Spiking Structured State Space Model for Monaural Speech Enhancement
2309.03641
0
0
📈
Abstract
Speech enhancement seeks to extract clean speech from noisy signals. Traditional deep learning methods face two challenges: efficiently using information in long speech sequences and high computational costs. To address these, we introduce the Spiking Structured State Space Model (Spiking-S4). This approach merges the energy efficiency of Spiking Neural Networks (SNN) with the long-range sequence modeling capabilities of Structured State Space Models (S4), offering a compelling solution. Evaluation on the DNS Challenge and VoiceBank+Demand Datasets confirms that Spiking-S4 rivals existing Artificial Neural Network (ANN) methods but with fewer computational resources, as evidenced by reduced parameters and Floating Point Operations (FLOPs).
Create account to get full access
Overview
- This paper introduces a novel approach called Spiking Structured State Space Model (Spiking-S4) for speech enhancement.
- Spiking-S4 combines the energy efficiency of Spiking Neural Networks (SNN) with the long-range sequence modeling capabilities of Structured State Space Models (S4).
- The goal is to address the challenges of efficiently using information in long speech sequences and high computational costs faced by traditional deep learning methods.
Plain English Explanation
Spiking-S4 is a new type of neural network designed for improving the quality of speech recordings. When you record audio, especially in noisy environments, the resulting sound can be hard to understand. Spiking-S4 is a way to remove that background noise and make the speech clearer.
Traditional neural networks have two main problems when it comes to this task. First, they struggle to effectively use all the information contained in long stretches of speech. Second, they require a lot of computing power to run. Spiking-S4 solves these issues by combining two powerful techniques:
-
Spiking Neural Networks (SNNs): These networks mimic the way the brain processes information, using quick "spikes" of activity instead of the continuous signals in traditional neural networks. This makes them much more energy-efficient.
-
Structured State Space Models (S4): These models excel at analyzing long sequences of data, like entire sentences of speech. They can pick up on subtle patterns and relationships that traditional networks might miss.
By putting these two ideas together, Spiking-S4 can clean up noisy speech recordings without needing as much computing power as other approaches. The authors tested it on standard speech enhancement benchmarks and found it performed just as well as other state-of-the-art methods, but with far fewer computational resources required.
Technical Explanation
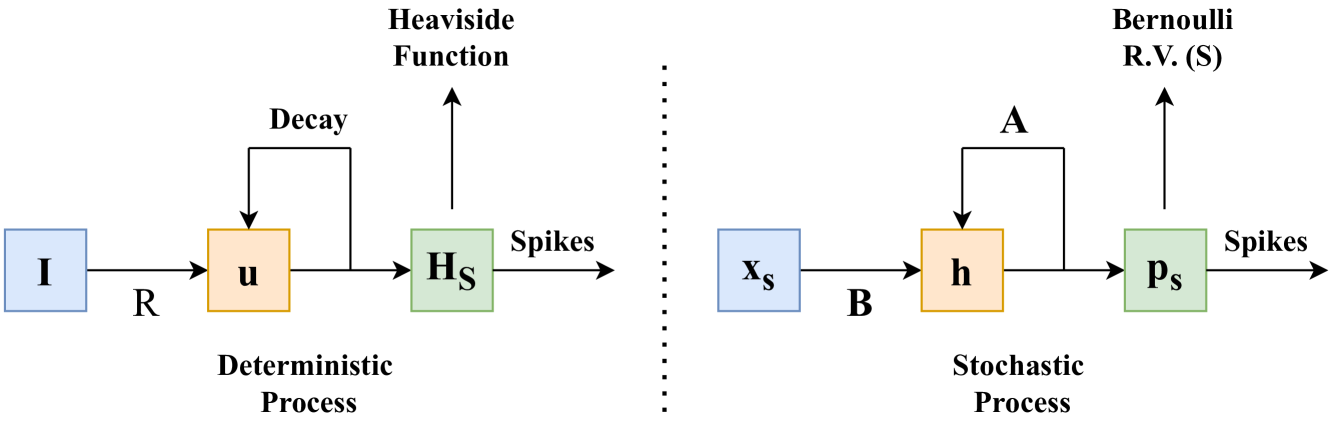
The key innovation in this paper is the Spiking Structured State Space Model (Spiking-S4), which combines the strengths of Spiking Neural Networks (SNNs) and Structured State Space Models (S4).
