SPMamba: State-space model is all you need in speech separation
2404.02063
0
0
Abstract
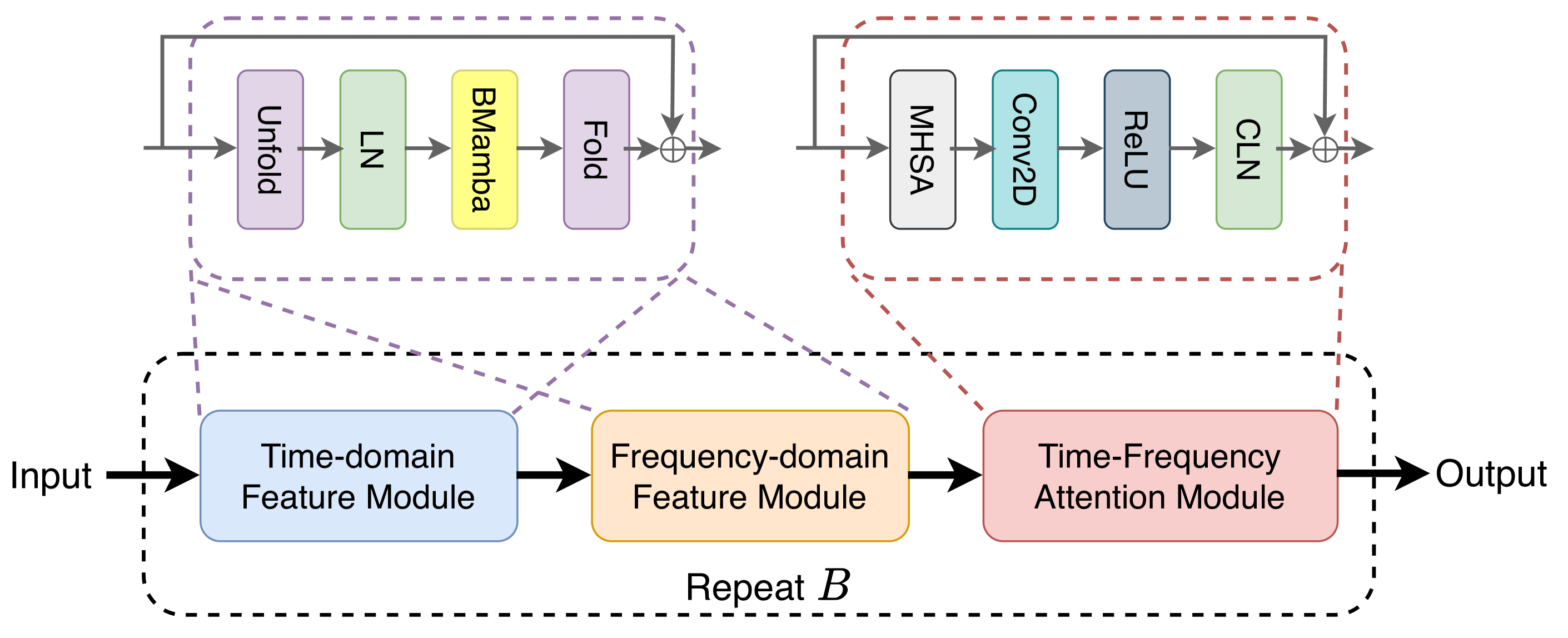
In speech separation, both CNN- and Transformer-based models have demonstrated robust separation capabilities, garnering significant attention within the research community. However, CNN-based methods have limited modelling capability for long-sequence audio, leading to suboptimal separation performance. Conversely, Transformer-based methods are limited in practical applications due to their high computational complexity. Notably, within computer vision, Mamba-based methods have been celebrated for their formidable performance and reduced computational requirements. In this paper, we propose a network architecture for speech separation using a state-space model, namely SPMamba. We adopt the TF-GridNet model as the foundational framework and substitute its Transformer component with a bidirectional Mamba module, aiming to capture a broader range of contextual information. Our experimental results reveal an important role in the performance aspects of Mamba-based models. SPMamba demonstrates superior performance with a significant advantage over existing separation models in a dataset built on Librispeech. Notably, SPMamba achieves a substantial improvement in separation quality, with a 2.42 dB enhancement in SI-SNRi compared to the TF-GridNet. The source code for SPMamba is publicly accessible at https://github.com/JusperLee/SPMamba .
