SparseDM: Toward Sparse Efficient Diffusion Models
2404.10445
0
0
Abstract
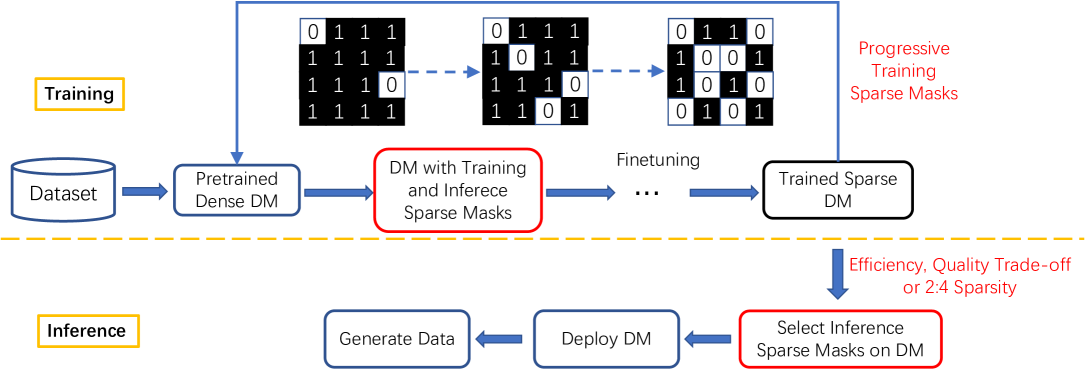
Diffusion models have been extensively used in data generation tasks and are recognized as one of the best generative models. However, their time-consuming deployment, long inference time, and requirements on large memory limit their application on mobile devices. In this paper, we propose a method based on the improved Straight-Through Estimator to improve the deployment efficiency of diffusion models. Specifically, we add sparse masks to the Convolution and Linear layers in a pre-trained diffusion model, then use design progressive sparsity for model training in the fine-tuning stage, and switch the inference mask on and off, which supports a flexible choice of sparsity during inference according to the FID and MACs requirements. Experiments on four datasets conducted on a state-of-the-art Transformer-based diffusion model demonstrate that our method reduces MACs by $50%$ while increasing FID by only 1.5 on average. Under other MACs conditions, the FID is also lower than 1$sim$137 compared to other methods.
Create account to get full access
Overview
- Introduces a new approach called "SparseDM" for creating efficient diffusion models
- Focuses on reducing the memory and computational requirements of diffusion models while maintaining performance
- Proposes a sparse finetuning method to prune model parameters and speed up inference
Plain English Explanation
The paper presents a new technique called "SparseDM" that aims to make diffusion models more efficient and practical to use. Diffusion models are a type of machine learning model that can generate high-quality images, but they tend to be computationally expensive and require a lot of memory.
The researchers behind SparseDM [1] wanted to find a way to reduce the memory and computational requirements of diffusion models without sacrificing their impressive image generation capabilities. Their key insight was to use a "sparse finetuning" technique to prune away unnecessary model parameters after the initial training process.
This sparse finetuning approach allows the model to maintain its image generation performance while becoming much more efficient in terms of memory usage and inference speed. The authors show that SparseDM can achieve comparable results to standard diffusion models while being up to 10 times faster and using 5 times less memory.
Technical Explanation
The paper starts by formulating the problem of efficient diffusion model design as an optimization problem, where the goal is to find a model architecture that can generate high-quality images while minimizing memory and computational requirements.
The core of the SparseDM approach is a sparse finetuning technique [2]. After training a standard diffusion model, the researchers apply a pruning algorithm to remove a large portion of the model's parameters without significantly degrading performance. This sparse finetuning process results in a more compact and efficient model that can run much faster and with less memory.
The authors evaluate SparseDM on several image generation benchmarks, including [3] and [4], and show that it can achieve comparable or better performance than the original diffusion models while being up to 10 times faster and using 5 times less memory.
Critical Analysis
The paper presents a promising approach for improving the efficiency of diffusion models, which is an important problem given the high computational and memory requirements of these models. The sparse finetuning technique seems like a sensible way to prune away unnecessary parameters without sacrificing too much performance.
However, the authors do not provide a detailed analysis of the tradeoffs involved in the sparsity-performance tradeoff. It would be helpful to see more experiments exploring the relationship between the degree of sparsity and the resulting image quality and generation speed.
Additionally, the paper does not address the potential implications of using a sparse model, such as the impact on model interpretability or the ability to fine-tune the model on new tasks. These are important considerations that could be explored in future research.
Conclusion
Overall, the SparseDM approach presented in this paper represents an important step towards making diffusion models more practical and accessible for real-world applications. By leveraging sparse finetuning, the researchers have shown how to create efficient diffusion models that maintain high performance while significantly reducing memory and computational requirements.