SNNs are a type of biologically-inspired neural network that use discrete "spikes" of activity instead of continuous signals. This makes them more energy-efficient than traditional Artificial Neural Networks (ANNs). However, SNNs have historically struggled with modeling long-range dependencies in sequences like speech.
S4, on the other hand, is a powerful sequence modeling architecture that can effectively capture long-term relationships. But standard S4 models are computationally expensive.
By merging SNN and S4 principles, Spiking-S4 inherits the efficiency of SNNs and the sequence modeling capacity of S4. The authors demonstrate that Spiking-S4 matches the speech enhancement performance of ANN-based approaches on the DNS Challenge and VoiceBank+Demand datasets, while using significantly fewer parameters and FLOPs (Floating Point Operations).
The authors also draw connections between the structure of Spiking-S4 and neural oscillations observed during speech perception, suggesting potential neuroscientific insights.
Critical Analysis
The Spiking-S4 approach presented in this paper is a promising step towards more efficient and effective speech enhancement systems. By leveraging the complementary strengths of SNNs and S4, the authors have developed a compelling model that rivals the performance of traditional ANN-based methods while requiring fewer computational resources.
One potential limitation is that the paper only evaluates Spiking-S4 on a few standard speech enhancement benchmarks. Further testing on a wider range of datasets and real-world scenarios could help validate the generalizability of the approach.
Additionally, the authors do not provide a detailed analysis of the model's robustness to different types of noise or its performance in low-resource settings. Exploring these aspects could shed more light on the practical applicability of Spiking-S4.
Despite these minor caveats, the core idea of combining energy-efficient SNNs with powerful sequence modeling from S4 is a significant contribution to the field of speech enhancement. The authors' observations about the potential connections to neural oscillations during speech perception also open up intriguing avenues for future research.
Conclusion
The Spiking Structured State Space Model (Spiking-S4) introduced in this paper presents a novel approach to speech enhancement that addresses key challenges faced by traditional deep learning methods. By merging the energy efficiency of Spiking Neural Networks (SNNs) with the long-range sequence modeling capabilities of Structured State Space Models (S4), Spiking-S4 offers a compelling solution for improving the quality of noisy speech recordings.
The evaluation results demonstrate that Spiking-S4 can match the performance of existing Artificial Neural Network (ANN) techniques while requiring fewer computational resources, as evidenced by the reduced parameters and Floating Point Operations (FLOPs). This efficiency could enable the deployment of high-quality speech enhancement systems in low-power and resource-constrained environments.
The potential connections between the Spiking-S4 architecture and the neural oscillations observed during speech perception also suggest that this research could lead to valuable insights at the intersection of machine learning and neuroscience. As the field of speech enhancement continues to evolve, the Spiking-S4 model presented in this paper represents an important step forward in developing more efficient and effective solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Rethinking Spiking Neural Networks as State Space Models
Malyaban Bal, Abhronil Sengupta
0
0
Spiking neural networks (SNNs) are posited as a biologically plausible alternative to conventional neural architectures, with their core computational framework resting on the extensively studied leaky integrate-and-fire (LIF) neuron design. The stateful nature of LIF neurons has spurred ongoing discussions about the ability of SNNs to process sequential data, akin to recurrent neural networks (RNNs). Despite this, there remains a significant gap in the exploration of current SNNs within the realm of long-range dependency tasks. In this study, to extend the analysis of neuronal dynamics beyond simplistic LIF mechanism, we present a novel class of stochastic spiking neuronal model grounded in state space models. We expand beyond the scalar hidden state representation of LIF neurons, which traditionally comprises only the membrane potential, by proposing an n-dimensional hidden state. Additionally, we enable fine-tuned formulation of neuronal dynamics across each layer by introducing learnable parameters, as opposed to the fixed dynamics in LIF neurons. We also develop a robust framework for scaling these neuronal models to deep SNN-based architectures, ensuring efficient parallel training while also adeptly addressing the challenge of non-differentiability of stochastic spiking operation during the backward phase. Our models attain state-of-the-art performance among SNN models across diverse long-range dependency tasks, encompassing the Long Range Arena benchmark, permuted sequential MNIST, and the Speech Command dataset. Moreover, we provide an analysis of the energy efficiency advantages, emphasizing the sparse activity pattern intrinsic to this spiking model.
