SpikeNVS: Enhancing Novel View Synthesis from Blurry Images via Spike Camera
2404.06710
0
0
Abstract
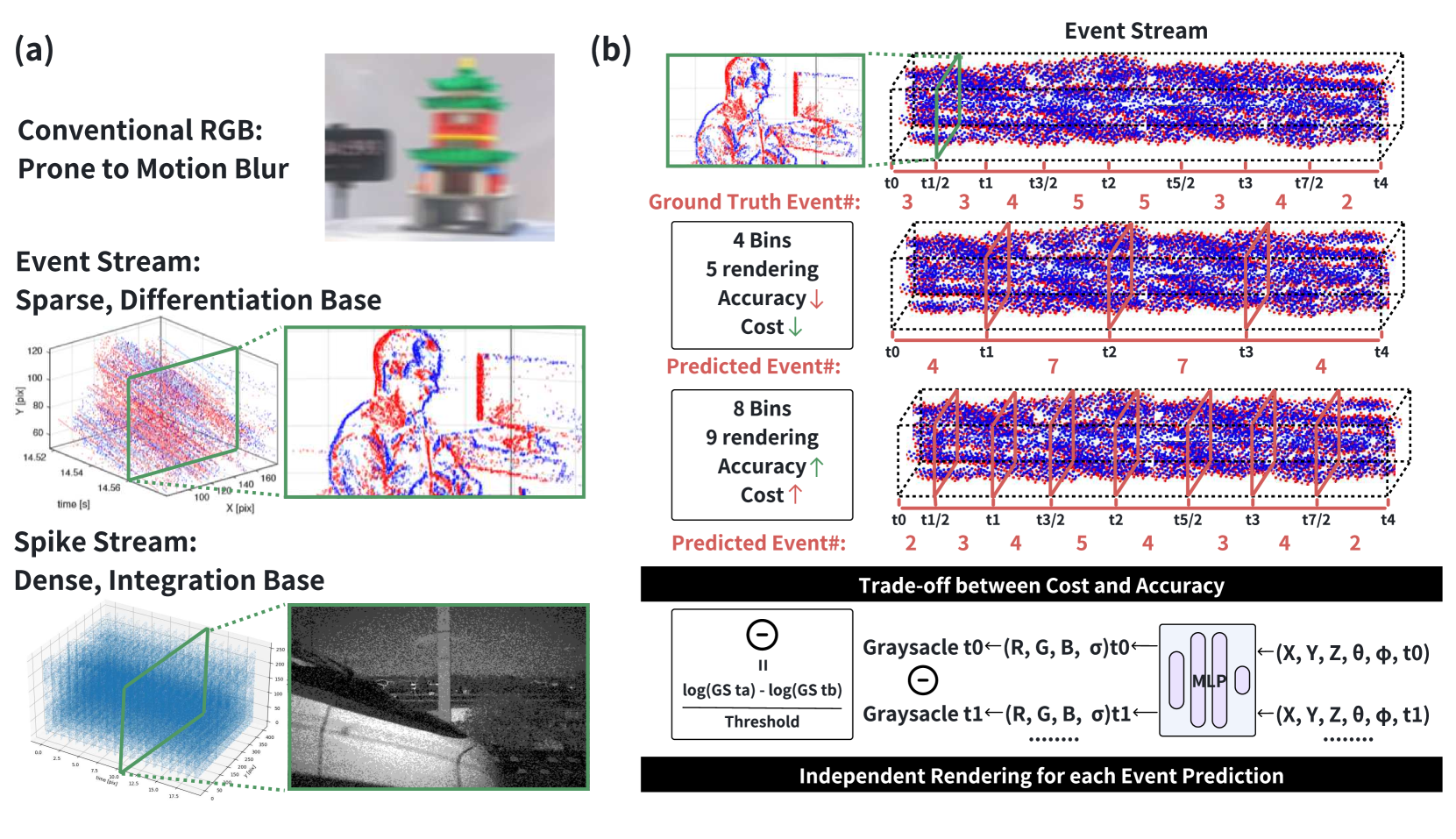
One of the most critical factors in achieving sharp Novel View Synthesis (NVS) using neural field methods like Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) is the quality of the training images. However, Conventional RGB cameras are susceptible to motion blur. In contrast, neuromorphic cameras like event and spike cameras inherently capture more comprehensive temporal information, which can provide a sharp representation of the scene as additional training data. Recent methods have explored the integration of event cameras to improve the quality of NVS. The event-RGB approaches have some limitations, such as high training costs and the inability to work effectively in the background. Instead, our study introduces a new method that uses the spike camera to overcome these limitations. By considering texture reconstruction from spike streams as ground truth, we design the Texture from Spike (TfS) loss. Since the spike camera relies on temporal integration instead of temporal differentiation used by event cameras, our proposed TfS loss maintains manageable training costs. It handles foreground objects with backgrounds simultaneously. We also provide a real-world dataset captured with our spike-RGB camera system to facilitate future research endeavors. We conduct extensive experiments using synthetic and real-world datasets to demonstrate that our design can enhance novel view synthesis across NeRF and 3DGS. The code and dataset will be made available for public access.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a novel method called SpikeNVS to enhance novel view synthesis from blurry images using a spike camera.
