Spiking Wavelet Transformer

0

Sign in to get full access
Overview
- This paper introduces the Spiking Wavelet Transformer, a novel architecture that combines spiking neural networks and wavelet transforms for event-based vision tasks.
- The proposed model aims to leverage the energy-efficient and low-latency properties of spiking neural networks and the multi-scale representation capabilities of wavelet transforms.
- The architecture is evaluated on event-based vision benchmarks, demonstrating state-of-the-art performance and highlighting the potential of this approach for practical applications.
Plain English Explanation
The Spiking Wavelet Transformer is a new type of artificial neural network that combines two powerful techniques: spiking neural networks and wavelet transforms. Spiking neural networks are inspired by the way our brains work, using short electrical pulses (spikes) to transmit information. Wavelet transforms are a way of analyzing data at different scales, similar to how our eyes can focus on details or see the bigger picture.
By combining these ideas, the researchers have created a model that is both energy-efficient and can understand complex visual information. This is important for event-based vision tasks, where the goal is to quickly and accurately process visual data that is constantly changing, like in self-driving cars or robotics.
The key innovation of the Spiking Wavelet Transformer is its ability to extract features from the visual input at multiple scales, using the wavelet transform, and then process those features efficiently using spiking neural networks. This allows the model to capture both the fine details and the overall structure of the scene, which is crucial for making accurate decisions in real-time applications.
The researchers show that their model outperforms other state-of-the-art approaches on several event-based vision benchmarks, demonstrating the potential of this new architecture for practical use in areas like autonomous vehicles, robotics, and surveillance.
Technical Explanation
The Spiking Wavelet Transformer combines the advantages of spiking neural networks and wavelet transforms for event-based vision tasks. Spiking neural networks [link to section 2.1] are a biologically-inspired approach to deep learning that uses spike-based (discrete-time) signaling, which is more energy-efficient and closer to how the human brain processes information compared to traditional artificial neural networks.
Wavelet transforms [link to section 2.2] are a powerful tool for multi-scale analysis of signals, allowing the extraction of features at different resolutions. By integrating wavelet transforms into a spiking neural network architecture, the Spiking Wavelet Transformer can learn a hierarchical, multi-scale representation of the input event-based visual data.
The key components of the Spiking Wavelet Transformer [link to section 3] include:
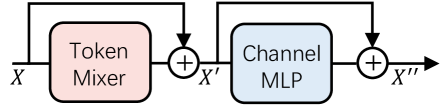
- Spiking Wavelet Encoder: This module applies a wavelet transform to the input event-based data, generating a multi-scale representation that is then fed into the spiking neural network.
- Spiking Neural Network Backbone: The spiking neural network backbone processes the wavelet-encoded features, learning efficient representations for the given task.
- Transformer Decoder: This transformer-based decoder module aggregates the multi-scale features from the spiking neural network backbone and produces the final output.
The researchers evaluate the Spiking Wavelet Transformer on several event-based vision benchmarks [link to section 4], including object recognition, object tracking, and visual-inertial odometry tasks. The results demonstrate that the proposed architecture outperforms other state-of-the-art approaches, highlighting the benefits of combining spiking neural networks and wavelet transforms for efficient and high-performance event-based vision.
Critical Analysis
The paper presents a well-designed and comprehensive study on the Spiking Wavelet Transformer, with a thorough evaluation on a variety of event-based vision tasks. The authors provide a clear explanation of the model architecture and its key components, as well as the rationale for combining spiking neural networks and wavelet transforms.
One potential limitation of the research is the reliance on the specific event-based vision datasets used for evaluation. While the authors demonstrate state-of-the-art performance on these benchmarks, it would be valuable to further assess the generalization capabilities of the Spiking Wavelet Transformer on a broader range of event-based vision applications.
Additionally, the paper could have delved deeper into the interpretability and explainability of the model's internal representations and decision-making processes. Understanding how the multi-scale wavelet features and spiking neural network computations interact to produce the final outputs could provide valuable insights for further improving the model's performance and reliability.
Overall, the Spiking Wavelet Transformer represents an exciting and promising direction in the field of event-based vision, leveraging the strengths of both spiking neural networks and wavelet transforms. Future research could explore ways to further optimize the model's energy efficiency and latency, as well as its robustness to noisy or challenging event-based data.
Conclusion
The Spiking Wavelet Transformer introduced in this paper represents a novel and innovative approach to event-based vision tasks. By combining the energy-efficient and low-latency properties of spiking neural networks with the multi-scale representation capabilities of wavelet transforms, the proposed architecture demonstrates state-of-the-art performance on a range of benchmarks.
The successful integration of these two powerful techniques highlights the potential for cross-pollination between different fields of deep learning and neuromorphic computing. As event-based vision continues to grow in importance for applications like autonomous vehicles, robotics, and surveillance, the Spiking Wavelet Transformer offers a promising solution that could significantly impact the development of efficient and high-performance systems for real-world deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Spiking Wavelet Transformer
Yuetong Fang, Ziqing Wang, Lingfeng Zhang, Jiahang Cao, Honglei Chen, Renjing Xu
Spiking neural networks (SNNs) offer an energy-efficient alternative to conventional deep learning by emulating the event-driven processing manner of the brain. Incorporating Transformers with SNNs has shown promise for accuracy. However, they struggle to learn high-frequency patterns, such as moving edges and pixel-level brightness changes, because they rely on the global self-attention mechanism. Learning these high-frequency representations is challenging but essential for SNN-based event-driven vision. To address this issue, we propose the Spiking Wavelet Transformer (SWformer), an attention-free architecture that effectively learns comprehensive spatial-frequency features in a spike-driven manner by leveraging the sparse wavelet transform. The critical component is a Frequency-Aware Token Mixer (FATM) with three branches: 1) spiking wavelet learner for spatial-frequency domain learning, 2) convolution-based learner for spatial feature extraction, and 3) spiking pointwise convolution for cross-channel information aggregation - with negative spike dynamics incorporated in 1) to enhance frequency representation. The FATM enables the SWformer to outperform vanilla Spiking Transformers in capturing high-frequency visual components, as evidenced by our empirical results. Experiments on both static and neuromorphic datasets demonstrate SWformer's effectiveness in capturing spatial-frequency patterns in a multiplication-free and event-driven fashion, outperforming state-of-the-art SNNs. SWformer achieves a 22.03% reduction in parameter count, and a 2.52% performance improvement on the ImageNet dataset compared to vanilla Spiking Transformers. The code is available at: https://github.com/bic-L/Spiking-Wavelet-Transformer.
Read more9/5/2024

