Sp2360: Sparse-view 360 Scene Reconstruction using Cascaded 2D Diffusion Priors
2405.16517
0
0
Abstract
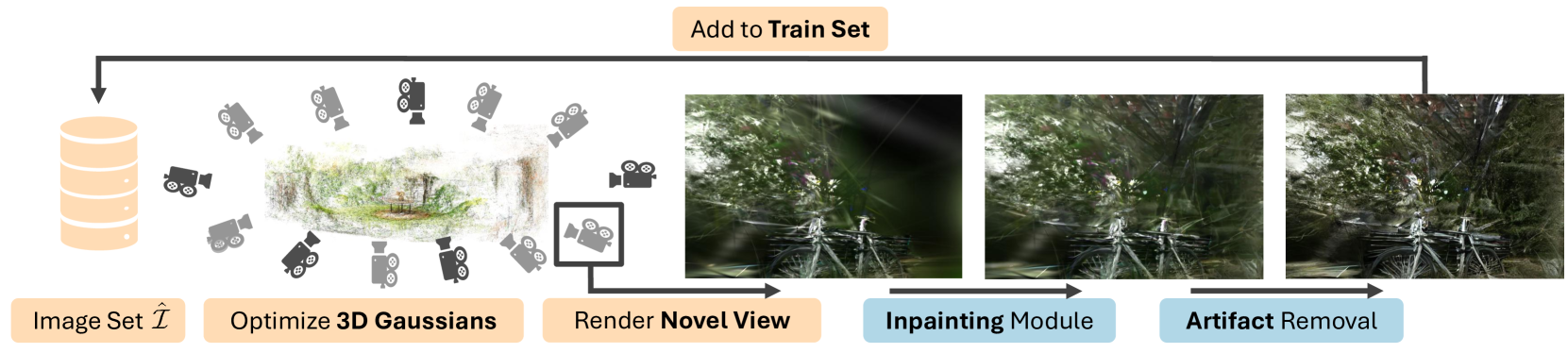
We aim to tackle sparse-view reconstruction of a 360 3D scene using priors from latent diffusion models (LDM). The sparse-view setting is ill-posed and underconstrained, especially for scenes where the camera rotates 360 degrees around a point, as no visual information is available beyond some frontal views focused on the central object(s) of interest. In this work, we show that pretrained 2D diffusion models can strongly improve the reconstruction of a scene with low-cost fine-tuning. Specifically, we present SparseSplat360 (Sp2360), a method that employs a cascade of in-painting and artifact removal models to fill in missing details and clean novel views. Due to superior training and rendering speeds, we use an explicit scene representation in the form of 3D Gaussians over NeRF-based implicit representations. We propose an iterative update strategy to fuse generated pseudo novel views with existing 3D Gaussians fitted to the initial sparse inputs. As a result, we obtain a multi-view consistent scene representation with details coherent with the observed inputs. Our evaluation on the challenging Mip-NeRF360 dataset shows that our proposed 2D to 3D distillation algorithm considerably improves the performance of a regularized version of 3DGS adapted to a sparse-view setting and outperforms existing sparse-view reconstruction methods in 360 scene reconstruction. Qualitatively, our method generates entire 360 scenes from as few as 9 input views, with a high degree of foreground and background detail.
Create account to get full access
Overview
• This paper presents a novel approach for sparse-view 360-degree scene reconstruction using a cascaded 2D diffusion model. • The method aims to reconstruct high-quality 360-degree scenes from a sparse set of input views, overcoming the challenges of limited data and extreme view transformations. • The key innovations include a novel 2D diffusion model architecture and a cascaded training approach that progressively refines the reconstruction.
Plain English Explanation
The paper describes a new way to create 360-degree, panoramic 3D scenes using only a small number of input images. Normally, creating a full 360-degree scene would require taking many pictures from different angles. However, this new method can reconstruct a high-quality 360-degree scene using just a few input images.