- The key idea is to leverage the high temporal resolution and low latency of spike cameras to address the challenges of motion blur in novel view synthesis tasks.
- The authors demonstrate that SpikeNVS can significantly improve the quality of synthesized novel views compared to traditional methods, especially for blurry input images.
Plain English Explanation
The paper discusses a new technique called SpikeNVS that can create high-quality 3D images from blurry 2D photos. Traditional methods for creating 3D images from 2D photos often struggle when the input photos are blurry, for example due to camera shake or fast-moving objects. SpikeNVS aims to solve this problem by using a special type of camera called a "spike camera" that can capture images with very high speed and precision.
Spike cameras work differently than regular cameras - they don't take full-frame photos, but instead detect small changes in the scene over time. This allows them to capture sharp images even of fast-moving objects. The authors of this paper show that by using the data from a spike camera, they can significantly improve the quality of 3D images created from blurry 2D photos. This could be useful in a variety of applications, such as 3D geometry-aware deformable Gaussian splatting for dynamic scenes, robust Gaussian splatting for novel view synthesis, or LiDAR4D for dynamic neural fields and novel space-time.
Technical Explanation
The key innovation in this paper is the use of a spike camera to address the challenges of motion blur in novel view synthesis tasks. Spike cameras are a type of neuromorphic sensor that capture changes in the visual scene over time, rather than taking full-frame photographs. This allows them to capture high-speed motion with low latency and high temporal resolution.
The authors propose a novel deep learning architecture called SpikeNVS that takes as input both a blurry RGB image and the corresponding spike camera data, and outputs a high-quality novel view synthesis. The spike camera data helps the network overcome the motion blur in the input image, enabling it to synthesize more accurate and realistic novel views.
The authors evaluate SpikeNVS on several benchmark datasets and show that it significantly outperforms state-of-the-art novel view synthesis methods, especially for input images with severe motion blur. They also demonstrate that SpikeNVS can be combined with other techniques like SGD for street view synthesis with Gaussian splatting and diffusion and mitigating motion blur in neural radiance fields with events to further improve the quality of novel view synthesis.
Critical Analysis
The authors provide a thorough evaluation of SpikeNVS and demonstrate its effectiveness in addressing the challenges of motion blur in novel view synthesis. However, some potential limitations and areas for further research are worth considering:
- The performance of SpikeNVS may be dependent on the quality and availability of spike camera data, which may not be readily available in many real-world scenarios.
- The authors only evaluate SpikeNVS on limited datasets and scenarios, and it would be important to assess its performance on a wider range of real-world scenes and conditions.
- The computational and memory requirements of the SpikeNVS architecture may be a concern, especially for deployment on resource-constrained devices.
Additionally, while the authors highlight the potential applications of SpikeNVS in various fields, it would be valuable to further explore the specific use cases and implications of this technology, as well as any potential ethical considerations.
