Masked Diffusion as Self-supervised Representation Learner
2308.05695
0
0
➖
Abstract
Denoising diffusion probabilistic models have recently demonstrated state-of-the-art generative performance and have been used as strong pixel-level representation learners. This paper decomposes the interrelation between the generative capability and representation learning ability inherent in diffusion models. We present the masked diffusion model (MDM), a scalable self-supervised representation learner for semantic segmentation, substituting the conventional additive Gaussian noise of traditional diffusion with a masking mechanism. Our proposed approach convincingly surpasses prior benchmarks, demonstrating remarkable advancements in both medical and natural image semantic segmentation tasks, particularly in few-shot scenarios.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Denoising diffusion probabilistic models have shown impressive generative performance and ability to learn strong pixel-level representations.
- This paper explores the connection between the generative and representation learning capabilities of diffusion models.
- The authors present the Masked Diffusion Model (MDM), a scalable self-supervised representation learner for semantic segmentation that uses a masking mechanism instead of additive Gaussian noise.
- The proposed approach outperforms prior benchmarks in both medical and natural image semantic segmentation tasks, particularly in few-shot scenarios.
Plain English Explanation
Denoising diffusion probabilistic models are a type of machine learning algorithm that have recently demonstrated excellent results in generating new images and learning useful representations from image data. This paper dives into the relationship between these two capabilities - the ability to generate new images and the ability to learn meaningful representations from existing images.
The researchers introduce a new model called the Masked Diffusion Model (MDM), which uses a masking mechanism instead of adding random noise to the input images. This allows the model to learn powerful representations of the image data in a self-supervised way, without needing labeled data. The key innovation is that the model has to learn to "fill in" the missing parts of the image, rather than just trying to remove noise.
The researchers show that this new approach significantly outperforms previous methods on benchmark tasks in medical and natural image segmentation, especially when there is only a small amount of labeled training data available. This is an important result, as being able to learn strong representations from limited data is crucial for many real-world applications.
Overall, this paper provides valuable insights into the interplay between generative modeling and representation learning in diffusion models, and demonstrates the benefits of the Masked Diffusion Model approach for practical computer vision tasks.
Technical Explanation
The paper decomposes the relationship between the generative and representation learning capabilities inherent in denoising diffusion probabilistic models (DDPMs). The authors present the Masked Diffusion Model (MDM), a scalable self-supervised representation learner for semantic segmentation that replaces the traditional additive Gaussian noise with a masking mechanism.
In the MDM approach, the model is trained to predict the missing (masked) regions of the input image, rather than just trying to remove noise as in a standard DDPM. This forces the model to learn rich, semantic representations of the image content in order to accurately fill in the missing parts.
The researchers evaluate the MDM on a range of medical and natural image semantic segmentation benchmarks, including challenging few-shot scenarios. The results demonstrate significant improvements over previous state-of-the-art methods, particularly in the few-shot setting. This highlights the ability of the Masked Diffusion Model to learn powerful representations from limited data.
Additionally, the paper provides insights into the tradeoffs between the generative and representation learning capabilities of DDPMs. The authors discuss how the masking mechanism in MDM can help balance these two aspects, leading to enhanced performance on downstream tasks compared to standard diffusion models.
Critical Analysis
The paper provides a compelling analysis of the interplay between generative modeling and representation learning in the context of denoising diffusion probabilistic models. The introduction of the Masked Diffusion Model is a novel and promising approach that demonstrates significant practical benefits, especially in few-shot learning scenarios.
One potential limitation of the research is that the experiments are primarily focused on image segmentation tasks. It would be interesting to see how the MDM approach performs on a wider range of computer vision and machine learning problems, such as image classification or medical image analysis. Additionally, the paper could have provided more detailed analysis of the learned representations and how they compare to those obtained from other self-supervised methods.
Overall, this research represents an important contribution to the understanding and advancement of denoising diffusion probabilistic models. The Masked Diffusion Model is a promising approach that warrants further exploration and development.
Conclusion
This paper offers valuable insights into the relationship between the generative and representation learning capabilities of denoising diffusion probabilistic models. The proposed Masked Diffusion Model demonstrates remarkable performance improvements on semantic segmentation tasks, particularly in few-shot scenarios, and provides a scalable self-supervised representation learning framework.
