Speech-based Mark for Data Sonification

0
📊
Sign in to get full access
Overview
- This paper introduces a speech-based markup system for data sonification.
- Sonification is the process of representing data through sound, which can make data more accessible.
- The proposed system allows users to annotate data with speech commands that control various sound parameters, enabling interactive data exploration through sound.
Plain English Explanation
The paper presents a new way to make data more accessible by representing it through sound. This process, called sonification, can help people understand complex information by converting it into audible cues.
The researchers developed a speech-based markup system that allows users to annotate data with voice commands. These commands control different sound parameters, such as pitch, volume, and timbre, which can be used to explore the data interactively through sound.
For example, a user could say "increase the pitch" while listening to a data set, and the sound would change accordingly, potentially revealing patterns or insights that might not be as easily apparent from visual representations alone. This approach aims to make data more engaging and accessible, especially for people with visual impairments or preferences for auditory information.
Technical Explanation
The paper introduces a speech-based markup system for data sonification. The system allows users to annotate data with voice commands that control various sound parameters, enabling interactive exploration of data through sound.
The researchers designed a set of speech commands that can be used to modify parameters like pitch, volume, timbre, and tempo. These commands are encoded in a markup language and associated with specific data points or regions. When the data is sonified, the system interprets the speech commands and adjusts the sound accordingly, allowing users to explore the data through an interactive auditory interface.
The paper describes the development and evaluation of this speech-based markup system, including experiments to assess its usability and effectiveness for data exploration tasks. The results suggest that the proposed approach can enhance the accessibility and engagement of data sonification, particularly for users with visual impairments or preferences for auditory interfaces.
Critical Analysis
The paper presents a novel and promising approach to making data more accessible through the use of speech-based sonification. The ability to control sound parameters using voice commands is an intuitive and engaging way to explore data, and the researchers have demonstrated its potential in initial user studies.
However, the paper does not address some potential limitations of the system. For example, the effectiveness of the speech-based approach may be influenced by factors such as accent, background noise, or the user's familiarity with the speech commands. Additionally, the paper does not discuss the scalability of the system, as it is unclear how well it would perform with large or complex data sets.
Further research could explore ways to address these limitations, such as by implementing more robust speech recognition algorithms or exploring multimodal interactions that combine speech with other input modalities. Additionally, the researchers could investigate the broader impact of this technology on data accessibility and inclusion, particularly for people with visual impairments or other accessibility needs.
Conclusion
This paper introduces a speech-based markup system for data sonification, which allows users to interactively explore data through sound. By enabling voice control of sound parameters, the system aims to enhance the accessibility and engagement of data analysis, particularly for users with visual impairments or preferences for auditory interfaces.
The proposed approach represents a promising step towards more inclusive and engaging data visualization and exploration tools. While the paper highlights the potential of this technology, further research is needed to address potential limitations and explore its broader impact on data accessibility and inclusive design.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Speech-based Mark for Data Sonification
Yichun Zhao, Jingyi Lu, Miguel A Nacenta
Sonification serves as a powerful tool for data accessibility, especially for people with vision loss. Among various modalities, speech is a familiar means of communication similar to the role of text in visualization. However, speech-based sonification is underexplored. We introduce SpeechTone, a novel speech-based mark for data sonification and extension to the existing Erie declarative grammar for sonification. It encodes data into speech attributes such as pitch, speed, voice and speech content. We demonstrate the efficacy of SpeechTone through three examples.
Read more8/14/2024

0
Interactive Sonification for Health and Energy using ChucK and Unity
Yichun Zhao, George Tzanetakis
Sonification can provide valuable insights about data but most existing approaches are not designed to be controlled by the user in an interactive fashion. Interactions enable the designer of the sonification to more rapidly experiment with sound design and allow the sonification to be modified in real-time by interacting with various control parameters. In this paper, we describe two case studies of interactive sonification that utilize publicly available datasets that have been described recently in the International Conference on Auditory Display (ICAD). They are from the health and energy domains: electroencephalogram (EEG) alpha wave data and air pollutant data consisting of nitrogen dioxide, sulfur dioxide, carbon monoxide, and ozone. We show how these sonfications can be recreated to support interaction utilizing a general interactive sonification framework built using ChucK, Unity, and Chunity. In addition to supporting typical sonification methods that are common in existing sonification toolkits, our framework introduces novel methods such as supporting discrete events, interleaved playback of multiple data streams for comparison, and using frequency modulation (FM) synthesis in terms of one data attribute modulating another. We also describe how these new functionalities can be used to improve the sonification experience of the two datasets we have investigated.