6/6/2024

Multichannel Long-Term Streaming Neural Speech Enhancement for Static and Moving Speakers
Changsheng Quan, Xiaofei Li
0
0
In this work, we extend our previously proposed offline SpatialNet for long-term streaming multichannel speech enhancement in both static and moving speaker scenarios. SpatialNet exploits spatial information, such as the spatial/steering direction of speech, for discriminating between target speech and interferences, and achieved outstanding performance. The core of SpatialNet is a narrow-band self-attention module used for learning the temporal dynamic of spatial vectors. Towards long-term streaming speech enhancement, we propose to replace the offline self-attention network with online networks that have linear inference complexity w.r.t signal length and meanwhile maintain the capability of learning long-term information. Three variants are developed based on (i) masked self-attention, (ii) Retention, a self-attention variant with linear inference complexity, and (iii) Mamba, a structured-state-space-based RNN-like network. Moreover, we investigate the length extrapolation ability of different networks, namely test on signals that are much longer than training signals, and propose a short-signal training plus long-signal fine-tuning strategy, which largely improves the length extrapolation ability of the networks within limited training time. Overall, the proposed online SpatialNet achieves outstanding speech enhancement performance for long audio streams, and for both static and moving speakers. The proposed method is open-sourced in https://github.com/Audio-WestlakeU/NBSS.
6/21/2024

Spiking Convolutional Neural Networks for Text Classification
Changze Lv, Jianhan Xu, Xiaoqing Zheng
0
0
Spiking neural networks (SNNs) offer a promising pathway to implement deep neural networks (DNNs) in a more energy-efficient manner since their neurons are sparsely activated and inferences are event-driven. However, there have been very few works that have demonstrated the efficacy of SNNs in language tasks partially because it is non-trivial to represent words in the forms of spikes and to deal with variable-length texts by SNNs. This work presents a conversion + fine-tuning two-step method for training SNNs for text classification and proposes a simple but effective way to encode pre-trained word embeddings as spike trains. We show empirically that after fine-tuning with surrogate gradients, the converted SNNs achieve comparable results to their DNN counterparts with much less energy consumption across multiple datasets for both English and Chinese. We also show that such SNNs are more robust to adversarial attacks than DNNs.
6/28/2024

SpikeLM: Towards General Spike-Driven Language Modeling via Elastic Bi-Spiking Mechanisms
Xingrun Xing, Zheng Zhang, Ziyi Ni, Shitao Xiao, Yiming Ju, Siqi Fan, Yequan Wang, Jiajun Zhang, Guoqi Li
0
0
Towards energy-efficient artificial intelligence similar to the human brain, the bio-inspired spiking neural networks (SNNs) have advantages of biological plausibility, event-driven sparsity, and binary activation. Recently, large-scale language models exhibit promising generalization capability, making it a valuable issue to explore more general spike-driven models. However, the binary spikes in existing SNNs fail to encode adequate semantic information, placing technological challenges for generalization. This work proposes the first fully spiking mechanism for general language tasks, including both discriminative and generative ones. Different from previous spikes with {0,1} levels, we propose a more general spike formulation with bi-directional, elastic amplitude, and elastic frequency encoding, while still maintaining the addition nature of SNNs. In a single time step, the spike is enhanced by direction and amplitude information; in spike frequency, a strategy to control spike firing rate is well designed. We plug this elastic bi-spiking mechanism in language modeling, named SpikeLM. It is the first time to handle general language tasks with fully spike-driven models, which achieve much higher accuracy than previously possible. SpikeLM also greatly bridges the performance gap between SNNs and ANNs in language modeling. Our code is available at https://github.com/Xingrun-Xing/SpikeLM.
6/6/2024