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a state-space model called SPMamba for speech separation, which aims to separate different speakers' voices from a mixed audio signal.
- The authors introduce the Mamba framework, which provides a flexible state-space modeling approach, and show how it can be applied to the speech separation task.
- The proposed SPMamba model demonstrates state-of-the-art performance on several speech separation benchmarks, outperforming previous deep learning-based approaches.
Plain English Explanation
The paper introduces a new technique called SPMamba for separating different voices from a mixed audio recording. This is a common problem in speech processing, where you might have a recording with multiple people speaking at the same time and you want to isolate each individual's voice.
The key insight of the paper is that the state-space modeling approach used in the Mamba framework can be effectively applied to this speech separation task. State-space models are a flexible way of representing and reasoning about complex dynamic systems, and the authors show how this perspective can outperform previous deep learning-based methods for speech separation.
The SPMamba model takes the mixed audio signal as input and learns to estimate the individual voice signals for each speaker. This is done by representing the audio as a sequence of latent state vectors that capture the evolving characteristics of each speaker's voice over time. The model is trained end-to-end to optimize these state representations for accurate voice separation.
The results demonstrate that SPMamba achieves state-of-the-art performance on standard speech separation benchmarks, significantly outperforming previous deep learning approaches. This suggests that the state-space modeling perspective can be a powerful tool for tackling complex audio processing tasks like this.
Technical Explanation
The core of the paper is the SPMamba model, which is a state-space model designed for the task of speech separation. The authors build on the flexible Mamba framework for state-space modeling, adapting it to the specifics of the speech separation problem.
The model takes a mixed audio signal as input and learns to estimate the individual voice signals for each speaker present in the recording. This is done by representing the audio as a sequence of latent state vectors, where each state captures the evolving characteristics of a particular speaker's voice over time.
The state-space formulation includes an observation model that maps the latent states to the observed mixed audio, as well as a transition model that governs how the states evolve from one time step to the next. These models are parameterized using neural networks and trained end-to-end to optimize the separation performance.
The authors evaluate SPMamba on several standard speech separation benchmarks and show that it outperforms previous deep learning-based approaches by a significant margin. This highlights the potential of the state-space modeling perspective for tackling complex audio processing tasks.
Critical Analysis
The paper presents a compelling approach to speech separation using state-space models, but there are a few potential limitations and areas for further research that could be considered:
-
The model assumes a fixed number of speakers in the mixed audio, which may not always be the case in real-world scenarios. Extending the approach to handle a variable number of speakers could be an important next step.
-
The state-space formulation relies on some strong assumptions, such as the Markovian nature of the speaker dynamics. Further research into the robustness of these assumptions and potential relaxations would be valuable.
-
While the results demonstrate state-of-the-art performance, it would be interesting to analyze the model's interpretability and understand how the learned state representations relate to the underlying voice characteristics.
-
The paper focuses on evaluating SPMamba on standard speech separation benchmarks. Exploring the model's performance and generalization in more diverse or challenging real-world settings could provide additional insights.
Overall, the paper makes a compelling case for the potential of state-space models in speech separation and opens up interesting directions for further research and development in this area.
Conclusion
This paper presents a novel state-space model called SPMamba for the task of speech separation. By drawing on the flexible Mamba framework, the authors demonstrate that a state-space modeling approach can outperform previous deep learning-based methods on standard speech separation benchmarks.
The key strengths of the SPMamba model are its ability to effectively capture the evolving characteristics of individual speakers' voices over time, and its end-to-end trainability to optimize separation performance. The results highlight the promise of state-space models for tackling complex audio processing challenges, and suggest further avenues for research and development in this area.