Read more4/16/2024
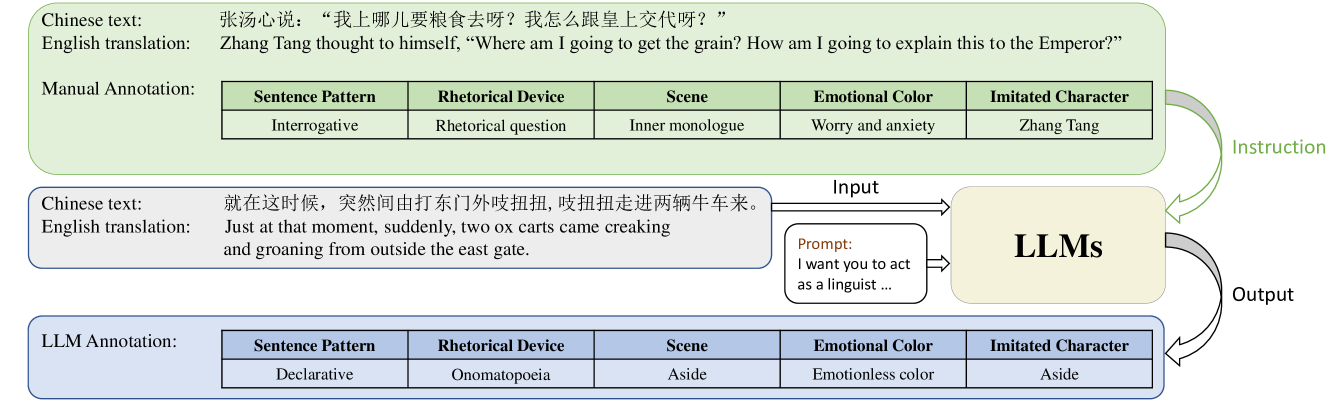
0
StoryTTS: A Highly Expressive Text-to-Speech Dataset with Rich Textual Expressiveness Annotations
Sen Liu, Yiwei Guo, Xie Chen, Kai Yu
While acoustic expressiveness has long been studied in expressive text-to-speech (ETTS), the inherent expressiveness in text lacks sufficient attention, especially for ETTS of artistic works. In this paper, we introduce StoryTTS, a highly ETTS dataset that contains rich expressiveness both in acoustic and textual perspective, from the recording of a Mandarin storytelling show. A systematic and comprehensive labeling framework is proposed for textual expressiveness. We analyze and define speech-related textual expressiveness in StoryTTS to include five distinct dimensions through linguistics, rhetoric, etc. Then we employ large language models and prompt them with a few manual annotation examples for batch annotation. The resulting corpus contains 61 hours of consecutive and highly prosodic speech equipped with accurate text transcriptions and rich textual expressiveness annotations. Therefore, StoryTTS can aid future ETTS research to fully mine the abundant intrinsic textual and acoustic features. Experiments are conducted to validate that TTS models can generate speech with improved expressiveness when integrating with the annotated textual labels in StoryTTS.