The core idea is to use a special type of machine learning model called a "diffusion model." This model learns to gradually transform simple 2D images into more complex 3D scenes. By training the model in stages, it can progressively refine the 360-degree reconstruction, starting from the sparse input images.
This approach has several advantages. It can handle the challenge of extreme view transformations, where the input images may have very different perspectives from the desired 360-degree output. And it can produce high-quality results even with a limited number of input images, which is important when capturing panoramic scenes in the real world.
The paper demonstrates the effectiveness of this sparse-view 360-degree reconstruction technique through various experiments and comparisons to other methods. It shows how this new approach can generate compelling 360-degree scenes from just a handful of input images.
Technical Explanation
The paper introduces a novel sparse-view 360-degree scene reconstruction method using a cascaded 2D diffusion model architecture. Diffusion models are a type of generative AI that can transform simple 2D images into more complex 3D scenes.
The key technical innovations include:
- A specialized 2D diffusion model architecture designed for 360-degree reconstruction
- A cascaded training approach that progressively refines the reconstruction in multiple stages
The 2D diffusion model is trained to gradually transform 2D images into a 360-degree panoramic scene representation. This is done in a cascaded fashion, where earlier stages focus on coarse reconstruction and later stages refine the details.
The cascaded training approach allows the model to effectively handle the extreme view transformations required for 360-degree reconstruction from sparse input views. The early stages learn to capture the overall structure, while the later stages add finer details.
Through extensive experiments, the paper demonstrates that this sparse-view 360-degree reconstruction approach can outperform prior methods in terms of reconstruction quality, even with a limited number of input images. The model is able to generate compelling 360-degree scenes that faithfully capture the original scene structure and details.
Critical Analysis
The paper presents a compelling approach for sparse-view 360-degree scene reconstruction, with several notable strengths. The cascaded 2D diffusion model architecture is a clever way to handle the challenges of extreme view transformations and limited input data. The progressive refinement enables the model to capture both the overall structure and fine details of the 360-degree scenes.
However, the paper also acknowledges some limitations. The method relies on having a diverse training dataset of 360-degree scenes, which may not always be available. There are also computational and memory constraints, as the model needs to process the full 360-degree output during training and inference.
Additionally, while the experiments demonstrate strong reconstruction quality, there may be room for further improvements. The paper does not explore the potential impacts of factors like camera placement, lighting conditions, or scene complexity on the reconstruction performance.
Future research could investigate techniques to further improve the reconstruction quality, such as incorporating additional scene priors or exploring alternative diffusion model architectures. There may also be opportunities to extend the approach to handle dynamic scenes or enable interactive 360-degree scene editing.
Overall, the paper presents a compelling and technically sound approach to the challenging problem of sparse-view 360-degree scene reconstruction. With further refinement and exploration of its capabilities and limitations, this work could have significant implications for applications in virtual reality, autonomous navigation, and immersive media creation.
Conclusion
This paper introduces a novel sparse-view 360-degree scene reconstruction method using a cascaded 2D diffusion model. The key innovations include a specialized diffusion model architecture and a progressive, multi-stage training approach that can effectively handle extreme view transformations and limited input data.
The experimental results demonstrate the method's ability to generate high-quality 360-degree scenes from just a few input images, outperforming prior techniques. This has important implications for applications like virtual reality, autonomous navigation, and immersive media creation, where capturing and reconstructing 360-degree scenes is crucial.
