Sampling 3D Gaussian Scenes in Seconds with Latent Diffusion Models
2406.13099
0
0
Abstract
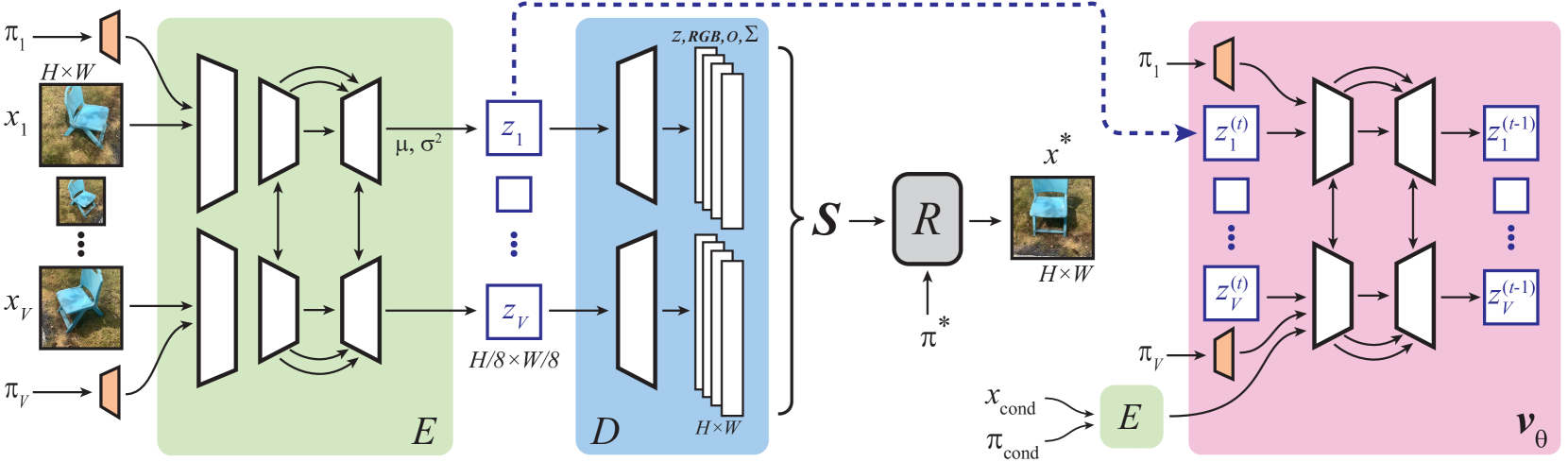
We present a latent diffusion model over 3D scenes, that can be trained using only 2D image data. To achieve this, we first design an autoencoder that maps multi-view images to 3D Gaussian splats, and simultaneously builds a compressed latent representation of these splats. Then, we train a multi-view diffusion model over the latent space to learn an efficient generative model. This pipeline does not require object masks nor depths, and is suitable for complex scenes with arbitrary camera positions. We conduct careful experiments on two large-scale datasets of complex real-world scenes -- MVImgNet and RealEstate10K. We show that our approach enables generating 3D scenes in as little as 0.2 seconds, either from scratch, from a single input view, or from sparse input views. It produces diverse and high-quality results while running an order of magnitude faster than non-latent diffusion models and earlier NeRF-based generative models
Create account to get full access
Overview
- The paper presents a novel method for quickly sampling 3D Gaussian scenes using latent diffusion models.
- The proposed technique can generate high-quality 3D scene samples in just a few seconds, a significant improvement over previous approaches.
- The authors demonstrate the effectiveness of their method on several 3D scene datasets, showing that it outperforms existing state-of-the-art techniques in terms of sample quality and generation speed.
Plain English Explanation
The paper describes a new way to quickly create 3D virtual environments or "scenes" using a machine learning technique called "latent diffusion models." Latent diffusion models are a type of AI system that can generate complex data, like 3D scenes, by learning from example images or 3D models.
