unlearning.
As the field of AI continues to grapple with the challenges of deconstructing context learning and understanding prompts via corruption and machine unlearning in large language models, the insights and techniques presented in this paper could contribute to the development of more responsible and trustworthy LLMs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Soft Prompting for Unlearning in Large Language Models
Karuna Bhaila, Minh-Hao Van, Xintao Wu
0
0
The widespread popularity of Large Language Models (LLMs), partly due to their unique ability to perform in-context learning, has also brought to light the importance of ethical and safety considerations when deploying these pre-trained models. In this work, we focus on investigating machine unlearning for LLMs motivated by data protection regulations. In contrast to the growing literature on fine-tuning methods to achieve unlearning, we focus on a comparatively lightweight alternative called soft prompting to realize the unlearning of a subset of training data. With losses designed to enforce forgetting as well as utility preservation, our framework textbf{S}oft textbf{P}rompting for textbf{U}ntextbf{l}earning (SPUL) learns prompt tokens that can be appended to an arbitrary query to induce unlearning of specific examples at inference time without updating LLM parameters. We conduct a rigorous evaluation of the proposed method and our results indicate that SPUL can significantly improve the trade-off between utility and forgetting in the context of text classification with LLMs. We further validate our method using multiple LLMs to highlight the scalability of our framework and provide detailed insights into the choice of hyperparameters and the influence of the size of unlearning data. Our implementation is available at url{https://github.com/karuna-bhaila/llm_unlearning}.
6/19/2024

Deconstructing In-Context Learning: Understanding Prompts via Corruption
Namrata Shivagunde, Vladislav Lialin, Sherin Muckatira, Anna Rumshisky
0
0
The ability of large language models (LLMs) to $``$learn in context$$ based on the provided prompt has led to an explosive growth in their use, culminating in the proliferation of AI assistants such as ChatGPT, Claude, and Bard. These AI assistants are known to be robust to minor prompt modifications, mostly due to alignment techniques that use human feedback. In contrast, the underlying pre-trained LLMs they use as a backbone are known to be brittle in this respect. Building high-quality backbone models remains a core challenge, and a common approach to assessing their quality is to conduct few-shot evaluation. Such evaluation is notorious for being highly sensitive to minor prompt modifications, as well as the choice of specific in-context examples. Prior work has examined how modifying different elements of the prompt can affect model performance. However, these earlier studies tended to concentrate on a limited number of specific prompt attributes and often produced contradictory results. Additionally, previous research either focused on models with fewer than 15 billion parameters or exclusively examined black-box models like GPT-3 or PaLM, making replication challenging. In the present study, we decompose the entire prompt into four components: task description, demonstration inputs, labels, and inline instructions provided for each demonstration. We investigate the effects of structural and semantic corruptions of these elements on model performance. We study models ranging from 1.5B to 70B in size, using ten datasets covering classification and generation tasks. We find that repeating text within the prompt boosts model performance, and bigger models ($geq$30B) are more sensitive to the semantics of the prompt. Finally, we observe that adding task and inline instructions to the demonstrations enhances model performance even when the instructions are semantically corrupted.
5/30/2024

Machine Unlearning in Large Language Models
Saaketh Koundinya Gundavarapu, Shreya Agarwal, Arushi Arora, Chandana Thimmalapura Jagadeeshaiah
0
0
Machine unlearning, a novel area within artificial intelligence, focuses on addressing the challenge of selectively forgetting or reducing undesirable knowledge or behaviors in machine learning models, particularly in the context of large language models (LLMs). This paper introduces a methodology to align LLMs, such as Open Pre-trained Transformer Language Models, with ethical, privacy, and safety standards by leveraging the gradient ascent algorithm for knowledge unlearning. Our approach aims to selectively erase or modify learned information in LLMs, targeting harmful responses and copyrighted content. This paper presents a dual-pronged approach to enhance the ethical and safe behavior of large language models (LLMs) by addressing the issues of harmful responses and copyrighted content. To mitigate harmful responses, we applied gradient ascent on the PKU dataset, achieving a 75% reduction in harmful responses for Open Pre-trained Transformer Language Models (OPT1.3b and OPT2.7b) citet{zhang2022opt} while retaining previous knowledge using the TruthfulQA dataset citet{DBLP:journals/corr/abs-2109-07958}. For handling copyrighted content, we constructed a custom dataset based on the Lord of the Rings corpus and aligned LLMs (OPT1.3b and OPT2.7b) citet{zhang2022opt} through LoRA: Low-Rank Adaptation of Large Language Models citet{DBLP:journals/corr/abs-2106-09685} finetuning. Subsequently, we employed gradient ascent to unlearn the Lord of the Rings content, resulting in a remarkable reduction in the presence of copyrighted material. To maintain a diverse knowledge base, we utilized the Book Corpus dataset. Additionally, we propose a new evaluation technique for assessing the effectiveness of harmful unlearning.
5/27/2024

Rethinking Machine Unlearning for Large Language Models
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Xiaojun Xu, Yuguang Yao, Hang Li, Kush R. Varshney, Mohit Bansal, Sanmi Koyejo, Yang Liu
0
0
We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.
4/8/2024