Conclusion
This paper presents a novel approach called SpikeNVS that leverages spike camera data to enhance the quality of novel view synthesis, particularly for input images with significant motion blur. The authors demonstrate the effectiveness of their method on benchmark datasets and show that SpikeNVS can outperform state-of-the-art techniques. While there are some potential limitations to consider, the proposed approach represents an important step towards overcoming the challenges of motion blur in 3D reconstruction and visualization tasks, with applications in various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
Mitigating Motion Blur in Neural Radiance Fields with Events and Frames
Marco Cannici, Davide Scaramuzza
0
0
Neural Radiance Fields (NeRFs) have shown great potential in novel view synthesis. However, they struggle to render sharp images when the data used for training is affected by motion blur. On the other hand, event cameras excel in dynamic scenes as they measure brightness changes with microsecond resolution and are thus only marginally affected by blur. Recent methods attempt to enhance NeRF reconstructions under camera motion by fusing frames and events. However, they face challenges in recovering accurate color content or constrain the NeRF to a set of predefined camera poses, harming reconstruction quality in challenging conditions. This paper proposes a novel formulation addressing these issues by leveraging both model- and learning-based modules. We explicitly model the blur formation process, exploiting the event double integral as an additional model-based prior. Additionally, we model the event-pixel response using an end-to-end learnable response function, allowing our method to adapt to non-idealities in the real event-camera sensor. We show, on synthetic and real data, that the proposed approach outperforms existing deblur NeRFs that use only frames as well as those that combine frames and events by +6.13dB and +2.48dB, respectively.
4/1/2024
🌐
A Novel Spike Transformer Network for Depth Estimation from Event Cameras via Cross-modality Knowledge Distillation
Xin Zhang, Liangxiu Han, Tam Sobeih, Lianghao Han, Darren Dancey
0
0
Depth estimation is crucial for interpreting complex environments, especially in areas such as autonomous vehicle navigation and robotics. Nonetheless, obtaining accurate depth readings from event camera data remains a formidable challenge. Event cameras operate differently from traditional digital cameras, continuously capturing data and generating asynchronous binary spikes that encode time, location, and light intensity. Yet, the unique sampling mechanisms of event cameras render standard image based algorithms inadequate for processing spike data. This necessitates the development of innovative, spike-aware algorithms tailored for event cameras, a task compounded by the irregularity, continuity, noise, and spatial and temporal characteristics inherent in spiking data.Harnessing the strong generalization capabilities of transformer neural networks for spatiotemporal data, we propose a purely spike-driven spike transformer network for depth estimation from spiking camera data. To address performance limitations with Spiking Neural Networks (SNN), we introduce a novel single-stage cross-modality knowledge transfer framework leveraging knowledge from a large vision foundational model of artificial neural networks (ANN) (DINOv2) to enhance the performance of SNNs with limited data. Our experimental results on both synthetic and real datasets show substantial improvements over existing models, with notable gains in Absolute Relative and Square Relative errors (49% and 39.77% improvements over the benchmark model Spike-T, respectively). Besides accuracy, the proposed model also demonstrates reduced power consumptions, a critical factor for practical applications.
