Spectra: A Comprehensive Study of Ternary, Quantized, and FP16 Language Models

1
💬
Sign in to get full access
Overview
• Post-training quantization has been the leading method for addressing memory-related bottlenecks in large language model (LLM) inference, but it suffers from significant performance degradation below 4-bit precision.
• An alternative approach involves training compressed models directly at a low bitwidth, such as binary or ternary models, but their performance, training dynamics, and scaling trends are not well understood.
• To address this, the researchers have trained and released the Spectra LLM suite, consisting of 54 language models ranging from 99M to 3.9B parameters, trained on 300B tokens.
• Spectra includes FloatLMs, QuantLMs (3, 4, 6, and 8 bits), and TriLMs - their improved architecture for ternary language modeling.
Plain English Explanation
The researchers have been working on ways to make large language models (LLMs) more efficient and accessible. One of the main challenges is that these models require a lot of memory, which can be a problem for running them on devices with limited resources, like smartphones or edge devices.
One approach that has been explored is "post-training quantization," which involves taking a trained model and compressing it down to a lower number of bits (like 4 bits instead of the standard 32 bits). This can save a lot of memory, but the performance of the model often degrades significantly when you go below 4 bits.
An alternative approach is to train the model directly at a low bitwidth, like using binary or ternary weights (where the weights can only be 0, 1, or -1). This could potentially be more efficient, but the performance, training process, and scaling of these types of models haven't been well-studied.
To better understand this, the researchers have created the Spectra LLM suite - a collection of 54 different language models ranging from 99 million to 3.9 billion parameters, all trained on a large dataset of 300 billion tokens. This suite includes the standard "FloatLMs" (using 32-bit floating-point weights), the "QuantLMs" (with 3, 4, 6, or 8-bit quantization), and their new "TriLMs" - an improved architecture for ternary language models.
By releasing this suite of models, the researchers hope to provide a valuable resource for the research community to better understand the tradeoffs and performance characteristics of these different approaches to model compression and efficiency.
Technical Explanation
The Spectra LLM suite includes several types of language models:
-
FloatLMs: These are the standard language models using 32-bit floating-point weights.
-
QuantLMs: These are models that have undergone post-training quantization, compressed down to 3, 4, 6, or 8 bits. This is a common technique for reducing the memory footprint of LLMs, but it can lead to significant performance degradation, especially at lower bit-widths.
-
TriLMs: This is the researchers' own improved architecture for ternary language models, where the weights are restricted to -1, 0, or 1. Ternary models have the potential to be more memory-efficient than standard models, but their performance has historically lagged behind.
The researchers trained 54 different models in the Spectra suite, ranging from 99 million to 3.9 billion parameters, all on the same 300 billion token dataset. This allows for a comprehensive comparison of the different model types and sizes.
Some key findings:
- The TriLM 3.9B model is (in terms of total bits) smaller than the half-precision FloatLM 830M model, but it matches the performance of the much larger FloatLM 3.9B on some benchmark tasks, like commonsense reasoning and knowledge.
- However, the TriLM 3.9B model also inherits some of the undesirable traits of the larger FloatLM 3.9B, such as toxicity and stereotyping.
- The TriLM models generally lag behind the FloatLMs in terms of perplexity on validation sets and web-based corpora, but perform better on less noisy datasets like Lambada and PennTreeBank.
To further aid research in this area, the researchers are also releasing over 500 intermediate training checkpoints for the Spectra suite models, which can be accessed at https://github.com/NolanoOrg/SpectraSuite.
Critical Analysis
The Spectra LLM suite provides a valuable resource for researchers to explore the tradeoffs and performance characteristics of different approaches to model compression and efficiency, including post-training quantization, ternary models, and standard floating-point models.
The researchers' findings on the TriLM models are particularly interesting, as they show that ternary models can potentially match the performance of much larger floating-point models on certain tasks, while being significantly more memory-efficient. However, the TriLM models also seem to inherit some of the undesirable traits of the larger models, such as toxicity and stereotyping.
One limitation of this research is that it only considers a single dataset for training the models. It would be interesting to see how the models perform on a wider range of datasets, as different datasets can have varying degrees of noise and biases that may impact the performance of compressed models differently.
Additionally, the researchers do not provide much insight into the training dynamics of the ternary models, such as how the training process differs from standard floating-point models, or what techniques were used to stabilize the training. This information could be valuable for researchers looking to further improve the performance of ternary and other low-bitwidth models.