As diffusion models continue to grow in popularity and capabilities, techniques like SparseDM will be crucial for enabling their widespread adoption and deployment, especially in resource-constrained environments. The ideas presented in this paper could also inspire future research into other methods for improving the efficiency of large-scale machine learning models.
[1] https://aimodels.fyi/papers/arxiv/masked-diffusion-as-self-supervised-representation-learner [2] https://aimodels.fyi/papers/arxiv/missing-u-efficient-diffusion-models [3] https://aimodels.fyi/papers/arxiv/finediffusion-scaling-up-diffusion-models-fine-grained [4] https://aimodels.fyi/papers/arxiv/score-identity-distillation-exponentially-fast-distillation-pretrained
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
Sparse Training of Discrete Diffusion Models for Graph Generation
Yiming Qin, Clement Vignac, Pascal Frossard
0
0
Generative graph models struggle to scale due to the need to predict the existence or type of edges between all node pairs. To address the resulting quadratic complexity, existing scalable models often impose restrictive assumptions such as a cluster structure within graphs, thus limiting their applicability. To address this, we introduce SparseDiff, a novel diffusion model based on the observation that almost all large graphs are sparse. By selecting a subset of edges, SparseDiff effectively leverages sparse graph representations both during the noising process and within the denoising network, which ensures that space complexity scales linearly with the number of chosen edges. During inference, SparseDiff progressively fills the adjacency matrix with the selected subsets of edges, mirroring the training process. Our model demonstrates state-of-the-art performance across multiple metrics on both small and large datasets, confirming its effectiveness and robustness across varying graph sizes. It also ensures faster convergence, particularly on larger graphs, achieving a fourfold speedup on the large Ego dataset compared to dense models, thereby paving the way for broader applications.
5/24/2024

Plug-and-Play Diffusion Distillation
Yi-Ting Hsiao, Siavash Khodadadeh, Kevin Duarte, Wei-An Lin, Hui Qu, Mingi Kwon, Ratheesh Kalarot
0
0
Diffusion models have shown tremendous results in image generation. However, due to the iterative nature of the diffusion process and its reliance on classifier-free guidance, inference times are slow. In this paper, we propose a new distillation approach for guided diffusion models in which an external lightweight guide model is trained while the original text-to-image model remains frozen. We show that our method reduces the inference computation of classifier-free guided latent-space diffusion models by almost half, and only requires 1% trainable parameters of the base model. Furthermore, once trained, our guide model can be applied to various fine-tuned, domain-specific versions of the base diffusion model without the need for additional training: this plug-and-play functionality drastically improves inference computation while maintaining the visual fidelity of generated images. Empirically, we show that our approach is able to produce visually appealing results and achieve a comparable FID score to the teacher with as few as 8 to 16 steps.
6/17/2024
➖
Masked Diffusion as Self-supervised Representation Learner
Zixuan Pan, Jianxu Chen, Yiyu Shi
0
0
Denoising diffusion probabilistic models have recently demonstrated state-of-the-art generative performance and have been used as strong pixel-level representation learners. This paper decomposes the interrelation between the generative capability and representation learning ability inherent in diffusion models. We present the masked diffusion model (MDM), a scalable self-supervised representation learner for semantic segmentation, substituting the conventional additive Gaussian noise of traditional diffusion with a masking mechanism. Our proposed approach convincingly surpasses prior benchmarks, demonstrating remarkable advancements in both medical and natural image semantic segmentation tasks, particularly in few-shot scenarios.
4/16/2024
Simplified and Generalized Masked Diffusion for Discrete Data
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, Michalis K. Titsias
0
0
Masked (or absorbing) diffusion is actively explored as an alternative to autoregressive models for generative modeling of discrete data. However, existing work in this area has been hindered by unnecessarily complex model formulations and unclear relationships between different perspectives, leading to suboptimal parameterization, training objectives, and ad hoc adjustments to counteract these issues. In this work, we aim to provide a simple and general framework that unlocks the full potential of masked diffusion models. We show that the continuous-time variational objective of masked diffusion models is a simple weighted integral of cross-entropy losses. Our framework also enables training generalized masked diffusion models with state-dependent masking schedules. When evaluated by perplexity, our models trained on OpenWebText surpass prior diffusion language models at GPT-2 scale and demonstrate superior performance on 4 out of 5 zero-shot language modeling tasks. Furthermore, our models vastly outperform previous discrete diffusion models on pixel-level image modeling, achieving 2.78~(CIFAR-10) and 3.42 (ImageNet 64$times$64) bits per dimension that are comparable or better than autoregressive models of similar sizes.
6/7/2024