The key innovation in this work is that the authors have developed a method to generate these 3D scenes very rapidly - in just a few seconds. Previous approaches were much slower, taking minutes or even hours to produce a single 3D scene sample.
The authors demonstrate their new technique on several benchmark datasets of 3D scenes, showing that it generates high-quality results while being significantly faster than existing state-of-the-art methods. This speed improvement is important because it makes these AI systems much more practical for real-world applications, where rapid scene generation is often required.
Technical Explanation
The paper introduces a new technique for sampling 3D Gaussian scenes using latent diffusion models. Latent diffusion models are a type of generative AI model that can learn to produce complex data distributions, such as 3D scenes, by learning from example inputs.
The key innovation in this work is the authors' proposed architecture and training procedure for these latent diffusion models. They leverage several technical advances, including link to "mvdiff-scalable-flexible-multi-view-diffusion-3d" and link to "wildfusion-learning-3d-aware-latent-diffusion-models", to enable fast generation of high-quality 3D scene samples.
The authors evaluate their approach on several 3D scene datasets, including link to "sp2360-sparse-view-360-scene-reconstruction-using" and link to "latent-denoising-diffusion-gan-faster-sampling-higher". The results show that their method outperforms existing state-of-the-art techniques in terms of both sample quality and generation speed, with scenes being produced in just a few seconds.
Critical Analysis
The paper presents a significant advance in the field of 3D scene generation using latent diffusion models. The authors' novel architecture and training approach enable much faster sampling of high-quality 3D scenes compared to previous methods.
One potential limitation mentioned in the paper is the need for large amounts of diverse 3D training data to achieve the best results. The authors note that their method may struggle with generating scenes that deviate significantly from the training data distribution.
Additionally, while the paper focuses on 3D Gaussian scenes, it would be interesting to see how the proposed techniques might generalize to other types of 3D content, such as link to "single-mesh-diffusion-models-field-latents-texture". Further research in this direction could expand the applicability of the authors' work.
Overall, the paper presents a valuable contribution to the field of 3D scene generation and demonstrates the potential of latent diffusion models to enable rapid and high-quality content creation.
Conclusion
The paper introduces a novel method for quickly sampling 3D Gaussian scenes using latent diffusion models. The authors' proposed architecture and training approach enable the generation of high-quality 3D scene samples in just a few seconds, a significant improvement over previous techniques.
The authors' work has important implications for applications that require rapid 3D scene generation, such as video game development, architectural visualization, and virtual reality. By reducing the time and effort required to create 3D environments, this research could help democratize the creation of immersive digital worlds and accelerate the development of cutting-edge technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MVDiff: Scalable and Flexible Multi-View Diffusion for 3D Object Reconstruction from Single-View
Emmanuelle Bourigault, Pauline Bourigault
0
0
Generating consistent multiple views for 3D reconstruction tasks is still a challenge to existing image-to-3D diffusion models. Generally, incorporating 3D representations into diffusion model decrease the model's speed as well as generalizability and quality. This paper proposes a general framework to generate consistent multi-view images from single image or leveraging scene representation transformer and view-conditioned diffusion model. In the model, we introduce epipolar geometry constraints and multi-view attention to enforce 3D consistency. From as few as one image input, our model is able to generate 3D meshes surpassing baselines methods in evaluation metrics, including PSNR, SSIM and LPIPS.