Overall, the Spectra LLM suite is a valuable contribution to the field of efficient and compressed language modeling, and the researchers' findings on ternary models are particularly intriguing. As the community continues to explore ways to make LLMs more accessible and deployable, resources like this will be increasingly important.
Conclusion
The Spectra LLM suite provides a comprehensive set of language models, including standard floating-point models, post-training quantized models, and the researchers' own ternary language models (TriLMs). By releasing this suite of models, the researchers aim to help the research community better understand the tradeoffs and performance characteristics of different approaches to model compression and efficiency.
The key findings from this research indicate that ternary models, while potentially more memory-efficient than larger floating-point models, still struggle to match the performance of their higher-precision counterparts on certain tasks. However, the researchers' TriLM architecture shows promise, with the 3.9B TriLM model matching the performance of a much larger 3.9B FloatLM on some benchmarks.
Overall, this research highlights the continued challenges in developing highly efficient language models that can maintain the performance of their larger counterparts. As the demand for deploying LLMs on resource-constrained devices grows, resources like the Spectra suite will be invaluable for guiding the development of the next generation of compressed and efficient language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
1
Spectra: A Comprehensive Study of Ternary, Quantized, and FP16 Language Models
Ayush Kaushal, Tejas Pandey, Tejas Vaidhya, Aaryan Bhagat, Irina Rish
Post-training quantization is the leading method for addressing memory-related bottlenecks in LLM inference, but unfortunately, it suffers from significant performance degradation below 4-bit precision. An alternative approach involves training compressed models directly at a low bitwidth (e.g., binary or ternary models). However, the performance, training dynamics, and scaling trends of such models are not yet well understood. To address this issue, we train and openly release the Spectra LLM suite consisting of 54 language models ranging from 99M to 3.9B parameters, trained on 300B tokens. Spectra includes FloatLMs, post-training quantized QuantLMs (3, 4, 6, and 8 bits), and ternary LLMs (TriLMs) - our improved