0
Spiking Tucker Fusion Transformer for Audio-Visual Zero-Shot Learning
Wenrui Li, Penghong Wang, Ruiqin Xiong, Xiaopeng Fan
The spiking neural networks (SNNs) that efficiently encode temporal sequences have shown great potential in extracting audio-visual joint feature representations. However, coupling SNNs (binary spike sequences) with transformers (float-point sequences) to jointly explore the temporal-semantic information still facing challenges. In this paper, we introduce a novel Spiking Tucker Fusion Transformer (STFT) for audio-visual zero-shot learning (ZSL). The STFT leverage the temporal and semantic information from different time steps to generate robust representations. The time-step factor (TSF) is introduced to dynamically synthesis the subsequent inference information. To guide the formation of input membrane potentials and reduce the spike noise, we propose a global-local pooling (GLP) which combines the max and average pooling operations. Furthermore, the thresholds of the spiking neurons are dynamically adjusted based on semantic and temporal cues. Integrating the temporal and semantic information extracted by SNNs and Transformers are difficult due to the increased number of parameters in a straightforward bilinear model. To address this, we introduce a temporal-semantic Tucker fusion module, which achieves multi-scale fusion of SNN and Transformer outputs while maintaining full second-order interactions. Our experimental results demonstrate the effectiveness of the proposed approach in achieving state-of-the-art performance in three benchmark datasets. The harmonic mean (HM) improvement of VGGSound, UCF101 and ActivityNet are around 15.4%, 3.9%, and 14.9%, respectively.
Read more7/12/2024
0
Spike-driven Transformer V2: Meta Spiking Neural Network Architecture Inspiring the Design of Next-generation Neuromorphic Chips
Man Yao, Jiakui Hu, Tianxiang Hu, Yifan Xu, Zhaokun Zhou, Yonghong Tian, Bo Xu, Guoqi Li
Neuromorphic computing, which exploits Spiking Neural Networks (SNNs) on neuromorphic chips, is a promising energy-efficient alternative to traditional AI. CNN-based SNNs are the current mainstream of neuromorphic computing. By contrast, no neuromorphic chips are designed especially for Transformer-based SNNs, which have just emerged, and their performance is only on par with CNN-based SNNs, offering no distinct advantage. In this work, we propose a general Transformer-based SNN architecture, termed as ``Meta-SpikeFormer, whose goals are: 1) Lower-power, supports the spike-driven paradigm that there is only sparse addition in the network; 2) Versatility, handles various vision tasks; 3) High-performance, shows overwhelming performance advantages over CNN-based SNNs; 4) Meta-architecture, provides inspiration for future next-generation Transformer-based neuromorphic chip designs. Specifically, we extend the Spike-driven Transformer in citet{yao2023spike} into a meta architecture, and explore the impact of structure, spike-driven self-attention, and skip connection on its performance. On ImageNet-1K, Meta-SpikeFormer achieves 80.0% top-1 accuracy (55M), surpassing the current state-of-the-art (SOTA) SNN baselines (66M) by 3.7%. This is the first direct training SNN backbone that can simultaneously supports classification, detection, and segmentation, obtaining SOTA results in SNNs. Finally, we discuss the inspiration of the meta SNN architecture for neuromorphic chip design. Source code and models are available at url{https://github.com/BICLab/Spike-Driven-Transformer-V2}.
Read more4/8/2024

0
SDformerFlow: Spatiotemporal swin spikeformer for event-based optical flow estimation
Yi Tian, Juan Andrade-Cetto
Event cameras generate asynchronous and sparse event streams capturing changes in light intensity. They offer significant advantages over conventional frame-based cameras, such as a higher dynamic range and an extremely faster data rate, making them particularly useful in scenarios involving fast motion or challenging lighting conditions. Spiking neural networks (SNNs) share similar asynchronous and sparse characteristics and are well-suited for processing data from event cameras. Inspired by the potential of transformers and spike-driven transformers (spikeformers) in other computer vision tasks, we propose two solutions for fast and robust optical flow estimation for event cameras: STTFlowNet and SDformerFlow. STTFlowNet adopts a U-shaped artificial neural network (ANN) architecture with spatiotemporal shifted window self-attention (swin) transformer encoders, while SDformerFlow presents its fully spiking counterpart, incorporating swin spikeformer encoders. Furthermore, we present two variants of the spiking version with different neuron models. Our work is the first to make use of spikeformers for dense optical flow estimation. We conduct end-to-end training for all models using supervised learning. Our results yield state-of-the-art performance among SNN-based event optical flow methods on both the DSEC and MVSEC datasets, and show significant reduction in power consumption compared to the equivalent ANNs.
Read more9/9/2024