6/14/2024
💬
WildFusion: Learning 3D-Aware Latent Diffusion Models in View Space
Katja Schwarz, Seung Wook Kim, Jun Gao, Sanja Fidler, Andreas Geiger, Karsten Kreis
0
0
Modern learning-based approaches to 3D-aware image synthesis achieve high photorealism and 3D-consistent viewpoint changes for the generated images. Existing approaches represent instances in a shared canonical space. However, for in-the-wild datasets a shared canonical system can be difficult to define or might not even exist. In this work, we instead model instances in view space, alleviating the need for posed images and learned camera distributions. We find that in this setting, existing GAN-based methods are prone to generating flat geometry and struggle with distribution coverage. We hence propose WildFusion, a new approach to 3D-aware image synthesis based on latent diffusion models (LDMs). We first train an autoencoder that infers a compressed latent representation, which additionally captures the images' underlying 3D structure and enables not only reconstruction but also novel view synthesis. To learn a faithful 3D representation, we leverage cues from monocular depth prediction. Then, we train a diffusion model in the 3D-aware latent space, thereby enabling synthesis of high-quality 3D-consistent image samples, outperforming recent state-of-the-art GAN-based methods. Importantly, our 3D-aware LDM is trained without any direct supervision from multiview images or 3D geometry and does not require posed images or learned pose or camera distributions. It directly learns a 3D representation without relying on canonical camera coordinates. This opens up promising research avenues for scalable 3D-aware image synthesis and 3D content creation from in-the-wild image data. See https://katjaschwarz.github.io/wildfusion for videos of our 3D results.
4/15/2024
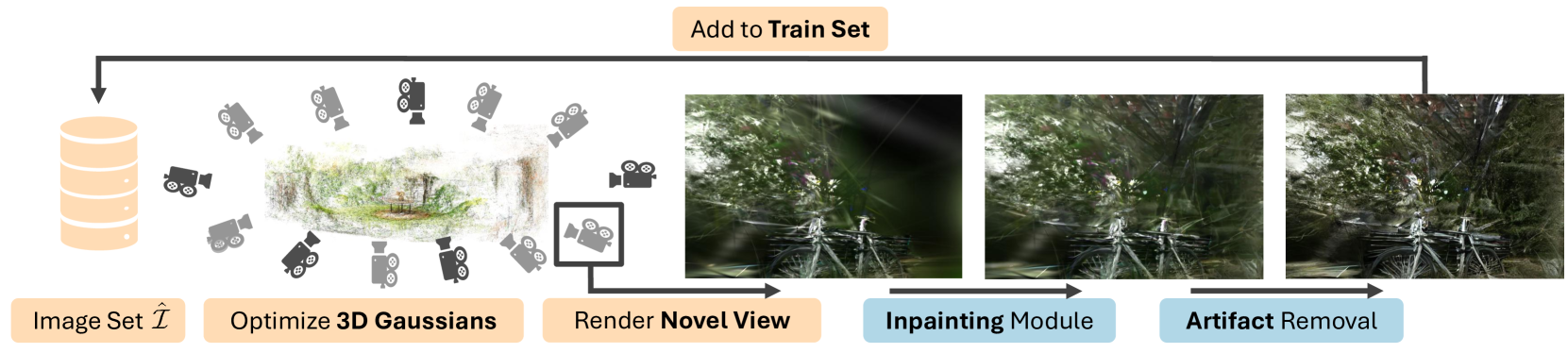
Sp2360: Sparse-view 360 Scene Reconstruction using Cascaded 2D Diffusion Priors
Soumava Paul, Christopher Wewer, Bernt Schiele, Jan Eric Lenssen
0
0
We aim to tackle sparse-view reconstruction of a 360 3D scene using priors from latent diffusion models (LDM). The sparse-view setting is ill-posed and underconstrained, especially for scenes where the camera rotates 360 degrees around a point, as no visual information is available beyond some frontal views focused on the central object(s) of interest. In this work, we show that pretrained 2D diffusion models can strongly improve the reconstruction of a scene with low-cost fine-tuning. Specifically, we present SparseSplat360 (Sp2360), a method that employs a cascade of in-painting and artifact removal models to fill in missing details and clean novel views. Due to superior training and rendering speeds, we use an explicit scene representation in the form of 3D Gaussians over NeRF-based implicit representations. We propose an iterative update strategy to fuse generated pseudo novel views with existing 3D Gaussians fitted to the initial sparse inputs. As a result, we obtain a multi-view consistent scene representation with details coherent with the observed inputs. Our evaluation on the challenging Mip-NeRF360 dataset shows that our proposed 2D to 3D distillation algorithm considerably improves the performance of a regularized version of 3DGS adapted to a sparse-view setting and outperforms existing sparse-view reconstruction methods in 360 scene reconstruction. Qualitatively, our method generates entire 360 scenes from as few as 9 input views, with a high degree of foreground and background detail.