The research highlights the potential of diffusion models to serve as strong pixel-level representation learners, going beyond their impressive generative abilities. The insights gained from this work can inform the continued development and application of denoising diffusion probabilistic models across a wide range of machine learning and computer vision problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
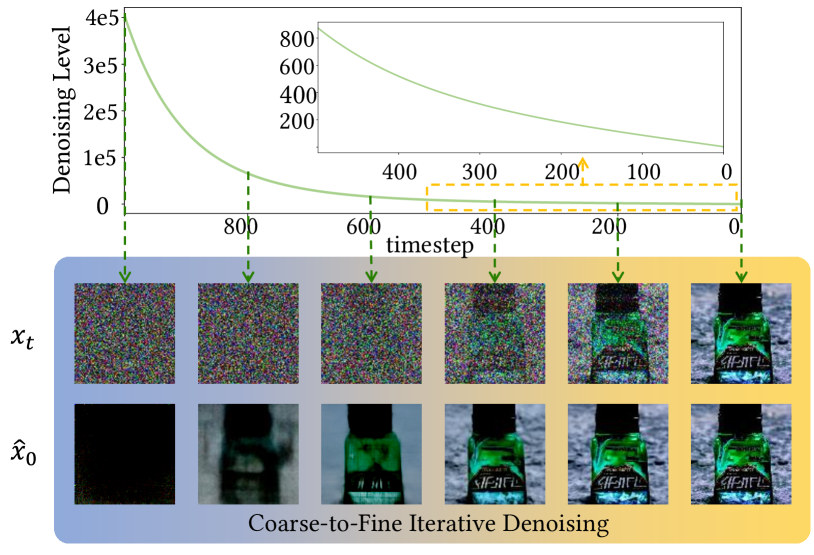
Stimulating the Diffusion Model for Image Denoising via Adaptive Embedding and Ensembling
Tong Li, Hansen Feng, Lizhi Wang, Zhiwei Xiong, Hua Huang
0
0
Image denoising is a fundamental problem in computational photography, where achieving high perception with low distortion is highly demanding. Current methods either struggle with perceptual quality or suffer from significant distortion. Recently, the emerging diffusion model has achieved state-of-the-art performance in various tasks and demonstrates great potential for image denoising. However, stimulating diffusion models for image denoising is not straightforward and requires solving several critical problems. For one thing, the input inconsistency hinders the connection between diffusion models and image denoising. For another, the content inconsistency between the generated image and the desired denoised image introduces distortion. To tackle these problems, we present a novel strategy called the Diffusion Model for Image Denoising (DMID) by understanding and rethinking the diffusion model from a denoising perspective. Our DMID strategy includes an adaptive embedding method that embeds the noisy image into a pre-trained unconditional diffusion model and an adaptive ensembling method that reduces distortion in the denoised image. Our DMID strategy achieves state-of-the-art performance on both distortion-based and perception-based metrics, for both Gaussian and real-world image denoising.The code is available at https://github.com/Li-Tong-621/DMID.
4/16/2024
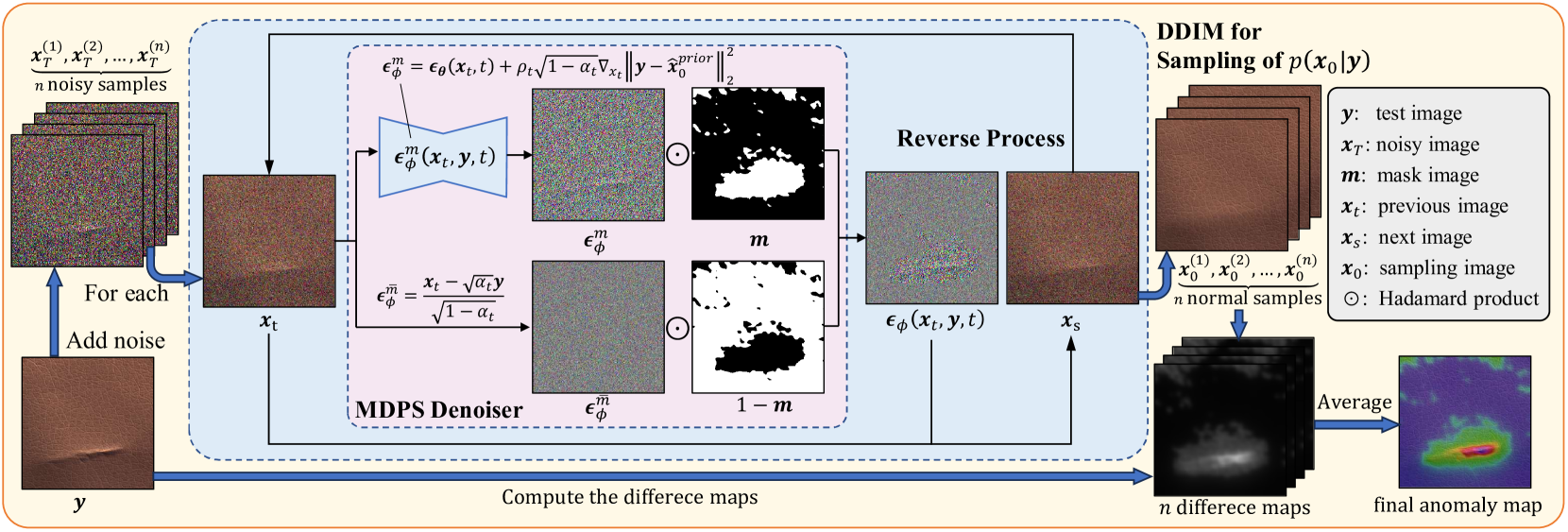
Unsupervised Anomaly Detection via Masked Diffusion Posterior Sampling
Di Wu, Shicai Fan, Xue Zhou, Li Yu, Yuzhong Deng, Jianxiao Zou, Baihong Lin
0
0
Reconstruction-based methods have been commonly used for unsupervised anomaly detection, in which a normal image is reconstructed and compared with the given test image to detect and locate anomalies. Recently, diffusion models have shown promising applications for anomaly detection due to their powerful generative ability. However, these models lack strict mathematical support for normal image reconstruction and unexpectedly suffer from low reconstruction quality. To address these issues, this paper proposes a novel and highly-interpretable method named Masked Diffusion Posterior Sampling (MDPS). In MDPS, the problem of normal image reconstruction is mathematically modeled as multiple diffusion posterior sampling for normal images based on the devised masked noisy observation model and the diffusion-based normal image prior under Bayesian framework. Using a metric designed from pixel-level and perceptual-level perspectives, MDPS can effectively compute the difference map between each normal posterior sample and the given test image. Anomaly scores are obtained by averaging all difference maps for multiple posterior samples. Exhaustive experiments on MVTec and BTAD datasets demonstrate that MDPS can achieve state-of-the-art performance in normal image reconstruction quality as well as anomaly detection and localization.