Read more4/24/2024
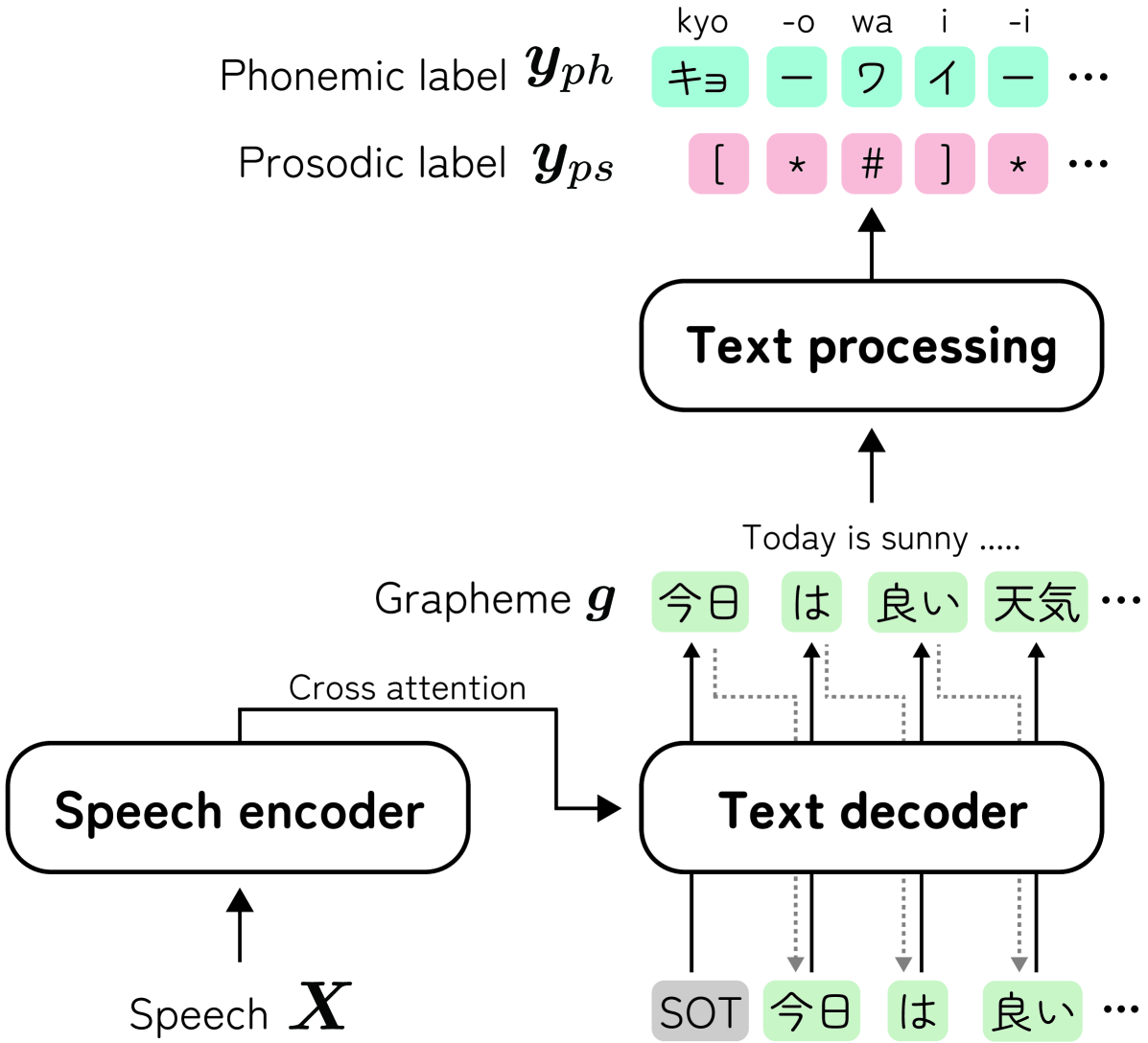
0
Audio-conditioned phonemic and prosodic annotation for building text-to-speech models from unlabeled speech data
Yuma Shirahata, Byeongseon Park, Ryuichi Yamamoto, Kentaro Tachibana
This paper proposes an audio-conditioned phonemic and prosodic annotation model for building text-to-speech (TTS) datasets from unlabeled speech samples. For creating a TTS dataset that consists of label-speech paired data, the proposed annotation model leverages an automatic speech recognition (ASR) model to obtain phonemic and prosodic labels from unlabeled speech samples. By fine-tuning a large-scale pre-trained ASR model, we can construct the annotation model using a limited amount of label-speech paired data within an existing TTS dataset. To alleviate the shortage of label-speech paired data for training the annotation model, we generate pseudo label-speech paired data using text-only corpora and an auxiliary TTS model. This TTS model is also trained with the existing TTS dataset. Experimental results show that the TTS model trained with the dataset created by the proposed annotation method can synthesize speech as naturally as the one trained with a fully-labeled dataset.
Read more6/13/2024