While the paper acknowledges some limitations, such as computational constraints and the need for a diverse training dataset, the overall approach represents a significant advancement in the field of sparse-view 360-degree reconstruction. With further research and refinement, this work could pave the way for more accessible and compelling 360-degree scene capture and visualization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
SparseGS: Real-Time 360{deg} Sparse View Synthesis using Gaussian Splatting
Haolin Xiong, Sairisheek Muttukuru, Rishi Upadhyay, Pradyumna Chari, Achuta Kadambi
0
0
The problem of novel view synthesis has grown significantly in popularity recently with the introduction of Neural Radiance Fields (NeRFs) and other implicit scene representation methods. A recent advance, 3D Gaussian Splatting (3DGS), leverages an explicit representation to achieve real-time rendering with high-quality results. However, 3DGS still requires an abundance of training views to generate a coherent scene representation. In few shot settings, similar to NeRF, 3DGS tends to overfit to training views, causing background collapse and excessive floaters, especially as the number of training views are reduced. We propose a method to enable training coherent 3DGS-based radiance fields of 360-degree scenes from sparse training views. We integrate depth priors with generative and explicit constraints to reduce background collapse, remove floaters, and enhance consistency from unseen viewpoints. Experiments show that our method outperforms base 3DGS by 6.4% in LPIPS and by 12.2% in PSNR, and NeRF-based methods by at least 17.6% in LPIPS on the MipNeRF-360 dataset with substantially less training and inference cost.
5/14/2024
Sampling 3D Gaussian Scenes in Seconds with Latent Diffusion Models
Paul Henderson, Melonie de Almeida, Daniela Ivanova, Titas Anciukeviv{c}ius
0
0
We present a latent diffusion model over 3D scenes, that can be trained using only 2D image data. To achieve this, we first design an autoencoder that maps multi-view images to 3D Gaussian splats, and simultaneously builds a compressed latent representation of these splats. Then, we train a multi-view diffusion model over the latent space to learn an efficient generative model. This pipeline does not require object masks nor depths, and is suitable for complex scenes with arbitrary camera positions. We conduct careful experiments on two large-scale datasets of complex real-world scenes -- MVImgNet and RealEstate10K. We show that our approach enables generating 3D scenes in as little as 0.2 seconds, either from scratch, from a single input view, or from sparse input views. It produces diverse and high-quality results while running an order of magnitude faster than non-latent diffusion models and earlier NeRF-based generative models
6/21/2024

DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting
Shijie Zhou, Zhiwen Fan, Dejia Xu, Haoran Chang, Pradyumna Chari, Tejas Bharadwaj, Suya You, Zhangyang Wang, Achuta Kadambi
0
0
The increasing demand for virtual reality applications has highlighted the significance of crafting immersive 3D assets. We present a text-to-3D 360$^{circ}$ scene generation pipeline that facilitates the creation of comprehensive 360$^{circ}$ scenes for in-the-wild environments in a matter of minutes. Our approach utilizes the generative power of a 2D diffusion model and prompt self-refinement to create a high-quality and globally coherent panoramic image. This image acts as a preliminary flat (2D) scene representation. Subsequently, it is lifted into 3D Gaussians, employing splatting techniques to enable real-time exploration. To produce consistent 3D geometry, our pipeline constructs a spatially coherent structure by aligning the 2D monocular depth into a globally optimized point cloud. This point cloud serves as the initial state for the centroids of 3D Gaussians. In order to address invisible issues inherent in single-view inputs, we impose semantic and geometric constraints on both synthesized and input camera views as regularizations. These guide the optimization of Gaussians, aiding in the reconstruction of unseen regions. In summary, our method offers a globally consistent 3D scene within a 360$^{circ}$ perspective, providing an enhanced immersive experience over existing techniques. Project website at: http://dreamscene360.github.io/
4/11/2024

MVDiff: Scalable and Flexible Multi-View Diffusion for 3D Object Reconstruction from Single-View
Emmanuelle Bourigault, Pauline Bourigault
0
0
Generating consistent multiple views for 3D reconstruction tasks is still a challenge to existing image-to-3D diffusion models. Generally, incorporating 3D representations into diffusion model decrease the model's speed as well as generalizability and quality. This paper proposes a general framework to generate consistent multi-view images from single image or leveraging scene representation transformer and view-conditioned diffusion model. In the model, we introduce epipolar geometry constraints and multi-view attention to enforce 3D consistency. From as few as one image input, our model is able to generate 3D meshes surpassing baselines methods in evaluation metrics, including PSNR, SSIM and LPIPS.
6/14/2024