4/30/2024
🖼️
SAR Image Synthesis with Diffusion Models
Denisa Qosja, Simon Wagner, Daniel O'Hagan
0
0
In recent years, diffusion models (DMs) have become a popular method for generating synthetic data. By achieving samples of higher quality, they quickly became superior to generative adversarial networks (GANs) and the current state-of-the-art method in generative modeling. However, their potential has not yet been exploited in radar, where the lack of available training data is a long-standing problem. In this work, a specific type of DMs, namely denoising diffusion probabilistic model (DDPM) is adapted to the SAR domain. We investigate the network choice and specific diffusion parameters for conditional and unconditional SAR image generation. In our experiments, we show that DDPM qualitatively and quantitatively outperforms state-of-the-art GAN-based methods for SAR image generation. Finally, we show that DDPM profits from pretraining on largescale clutter data, generating SAR images of even higher quality.
5/14/2024
🏋️
Exploring Limits of Diffusion-Synthetic Training with Weakly Supervised Semantic Segmentation
Ryota Yoshihashi, Yuya Otsuka, Kenji Doi, Tomohiro Tanaka, Hirokatsu Kataoka
0
0
The advance of generative models for images has inspired various training techniques for image recognition utilizing synthetic images. In semantic segmentation, one promising approach is extracting pseudo-masks from attention maps in text-to-image diffusion models, which enables real-image-and-annotation-free training. However, the pioneering training method using the diffusion-synthetic images and pseudo-masks, i.e., DiffuMask has limitations in terms of mask quality, scalability, and ranges of applicable domains. To overcome these limitations, this work introduces three techniques for diffusion-synthetic semantic segmentation training. First, reliability-aware robust training, originally used in weakly supervised learning, helps segmentation with insufficient synthetic mask quality. %Second, large-scale pretraining of whole segmentation models, not only backbones, on synthetic ImageNet-1k-class images with pixel-labels benefits downstream segmentation tasks. Second, we introduce prompt augmentation, data augmentation to the prompt text set to scale up and diversify training images with a limited text resources. Finally, LoRA-based adaptation of Stable Diffusion enables the transfer to a distant domain, e.g., auto-driving images. Experiments in PASCAL VOC, ImageNet-S, and Cityscapes show that our method effectively closes gap between real and synthetic training in semantic segmentation.
4/16/2024