5/2/2024
SGD: Street View Synthesis with Gaussian Splatting and Diffusion Prior
Zhongrui Yu, Haoran Wang, Jinze Yang, Hanzhang Wang, Zeke Xie, Yunfeng Cai, Jiale Cao, Zhong Ji, Mingming Sun
0
0
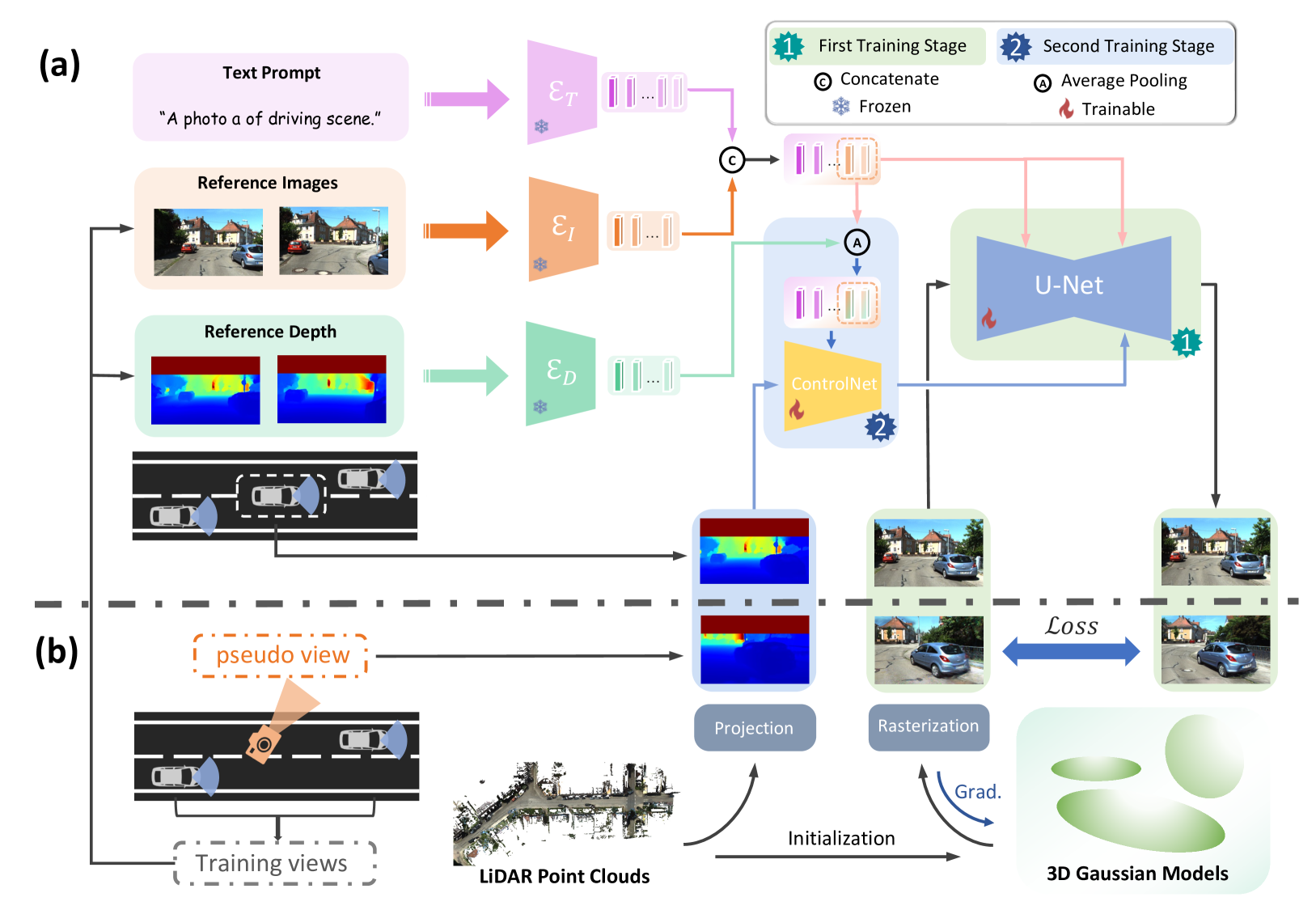
Novel View Synthesis (NVS) for street scenes play a critical role in the autonomous driving simulation. The current mainstream technique to achieve it is neural rendering, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). Although thrilling progress has been made, when handling street scenes, current methods struggle to maintain rendering quality at the viewpoint that deviates significantly from the training viewpoints. This issue stems from the sparse training views captured by a fixed camera on a moving vehicle. To tackle this problem, we propose a novel approach that enhances the capacity of 3DGS by leveraging prior from a Diffusion Model along with complementary multi-modal data. Specifically, we first fine-tune a Diffusion Model by adding images from adjacent frames as condition, meanwhile exploiting depth data from LiDAR point clouds to supply additional spatial information. Then we apply the Diffusion Model to regularize the 3DGS at unseen views during training. Experimental results validate the effectiveness of our method compared with current state-of-the-art models, and demonstrate its advance in rendering images from broader views.
