Spatial-Temporal Multi-level Association for Video Object Segmentation

0

Sign in to get full access
Overview
- This paper proposes a novel approach to video object segmentation that leverages spatial-temporal multi-level association.
- The method aims to efficiently capture both spatial and temporal information to improve the accuracy and robustness of video object segmentation.
- Key innovations include a multi-level feature extraction process and an association strategy that integrates spatial and temporal cues.
Plain English Explanation
Video object segmentation is the task of identifying and separating individual objects within a video sequence. This is an important capability for applications like autonomous driving, video analysis, and video editing.
The proposed approach in this paper tries to solve video object segmentation more effectively by taking advantage of both the spatial (location) and temporal (motion) information in the video. It does this through a multi-level feature extraction process that captures details at different scales, and an association strategy that links objects across frames based on their spatial and temporal characteristics.
This allows the system to better handle challenges like occlusions, appearance changes, and [complex motions within the video. The key idea is to leverage both local and global information to make more robust segmentation decisions.
Technical Explanation
The paper introduces a spatial-temporal multi-level association framework for video object segmentation. The core components are:
-
Multi-Level Feature Extraction: The method extracts features at multiple scales, from local pixel-level details to higher-level semantic information. This provides a richer representation of the objects and their context.
-
Spatial-Temporal Association: An association module links objects across frames by considering both their spatial locations and their temporal motion patterns. This allows the system to track objects more accurately, even in the presence of occlusions or appearance changes.
-
Iterative Refinement: The system performs multiple rounds of feature extraction and association to progressively improve the segmentation quality. This iterative process helps capture complex spatio-temporal relationships.
The authors evaluate their approach on several benchmark video segmentation datasets and demonstrate significant improvements over existing methods, particularly in challenging scenarios with fast-moving objects or occlusions.
Critical Analysis
The paper presents a well-designed and comprehensive solution for video object segmentation. The key strengths are the multi-level feature extraction and the integration of spatial-temporal association, which allows the system to robustly handle the complex dynamics of real-world video sequences.
However, the authors acknowledge some limitations of their approach. For example, the iterative refinement process can be computationally expensive, which may limit its applicability in real-time systems. Additionally, the method relies on accurate initial object proposals, and its performance may degrade if these are not reliable.
Further research could explore ways to streamline the computation, perhaps by selectively applying the multi-level and iterative components only where needed. Integrating the method with advanced object detection or motion estimation techniques could also enhance its robustness and efficiency.
Conclusion
The proposed spatial-temporal multi-level association framework represents a significant advancement in video object segmentation. By effectively leveraging both spatial and temporal information, the method can handle challenging scenarios that pose difficulties for previous approaches.
The innovations in feature extraction and object association demonstrated in this paper could have broader implications for video analysis, video editing, and other video-based applications. As the field of computer vision continues to advance, techniques like those presented in this work will play an increasingly important role in enabling more robust and intelligent video understanding systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Spatial-Temporal Multi-level Association for Video Object Segmentation
Deshui Miao, Xin Li, Zhenyu He, Huchuan Lu, Ming-Hsuan Yang
Existing semi-supervised video object segmentation methods either focus on temporal feature matching or spatial-temporal feature modeling. However, they do not address the issues of sufficient target interaction and efficient parallel processing simultaneously, thereby constraining the learning of dynamic, target-aware features. To tackle these limitations, this paper proposes a spatial-temporal multi-level association framework, which jointly associates reference frame, test frame, and object features to achieve sufficient interaction and parallel target ID association with a spatial-temporal memory bank for efficient video object segmentation. Specifically, we construct a spatial-temporal multi-level feature association module to learn better target-aware features, which formulates feature extraction and interaction as the efficient operations of object self-attention, reference object enhancement, and test reference correlation. In addition, we propose a spatial-temporal memory to assist feature association and temporal ID assignment and correlation. We evaluate the proposed method by conducting extensive experiments on numerous video object segmentation datasets, including DAVIS 2016/2017 val, DAVIS 2017 test-dev, and YouTube-VOS 2018/2019 val. The favorable performance against the state-of-the-art methods demonstrates the effectiveness of our approach. All source code and trained models will be made publicly available.
Read more4/10/2024