As speech processing technologies continue to advance, techniques like SPMamba that can robustly separate and isolate individual voices from mixed audio could have important applications in areas such as teleconferencing, voice assistants, and audio archiving and analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Dual-path Mamba: Short and Long-term Bidirectional Selective Structured State Space Models for Speech Separation
Xilin Jiang, Cong Han, Nima Mesgarani
0
0
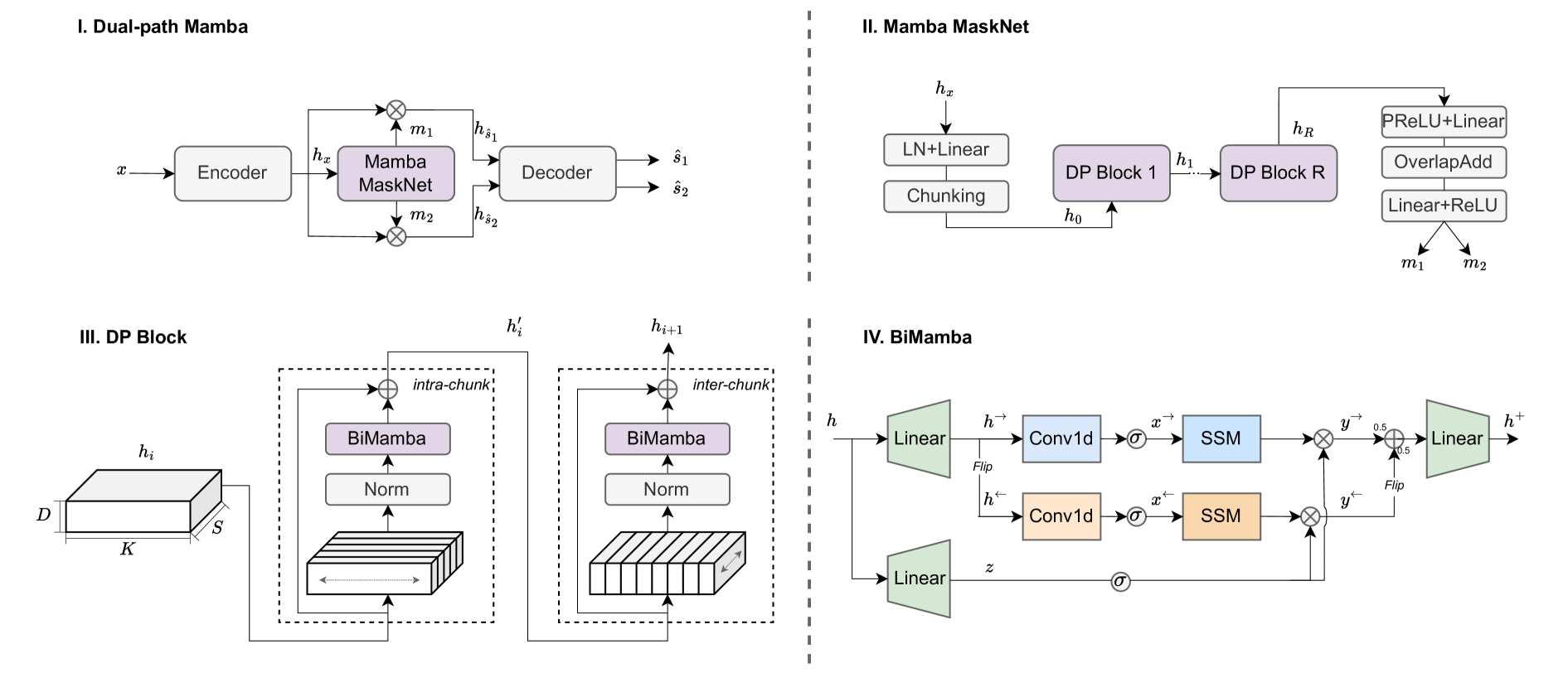
Transformers have been the most successful architecture for various speech modeling tasks, including speech separation. However, the self-attention mechanism in transformers with quadratic complexity is inefficient in computation and memory. Recent models incorporate new layers and modules along with transformers for better performance but also introduce extra model complexity. In this work, we replace transformers with Mamba, a selective state space model, for speech separation. We propose dual-path Mamba, which models short-term and long-term forward and backward dependency of speech signals using selective state spaces. Our experimental results on the WSJ0-2mix data show that our dual-path Mamba models of comparably smaller sizes outperform state-of-the-art RNN model DPRNN, CNN model WaveSplit, and transformer model Sepformer. Code: https://github.com/xi-j/Mamba-TasNet
5/2/2024
🗣️
An Investigation of Incorporating Mamba for Speech Enhancement
Rong Chao, Wen-Huang Cheng, Moreno La Quatra, Sabato Marco Siniscalchi, Chao-Han Huck Yang, Szu-Wei Fu, Yu Tsao
0
0
This work aims to study a scalable state-space model (SSM), Mamba, for the speech enhancement (SE) task. We exploit a Mamba-based regression model to characterize speech signals and build an SE system upon Mamba, termed SEMamba. We explore the properties of Mamba by integrating it as the core model in both basic and advanced SE systems, along with utilizing signal-level distances as well as metric-oriented loss functions. SEMamba demonstrates promising results and attains a PESQ score of 3.55 on the VoiceBank-DEMAND dataset. When combined with the perceptual contrast stretching technique, the proposed SEMamba yields a new state-of-the-art PESQ score of 3.69.