architecture for ternary language modeling, which significantly outperforms previously proposed ternary models of a given size (in bits), matching half-precision models at scale. For example, TriLM 3.9B is (bit-wise) smaller than the half-precision FloatLM 830M, but matches half-precision FloatLM 3.9B in commonsense reasoning and knowledge benchmarks. However, TriLM 3.9B is also as toxic and stereotyping as FloatLM 3.9B, a model six times larger in size. Additionally, TriLM 3.9B lags behind FloatLM in perplexity on validation splits and web-based corpora but performs better on less noisy datasets like Lambada and PennTreeBank. To enhance understanding of low-bitwidth models, we are releasing 500+ intermediate checkpoints of the Spectra suite at href{https://github.com/NolanoOrg/SpectraSuite}{https://github.com/NolanoOrg/SpectraSuite}.
Read more7/19/2024
0
TernaryLLM: Ternarized Large Language Model
Tianqi Chen, Zhe Li, Weixiang Xu, Zeyu Zhu, Dong Li, Lu Tian, Emad Barsoum, Peisong Wang, Jian Cheng
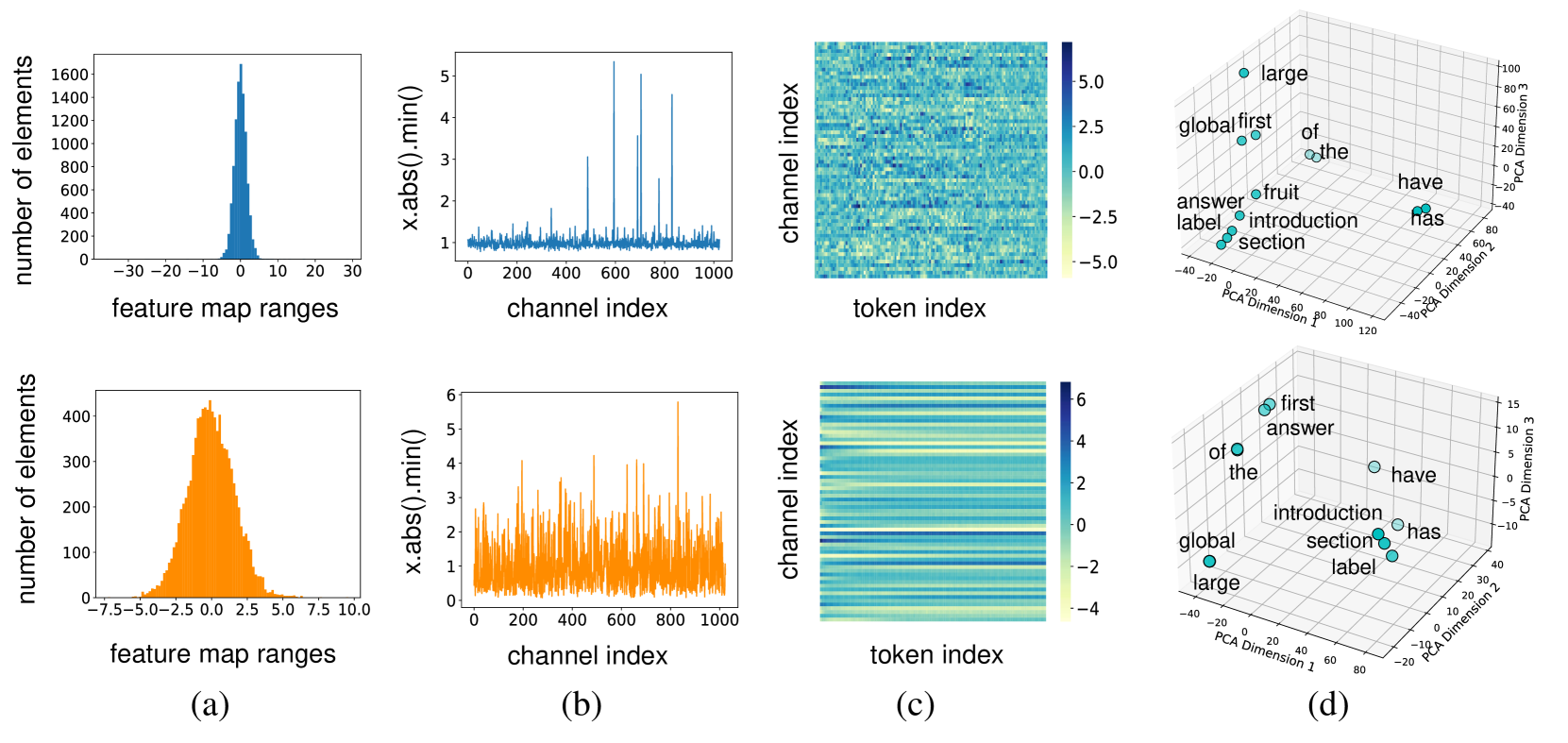
Large language models (LLMs) have achieved remarkable performance on Natural Language Processing (NLP) tasks, but they are hindered by high computational costs and memory requirements. Ternarization, an extreme form of quantization, offers a solution by reducing memory usage and enabling energy-efficient floating-point additions. However, applying ternarization to LLMs faces challenges stemming from outliers in both weights and activations. In this work, observing asymmetric outliers and non-zero means in weights, we introduce Dual Learnable Ternarization (DLT), which enables both scales and shifts to be learnable. We also propose Outlier-Friendly Feature Knowledge Distillation (OFF) to recover the information lost in extremely low-bit quantization. The proposed OFF can incorporate semantic information and is insensitive to outliers. At the core of OFF is maximizing the mutual information between features in ternarized and floating-point models using cosine similarity. Extensive experiments demonstrate that our TernaryLLM surpasses previous low-bit quantization methods on the standard text generation and zero-shot benchmarks for different LLM families. Specifically, for one of the most powerful open-source models, LLaMA-3, our approach (W1.58A16) outperforms the previous state-of-the-art method (W2A16) by 5.8 in terms of perplexity on C4 and by 8.2% in terms of average accuracy on zero-shot tasks.