0
Learning Spatial-Semantic Features for Robust Video Object Segmentation
Xin Li, Deshui Miao, Zhenyu He, Yaowei Wang, Huchuan Lu, Ming-Hsuan Yang
Tracking and segmenting multiple similar objects with complex or separate parts in long-term videos is inherently challenging due to the ambiguity of target parts and identity confusion caused by occlusion, background clutter, and long-term variations. In this paper, we propose a robust video object segmentation framework equipped with spatial-semantic features and discriminative object queries to address the above issues. Specifically, we construct a spatial-semantic network comprising a semantic embedding block and spatial dependencies modeling block to associate the pretrained ViT features with global semantic features and local spatial features, providing a comprehensive target representation. In addition, we develop a masked cross-attention module to generate object queries that focus on the most discriminative parts of target objects during query propagation, alleviating noise accumulation and ensuring effective long-term query propagation. The experimental results show that the proposed method set a new state-of-the-art performance on multiple datasets, including the DAVIS2017 test (89.1%), YoutubeVOS 2019 (88.5%), MOSE (75.1%), LVOS test (73.0%), and LVOS val (75.1%), which demonstrate the effectiveness and generalization capacity of the proposed method. We will make all source code and trained models publicly available.
Read more7/11/2024
0
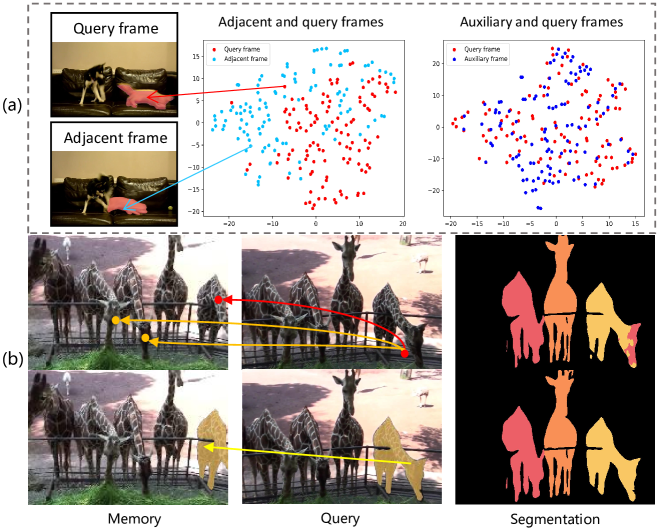
Space-time Reinforcement Network for Video Object Segmentation
Yadang Chen, Wentao Zhu, Zhi-Xin Yang, Enhua Wu
Recently, video object segmentation (VOS) networks typically use memory-based methods: for each query frame, the mask is predicted by space-time matching to memory frames. Despite these methods having superior performance, they suffer from two issues: 1) Challenging data can destroy the space-time coherence between adjacent video frames. 2) Pixel-level matching will lead to undesired mismatching caused by the noises or distractors. To address the aforementioned issues, we first propose to generate an auxiliary frame between adjacent frames, serving as an implicit short-temporal reference for the query one. Next, we learn a prototype for each video object and prototype-level matching can be implemented between the query and memory. The experiment demonstrated that our network outperforms the state-of-the-art method on the DAVIS 2017, achieving a J&F score of 86.4%, and attains a competitive result 85.0% on YouTube VOS 2018. In addition, our network exhibits a high inference speed of 32+ FPS.
Read more5/8/2024
0
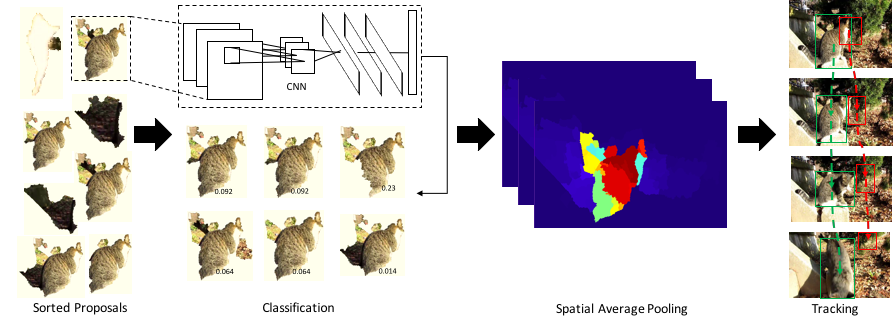
Submodular video object proposal selection for semantic object segmentation
Tinghuai Wang
Learning a data-driven spatio-temporal semantic representation of the objects is the key to coherent and consistent labelling in video. This paper proposes to achieve semantic video object segmentation by learning a data-driven representation which captures the synergy of multiple instances from continuous frames. To prune the noisy detections, we exploit the rich information among multiple instances and select the discriminative and representative subset. This selection process is formulated as a facility location problem solved by maximising a submodular function. Our method retrieves the longer term contextual dependencies which underpins a robust semantic video object segmentation algorithm. We present extensive experiments on a challenging dataset that demonstrate the superior performance of our approach compared with the state-of-the-art methods.
Read more7/9/2024