5/13/2024
🤿
Mamba-360: Survey of State Space Models as Transformer Alternative for Long Sequence Modelling: Methods, Applications, and Challenges
Badri Narayana Patro, Vijay Srinivas Agneeswaran
0
0
Sequence modeling is a crucial area across various domains, including Natural Language Processing (NLP), speech recognition, time series forecasting, music generation, and bioinformatics. Recurrent Neural Networks (RNNs) and Long Short Term Memory Networks (LSTMs) have historically dominated sequence modeling tasks like Machine Translation, Named Entity Recognition (NER), etc. However, the advancement of transformers has led to a shift in this paradigm, given their superior performance. Yet, transformers suffer from $O(N^2)$ attention complexity and challenges in handling inductive bias. Several variations have been proposed to address these issues which use spectral networks or convolutions and have performed well on a range of tasks. However, they still have difficulty in dealing with long sequences. State Space Models(SSMs) have emerged as promising alternatives for sequence modeling paradigms in this context, especially with the advent of S4 and its variants, such as S4nd, Hippo, Hyena, Diagnol State Spaces (DSS), Gated State Spaces (GSS), Linear Recurrent Unit (LRU), Liquid-S4, Mamba, etc. In this survey, we categorize the foundational SSMs based on three paradigms namely, Gating architectures, Structural architectures, and Recurrent architectures. This survey also highlights diverse applications of SSMs across domains such as vision, video, audio, speech, language (especially long sequence modeling), medical (including genomics), chemical (like drug design), recommendation systems, and time series analysis, including tabular data. Moreover, we consolidate the performance of SSMs on benchmark datasets like Long Range Arena (LRA), WikiText, Glue, Pile, ImageNet, Kinetics-400, sstv2, as well as video datasets such as Breakfast, COIN, LVU, and various time series datasets. The project page for Mamba-360 work is available on this webpage.url{https://github.com/badripatro/mamba360}.
4/26/2024
📈
Mamba3D: Enhancing Local Features for 3D Point Cloud Analysis via State Space Model
Xu Han, Yuan Tang, Zhaoxuan Wang, Xianzhi Li
0
0
Existing Transformer-based models for point cloud analysis suffer from quadratic complexity, leading to compromised point cloud resolution and information loss. In contrast, the newly proposed Mamba model, based on state space models (SSM), outperforms Transformer in multiple areas with only linear complexity. However, the straightforward adoption of Mamba does not achieve satisfactory performance on point cloud tasks. In this work, we present Mamba3D, a state space model tailored for point cloud learning to enhance local feature extraction, achieving superior performance, high efficiency, and scalability potential. Specifically, we propose a simple yet effective Local Norm Pooling (LNP) block to extract local geometric features. Additionally, to obtain better global features, we introduce a bidirectional SSM (bi-SSM) with both a token forward SSM and a novel backward SSM that operates on the feature channel. Extensive experimental results show that Mamba3D surpasses Transformer-based counterparts and concurrent works in multiple tasks, with or without pre-training. Notably, Mamba3D achieves multiple SoTA, including an overall accuracy of 92.6% (train from scratch) on the ScanObjectNN and 95.1% (with single-modal pre-training) on the ModelNet40 classification task, with only linear complexity.
4/24/2024