Read more6/12/2024
3
SqueezeLLM: Dense-and-Sparse Quantization
Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, Kurt Keutzer
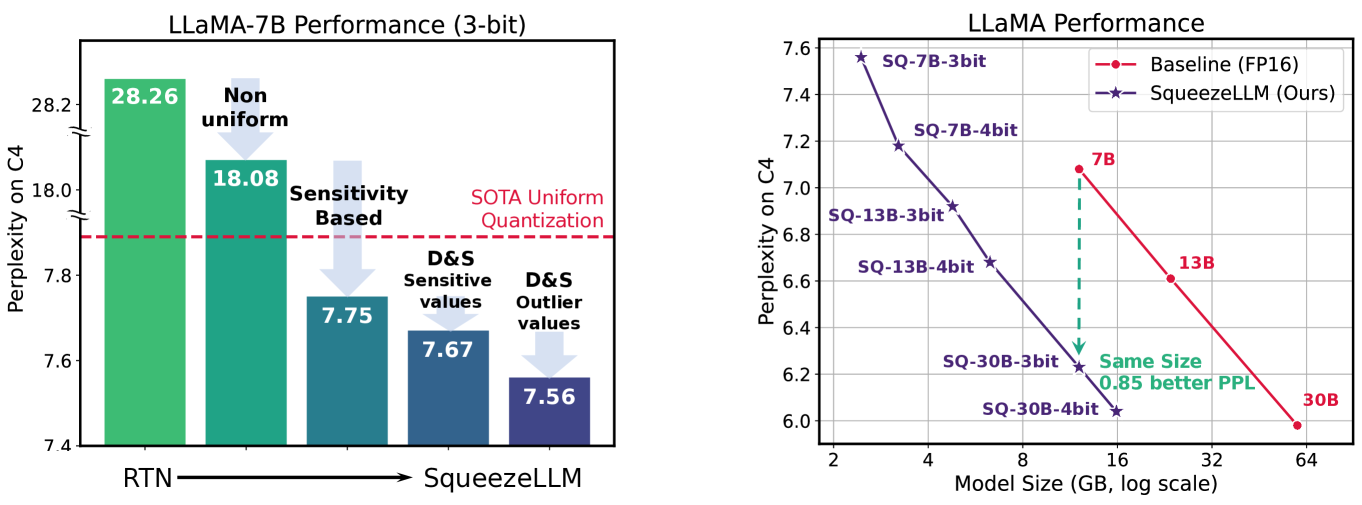
Generative Large Language Models (LLMs) have demonstrated remarkable results for a wide range of tasks. However, deploying these models for inference has been a significant challenge due to their unprecedented resource requirements. This has forced existing deployment frameworks to use multi-GPU inference pipelines, which are often complex and costly, or to use smaller and less performant models. In this work, we demonstrate that the main bottleneck for generative inference with LLMs is memory bandwidth, rather than compute, specifically for single batch inference. While quantization has emerged as a promising solution by representing weights with reduced precision, previous efforts have often resulted in notable performance degradation. To address this, we introduce SqueezeLLM, a post-training quantization framework that not only enables lossless compression to ultra-low precisions of up to 3-bit, but also achieves higher quantization performance under the same memory constraint. Our framework incorporates two novel ideas: (i) sensitivity-based non-uniform quantization, which searches for the optimal bit precision assignment based on second-order information; and (ii) the Dense-and-Sparse decomposition that stores outliers and sensitive weight values in an efficient sparse format. When applied to the LLaMA models, our 3-bit quantization significantly reduces the perplexity gap from the FP16 baseline by up to 2.1x as compared to the state-of-the-art methods with the same memory requirement. Furthermore, when deployed on an A6000 GPU, our quantized models achieve up to 2.3x speedup compared to the baseline. Our code is available at https://github.com/SqueezeAILab/SqueezeLLM.
Read more6/6/2024

0
Exploring Extreme Quantization in Spiking Language Models
Malyaban Bal, Yi Jiang, Abhronil Sengupta
Despite the growing prevalence of large language model (LLM) architectures, a crucial concern persists regarding their energy and power consumption, which still lags far behind the remarkable energy efficiency of the human brain. Recent strides in spiking language models (LM) and transformer architectures aim to address this concern by harnessing the spiking activity of biological neurons to enhance energy/power efficiency. Doubling down on the principles of model quantization and energy efficiency, this paper proposes the development of a novel binary/ternary (1/1.58-bit) spiking LM architecture. Achieving scalability comparable to a deep spiking LM architecture is facilitated by an efficient knowledge distillation technique, wherein knowledge from a non-spiking full-precision teacher model is transferred to an extremely weight quantized spiking student LM. Our proposed model represents a significant advancement as the first-of-its-kind 1/1.58-bit spiking LM, and its performance is rigorously evaluated on multiple text classification tasks of the GLUE benchmark.
Read more7/2/2024