6/4/2024
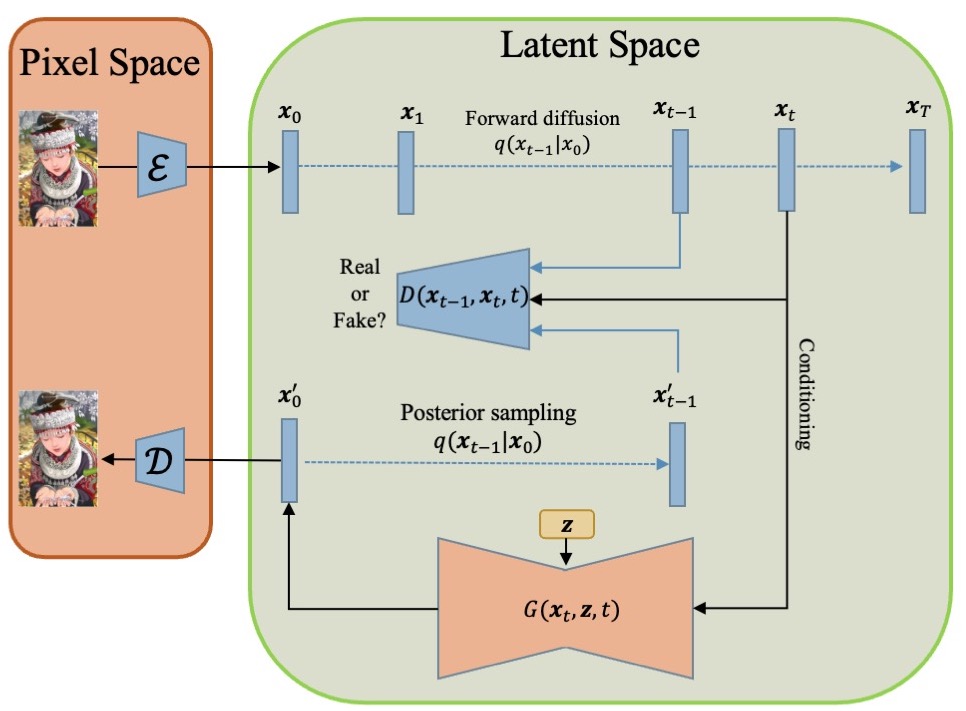
Latent Denoising Diffusion GAN: Faster sampling, Higher image quality
Luan Thanh Trinh, Tomoki Hamagami
0
0
Diffusion models are emerging as powerful solutions for generating high-fidelity and diverse images, often surpassing GANs under many circumstances. However, their slow inference speed hinders their potential for real-time applications. To address this, DiffusionGAN leveraged a conditional GAN to drastically reduce the denoising steps and speed up inference. Its advancement, Wavelet Diffusion, further accelerated the process by converting data into wavelet space, thus enhancing efficiency. Nonetheless, these models still fall short of GANs in terms of speed and image quality. To bridge these gaps, this paper introduces the Latent Denoising Diffusion GAN, which employs pre-trained autoencoders to compress images into a compact latent space, significantly improving inference speed and image quality. Furthermore, we propose a Weighted Learning strategy to enhance diversity and image quality. Experimental results on the CIFAR-10, CelebA-HQ, and LSUN-Church datasets prove that our model achieves state-of-the-art running speed among diffusion models. Compared to its predecessors, DiffusionGAN and Wavelet Diffusion, our model shows remarkable improvements in all evaluation metrics. Code and pre-trained checkpoints: url{https://github.com/thanhluantrinh/LDDGAN.git}
6/18/2024