4/1/2024
SparseGS: Real-Time 360{deg} Sparse View Synthesis using Gaussian Splatting
Haolin Xiong, Sairisheek Muttukuru, Rishi Upadhyay, Pradyumna Chari, Achuta Kadambi
0
0
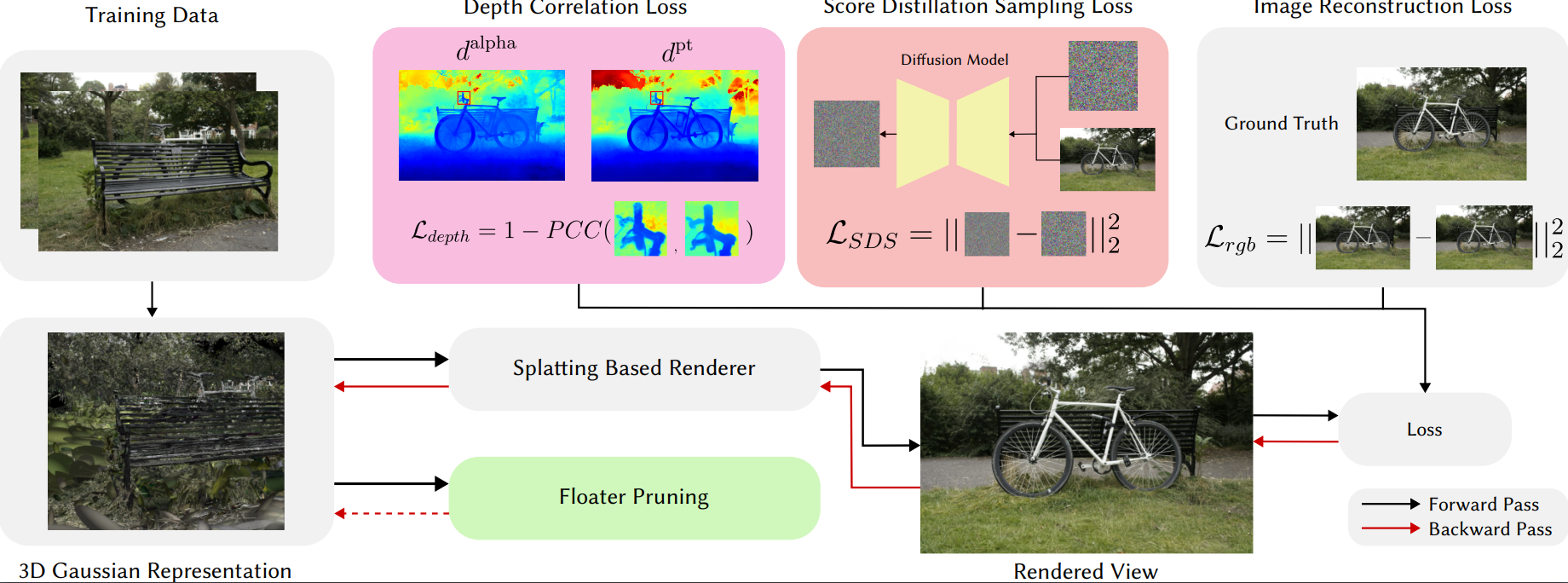
The problem of novel view synthesis has grown significantly in popularity recently with the introduction of Neural Radiance Fields (NeRFs) and other implicit scene representation methods. A recent advance, 3D Gaussian Splatting (3DGS), leverages an explicit representation to achieve real-time rendering with high-quality results. However, 3DGS still requires an abundance of training views to generate a coherent scene representation. In few shot settings, similar to NeRF, 3DGS tends to overfit to training views, causing background collapse and excessive floaters, especially as the number of training views are reduced. We propose a method to enable training coherent 3DGS-based radiance fields of 360-degree scenes from sparse training views. We integrate depth priors with generative and explicit constraints to reduce background collapse, remove floaters, and enhance consistency from unseen viewpoints. Experiments show that our method outperforms base 3DGS by 6.4% in LPIPS and by 12.2% in PSNR, and NeRF-based methods by at least 17.6% in LPIPS on the MipNeRF-360 dataset with substantially less training and inference cost.
5/14/2024